Proxmox VE
- Einführung Vorwort
- Proxmox - Backup Server (PBS)
- Proxmox Backupserver Logs älter als 90 Tage löschen
- Proxmox KVM / CT Restore via Terminal
- Proxmox Backup Fehler behebung
- Proxmox installation auf Debian (Optional mit Verschlüsselung)
- Installation Debian 11 Bullseye (Grundeinstellungen Sprache Benutzerkonten)
- Installation Debian 11 Bullseye (Installation mit Verschlüsselung)
- Einloggen per SSH Preauthentication ,damit Kennwort nicht per VNC eingeben weden muss
- Die eigentliche Proxmox installation
- Proxmox - Installation eines arm64 VM Gastest
- Vorbereiten der VM
- Installation des Betriebssystems
- System Starten und startbar machen
- System als Template anlegen (Optional)
- Proxmox - Benutzerverwaltung
- Proxmox - Hardware durchreichen in VM (KVM)
- Proxmox - Tools / BUG Fixes Workarounds / Tipps und Tricks
- Proxmox 7 - Deutsche Windows ISO nach installation keine Netzwerkkarten nur Ausrufungszeichen
- Proxmox/Debian bei älteren Monitoren - Out of Range
- Proxmox ZFS Offline Mount mit PVE Install DVD/STICK
- LXC Conatiner startet nach Installation einer Software die als Dienst startet nicht mehr. (AppArmor)
- Proxmox Wartungsmodus / Maintenance Mode - Diasable / Enable VMS at Start
- Proxmox Host aus VM herunterfahren
- Proxmox - Es lassen sich keine Snapshots anlegen
- Proxmox 7 installation hängt bei 99% make system bootable
- Anlegen / Clonen einer ARM64 VM Fehler
- LXC Conatiner - Routen beim start setzten,da post in interfaces nicht geht
- Ceph Upgrade von Pacific 17.2.7 auf reef 18.2.2 osd starten nicht
- Cpeh crash log löschen
- HDD Tray ermitteln LED blinken und/oder austauschen
- Proxmox - Lets Encrypt Zertifikat
- Einrichtung Lets Encrypt Zertifikat über Port 80 und im Terminal
- Proxmox Lets Encyrpt Zertifikat über Webgui und DNS Challenge
- Proxmox . Nested Virtualisierung
- Proxmox - Import VirtualBoxAppliance
- Proxmox - LVM in VM vergrößern
- Proxmox - Qemu Agent installation
- Proxmox - Ceph
- Crushmap dekompilieren / kompilieren
- Pools nach Classen anlegen (SSD Pool / HDD Pool)
- Nach löschen eines Ceph Monitors bleibt immer noch der eintrag über
- Nach entfernen eines Hosts bleibt in der Chrush Map der leere eintrag übrig
- Proxmox - Migrationen
- Proxmox VMDK oder img in VM importieren
- VM im LVM/ qcow2 format auf anderen Host in ein RBD migrieren ohne zwischenspeicher via SSH
- VM vom RBD auf anderen Host in ein RBD migrieren ohne zwischenspeicher via SSH
- P2V - Laufenden Windows per SSH in Proxmox rbd import
- P2V - Festplatte direkt am Host angeschlossen in Proxmox rbd import
- Cluster Netzwerk wechseln
- Proxmox - erweiterte Netzwerkeinstellungen
- Proxmox - Upgrade Fehler
- VDI mit Spice
Einführung Vorwort
Virtualisierung / Hyperkonvergenz
Hyperkonvergenz ist ein IT-Framework, das Storage, Computing und Networking in einem einzigen System kombiniert und so eine geringere Rechenzentrumskomplexität und höhere Skalierbarkeit garantiert. Eine Hyperconverged-Plattform umfasst einen Hypervisor für virtualisiertes Computing, Software-Defined Storage und Netzwerkvirtualisierung.
Definition von Hyperkonvergenz
Hyperkonvergenz ist eine softwarezentrierte Architektur, die Computing-, Storage- und Virtualisierungsressourcen nahtlos in einem einzigen System integriert – im Rahmen einer x86-basierten Appliance oder als Software, die sich auf der bestehenden Hardware installieren lässt.
Verwandte Themen
Rechenzentrumsbetrieb
Lösungen für Rechenzentren
Storage Area Network
Wie funktioniert Hyperkonvergenz?
Mit Hyperkonvergenz werden alle kritischen Rechenzentrumsfunktionen auf einem nahtlos integrierten Software-Layer statt auf speziell entwickelter Hardware ausgeführt. Hyperconverged-Plattformen bestehen aus drei Softwarekomponenten: Computing-Virtualisierung, Storage-Virtualisierung und Management. Die Virtualisierungssoftware abstrahiert die zugrunde liegenden Ressourcen, fasst sie in Pools zusammen und weist sie dann dynamisch in VMs oder Containern ausgeführten Anwendungen zu.
Das ganze ist mit Proxmox VE zu realisieren.
Proxmox - Backup Server (PBS)
Proxmox Backupserver Logs älter als 90 Tage löschen
Da es kein Logrotate gibt, wird die festplatte über kurz über lang vollaufen, da alte logs nicht gelöscht werden.
zum einmaligen ausführen
find /var/log/proxmox-backup/tasks -type f -name 'UPID*' -mtime +90 -deleteCronjob erstellen
Eine neue Datei im /etc/cron.d Ordner anlegen
nano /etc/cron.d/deletepbslogund folgenden Inhalt einfügen.
0 0 * * * find /var/log/proxmox-backup/tasks -type f -name 'UPID*' -mtime +90 -delete >/dev/null 2>&1
Proxmox KVM / CT Restore via Terminal
dir: local
path /var/lib/vz
content vztmpl,backup,iso
prune-backups keep-last=1
shared 0
zfspool: local-zfs
pool rpool/data
content rootdir,images
sparse 1
cephfs: cephfs
path /mnt/pve/cephfs
content iso,vztmpl,backup
pbs: backup
datastore backup
server <ip_from_pbs_server>
content backup
fingerprint *******************************************
prune-backups keep-all=1
username root@pam
Beschreibung
Eigentlich gehört das ja unter den Proxmox Server selbst. Da es aber hier explizit um den Restore von einem PBS Speicher geht.
Dachte ich schreib cih das hier rein.
Ermitteln des PBS Speicher namens
Mittels den Befehl
cat /etc/pve/storage.cfgAusgabe:
dir: local
path /var/lib/vz
content vztmpl,backup,iso
prune-backups keep-last=1
shared 0
zfspool: local-zfs
pool rpool/data
content rootdir,images
sparse 1
cephfs: cephfs
path /mnt/pve/cephfs
content iso,vztmpl,backup
pbs: backup
datastore backup
server <pbs_server_ip>
content backup
fingerprint ***************************************
prune-backups keep-all=1
username root@pam
Nun sehen wir, das unser PBD Store hier backup heißt.
Auflisten der Backups
Da wir jetzt wissen, wie unser Backupstore heißt , lassen wir uns alle Backups Auflisten, damit wir wissen welches wir haben wollen.
Befehl:
pvesm list <pbsname>
Beispiel
pvesm list backupAusgabe:
Volid Format Type Size VMID
backup:backup/ct/104/2021-08-16T04:26:02Z pbs-ct backup 2479283013 104
backup:backup/ct/104/2021-08-16T06:21:03Z pbs-ct backup 2479207164 104
backup:backup/ct/107/2021-12-25T23:04:12Z pbs-ct backup 673609752 107
backup:backup/ct/107/2022-06-25T22:09:42Z pbs-ct backup 673182555 107
backup:backup/ct/107/2022-07-30T22:47:38Z pbs-ct backup 672557354 107
backup:backup/ct/107/2022-08-27T22:15:19Z pbs-ct backup 672595329 107
backup:backup/ct/107/2022-09-24T22:12:42Z pbs-ct backup 672370901 107
backup:backup/ct/107/2022-10-01T22:08:55Z pbs-ct backup 672927418 107
ackup:backup/vm/139/2023-01-01T00:36:43Z pbs-vm backup 8624294872084 139
backup:backup/vm/139/2023-01-02T00:51:24Z pbs-vm backup 8624294872086 139
backup:backup/vm/139/2023-01-03T00:47:49Z pbs-vm backup 8624294872086 139
backup:backup/vm/139/2023-01-04T00:44:20Z pbs-vm backup 8624294872085 139
backup:backup/vm/139/2023-01-05T00:35:17Z pbs-vm backup 8624294872084 139
backup:backup/vm/139/2023-01-06T00:53:37Z pbs-vm backup 8624294872088 139
backup:backup/vm/139/2023-01-07T00:33:51Z pbs-vm backup 8624294872085 139
backup:backup/vm/139/2023-01-08T00:45:41Z pbs-vm backup 8624294872087 139
backup:backup/vm/139/2023-01-09T00:34:17Z pbs-vm backup 8624294872089 139
backup:backup/vm/139/2023-01-10T00:23:08Z pbs-vm backup 8624294872085 139
backup:backup/vm/139/2023-01-11T00:39:43Z pbs-vm backup 8624294872085 139
backup:backup/vm/139/2023-01-12T00:29:20Z pbs-vm backup 8624294872086 139
backup:backup/vm/139/2023-01-13T00:29:04Z pbs-vm backup 8624294872087 139
backup:backup/vm/139/2023-01-14T00:22:10Z pbs-vm backup 8624294872086 139
backup:backup/vm/139/2023-01-15T00:25:47Z pbs-vm backup 8624294872085 139
So eine Liste kann auch lang werden.
Sonst diese einfach nur durch grep mit der vmid schieben z.b /221 für die VM 221.
Wir machen ein slash davor, falls die 139 in irgendeinem hash auftauchen sollte, diese nicht mit ausgegeben wird
pvesm list backup | grep /221Ausgabe
backup:backup/vm/221/2021-12-25T23:00:02Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-04-23T22:00:02Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-05-28T22:00:03Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-06-24T22:00:02Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-07-30T22:00:03Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-08-06T22:00:10Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-08-13T22:00:05Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-08-19T22:00:04Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-08-27T22:00:06Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-08-28T22:00:02Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-08-30T22:00:02Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-08-31T22:00:07Z pbs-vm backup 108447925034 221
backup:backup/vm/221/2022-09-01T22:00:02Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-04T22:00:01Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-05T22:00:08Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-09-06T22:00:04Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-08T22:00:01Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-09-09T22:00:05Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-11T22:00:05Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-09-14T22:00:04Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-15T22:00:03Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-09-16T22:00:07Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-09-17T22:00:01Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-18T22:00:05Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-23T22:00:03Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-24T22:00:02Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-09-26T22:00:03Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-09-29T22:00:03Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2022-09-30T22:00:12Z pbs-vm backup 108447925032 221
backup:backup/vm/221/2022-10-01T22:00:06Z pbs-vm backup 108447925034 221
backup:backup/vm/221/2022-10-02T22:00:07Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-10-03T22:00:06Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-10-05T22:00:02Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-10-07T22:00:04Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-10-08T22:00:06Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-10-10T22:00:03Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-10-11T22:00:02Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-10-13T22:00:01Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-10-14T22:00:01Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-10-16T22:00:11Z pbs-vm backup 108447925041 221
backup:backup/vm/221/2022-10-17T22:00:04Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-10-18T22:00:03Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-10-19T22:00:05Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-10-21T22:00:02Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-10-23T22:00:02Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-10-24T22:00:03Z pbs-vm backup 108447925034 221
backup:backup/vm/221/2022-10-25T22:00:01Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-10-26T22:00:03Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-10-27T22:00:01Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-10-28T22:00:02Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-10-29T22:00:00Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-10-30T23:00:03Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-11-01T23:00:06Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-11-02T23:00:04Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-11-03T23:00:02Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-11-04T23:00:03Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-11-06T23:00:05Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-11-08T23:00:01Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2022-11-09T23:00:01Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2022-11-10T23:00:01Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-11-13T23:00:03Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-11-19T23:00:02Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-11-20T23:00:05Z pbs-vm backup 108447925027 221
backup:backup/vm/221/2022-11-22T23:00:02Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-11-23T23:00:00Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-11-24T23:00:02Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-11-25T23:00:00Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2022-11-26T23:00:03Z pbs-vm backup 108447925034 221
backup:backup/vm/221/2022-11-29T23:00:09Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2022-11-30T23:00:05Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-12-04T23:00:00Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2022-12-06T23:00:04Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-12-07T23:00:01Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-12-09T23:00:04Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-12-10T23:00:06Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2022-12-17T23:00:04Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2022-12-18T23:00:01Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2022-12-19T23:00:04Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-12-20T23:00:01Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-12-21T23:00:05Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-12-24T23:00:06Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-12-25T23:00:01Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2022-12-26T23:00:01Z pbs-vm backup 108447925034 221
backup:backup/vm/221/2022-12-27T23:00:01Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2022-12-29T23:00:00Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-12-30T23:00:01Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2022-12-31T23:00:03Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2023-01-02T23:00:05Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-01-03T23:00:02Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-01-04T23:00:04Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2023-01-08T23:00:01Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2023-01-10T23:00:04Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2023-01-11T23:00:02Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2023-01-13T23:00:06Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-01-14T23:00:00Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2023-01-15T23:00:03Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2023-01-17T23:00:01Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2023-01-18T23:00:03Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-01-19T23:00:02Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-01-20T23:00:05Z pbs-vm backup 108447925035 221
backup:backup/vm/221/2023-01-21T23:00:03Z pbs-vm backup 108447925033 221
backup:backup/vm/221/2023-01-22T23:00:04Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-01-23T23:00:02Z pbs-vm backup 108447925037 221
backup:backup/vm/221/2023-01-26T23:00:04Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-01-29T23:00:03Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2023-01-31T23:00:03Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2023-02-02T23:00:02Z pbs-vm backup 108447925036 221
backup:backup/vm/221/2023-02-05T23:00:05Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2023-02-06T23:00:01Z pbs-vm backup 108447925040 221
backup:backup/vm/221/2023-02-08T23:00:01Z pbs-vm backup 108447925038 221
backup:backup/vm/221/2023-02-09T23:00:03Z pbs-vm backup 108447925039 221
backup:backup/vm/221/2023-02-11T12:51:38Z pbs-vm backup 108447924970 221Nun suchen wir das Backup raus was wir haben wollen. Ich möchte das aktuellste Backup also das letzte haben.
Die letzte zeile. Aber es kann auch sein das ein älteres Backup gewünscht ist einfach die Zeile des gewünschten backups nehmen. Dort brauchen wir dann für den nächsten Befehl aus der gewünschten zeile die Volid
Meine gewünschte Zeile ist hier die letze
backup:backup/vm/221/2023-02-11T12:51:38Z pbs-vm backup 108447924970 221Nun nur noch zurück sichern, wenn das Backup von einem PBS kommt kann man auch noch live restore wählen, beuedet die maschine ist schon nutzbar während des restore
qmrestore <volumeid> <neue_vmid_in_die_zurück_gesichert_werden_soll> --storage <store_in_den_das_image_zurückgesichert_soll>
Beispiel Volumeid, meinspeicherpool rbd, neue vmid bei mir
qmrestore backup:backup/vm/221/2023-02-11T12:51:38Z 147 --storage rbd
Optional mit live restore
qmrestore backup:backup/vm/221/2023-02-11T12:51:38Z 147 --storage rbd --live-restore trueAusgabe:
restore-drive-scsi0: transferred 0.0 B of 32.0 GiB (0.00%) in 0s
restore-drive-scsi0: transferred 188.0 MiB of 32.0 GiB (0.57%) in 1s
restore-drive-scsi0: transferred 372.0 MiB of 32.0 GiB (1.14%) in 2s
restore-drive-scsi0: transferred 572.0 MiB of 32.0 GiB (1.75%) in 3s
restore-drive-scsi0: transferred 752.0 MiB of 32.0 GiB (2.29%) in 4s
restore-drive-scsi0: transferred 824.0 MiB of 32.0 GiB (2.51%) in 5s
restore-drive-scsi0: transferred 1000.0 MiB of 32.0 GiB (3.05%) in 6s
restore-drive-scsi0: transferred 1.1 GiB of 32.0 GiB (3.58%) in 7s
restore-drive-scsi0: transferred 1.3 GiB of 32.0 GiB (4.14%) in 8s
restore-drive-scsi0: transferred 1.5 GiB of 32.0 GiB (4.61%) in 9s
restore-drive-scsi0: transferred 1.6 GiB of 32.0 GiB (5.14%) in 10s
restore-drive-scsi0: transferred 1.8 GiB of 32.0 GiB (5.65%) in 11s
restore-drive-scsi0: transferred 2.0 GiB of 32.0 GiB (6.20%) in 12s
restore-drive-scsi0: transferred 2.1 GiB of 32.0 GiB (6.71%) in 13s
restore-drive-scsi0: transferred 2.4 GiB of 32.0 GiB (7.46%) in 14s
restore-drive-scsi0: transferred 2.6 GiB of 32.0 GiB (8.25%) in 15s
restore-drive-scsi0: transferred 2.7 GiB of 32.0 GiB (8.41%) in 16s
restore-drive-scsi0: transferred 2.9 GiB of 32.0 GiB (8.97%) in 17s
restore-drive-scsi0: transferred 3.1 GiB of 32.0 GiB (9.58%) in 18s
restore-drive-scsi0: transferred 3.2 GiB of 32.0 GiB (10.16%) in 19s
restore-drive-scsi0: transferred 3.3 GiB of 32.0 GiB (10.38%) in 20s
restore-drive-scsi0: transferred 3.4 GiB of 32.0 GiB (10.50%) in 21s
...
restore-drive-scsi0: transferred 31.3 GiB of 32.0 GiB (97.89%) in 4m 3s
restore-drive-scsi0: transferred 31.5 GiB of 32.0 GiB (98.58%) in 4m 4s
restore-drive-scsi0: transferred 31.7 GiB of 32.0 GiB (99.17%) in 4m 5s
restore-drive-scsi0: transferred 31.9 GiB of 32.0 GiB (99.72%) in 4m 6s
restore-drive-scsi0: stream-job finished
restore-drive jobs finished successfully, removing all tracking block devices to disconnect from Proxmox Backup Server
Proxmox Backup Fehler behebung
Beschreibung:
Liste von Backupfehler und eventuelle Lösung dazu
Fehler:
ERROR: Backup of VM 137 failed - VM 137 qmp command 'backup' failed - backup connect failed: command error: not a valid user id
Der Fehler im ganzen Backup Task log.
()
INFO: starting new backup job: vzdump 137 --remove 0 --mode snapshot --node vserv0007 --notes-template '{{guestname}}' --storage backup
INFO: Starting Backup of VM 137 (qemu)
INFO: Backup started at 2023-12-16 11:16:55
INFO: status = running
INFO: VM Name: budibase
INFO: include disk 'scsi0' 'data:vm-137-disk-0' 32G
INFO: backup mode: snapshot
INFO: ionice priority: 7
INFO: snapshots found (not included into backup)
INFO: creating Proxmox Backup Server archive 'vm/137/2023-12-16T10:16:55Z'
ERROR: VM 137 qmp command 'backup' failed - backup connect failed: command error: not a valid user id
INFO: aborting backup job
INFO: resuming VM again
ERROR: Backup of VM 137 failed - VM 137 qmp command 'backup' failed - backup connect failed: command error: not a valid user id
INFO: Failed at 2023-12-16 11:16:55
INFO: Backup job finished with errors
TASK ERROR: job errorsDie Datei die den Besitzer angibt, ist aus unerklärlichen gründen leer.
Diese einfach löschen, bzw gleich das ganze Verzeichnis
Dazu auf dem Backupserver einloggen per ssh.
In das Verzeichnis des Datastore gehen und das VM Verzeichnis löschen:
Bei mir liegt das Datastore Verzeichnis unter
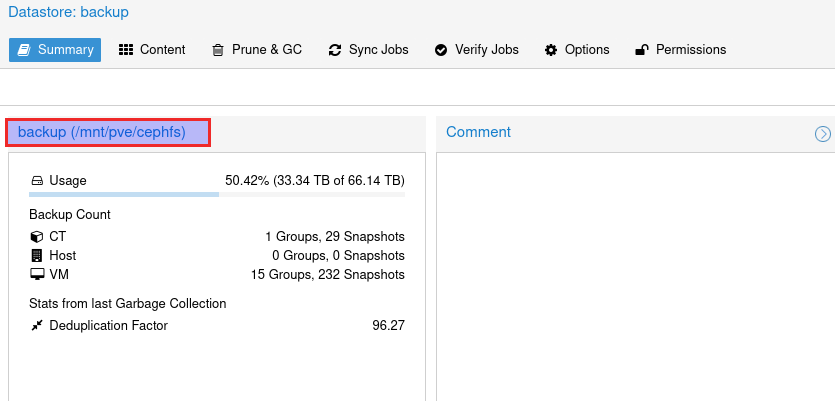
in das Verzeichnis gehen.
In diesem Verzeichnis gibt es ein Unterverzeichnsi vm, auch in dieses gehen.
cd /mnt/pve/cephfs/vmmit ls sieht man alle VM Verzeichniss die mal angelegt wurden.
Wenn wir in unter die vm id rein gehen (bei mir die 137) und ein ls durchführen sehen wir eine Datei namens owner mit der Größe von 0. und auch ein cat auf die Datei würde zeigen das da nichts drin ist.
Wie auch bei Größe 0
cd /mnt/pve/cephfs/vm/137
ls -l
Ausgabe:
/mnt/pve/cephfs/vm/137# ls -l
insgesamt 0
-rw-r--r-- 1 backup backup 0 27. Aug 21:06 owner
Ausgabe von einem anderen Verzeichnis bei VM 124 wie es aussehen müsste,
da sind auch noch zwei Backups mit drin, aber uns interessiert die owner Datei.
Da hat die Ownder Datei eine größe von 9 Byte
/mnt/pve/cephfs/vm/124# ls -l
insgesamt 1
drwxr-xr-x 2 backup backup 4 15. Dez 03:17 2023-12-15T01:56:57Z
drwxr-xr-x 2 backup backup 4 16. Dez 03:37 2023-12-16T01:30:05Z
-rw-r--r-- 1 backup backup 9 15. Dez 02:05 ownerNun das komplette Verzeichnis löschen. (Hier wieder die 137)
rm -Rf /mnt/pve/cephfs/vm/137/Nun von der SSH Sitzung wieder ausloggen.
Nun das Backup nochmals starten

Die Task Log Ausgabe:
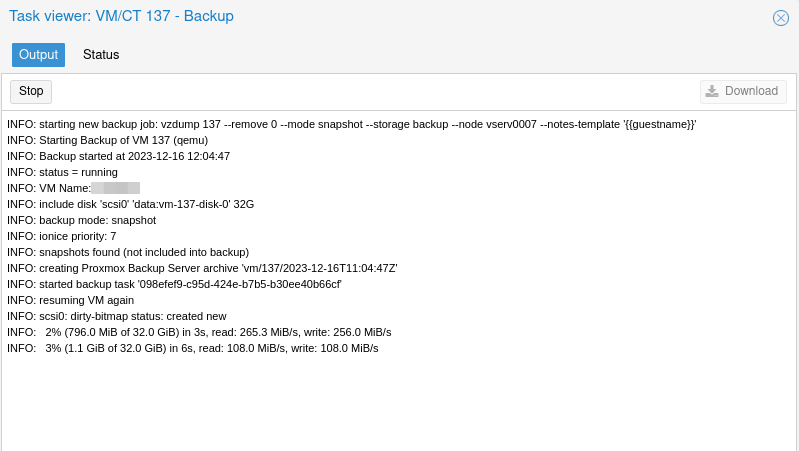
Er sichert wieder.
Fertig
Proxmox installation auf Debian (Optional mit Verschlüsselung)
Installation Debian 11 Bullseye (Grundeinstellungen Sprache Benutzerkonten)
- Installation Debian 11 Bullseye von der Debian Net install ISO Starten
https://www.debian.org/distrib/
wir wählen den Textbasierten installer - Installtion starten mit Install für Textmodus

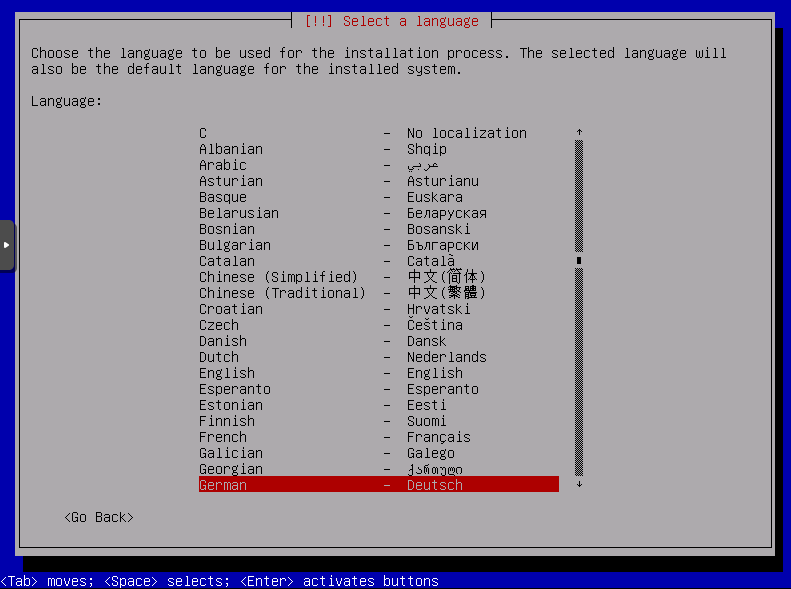
Sprache wählen, Ich bevorzuge Deutsch
Sprache auswählen, ich wähle hier Deutsch:
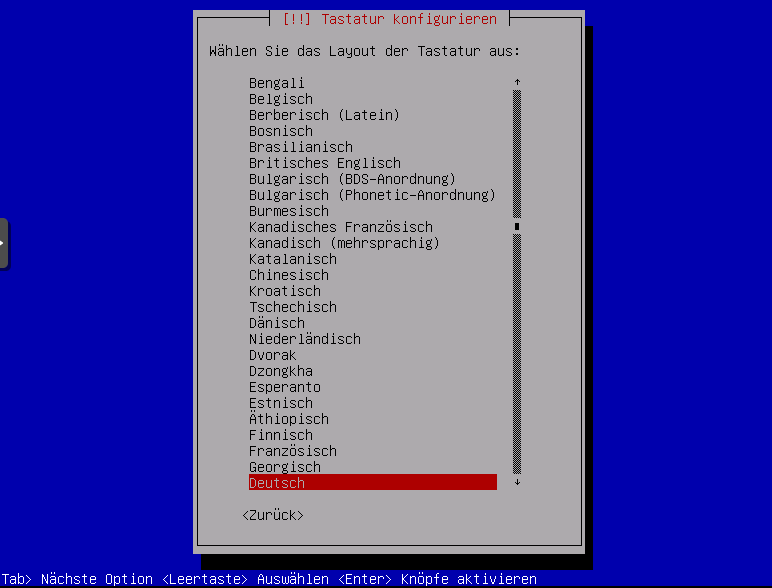
Tastatursprache wählen
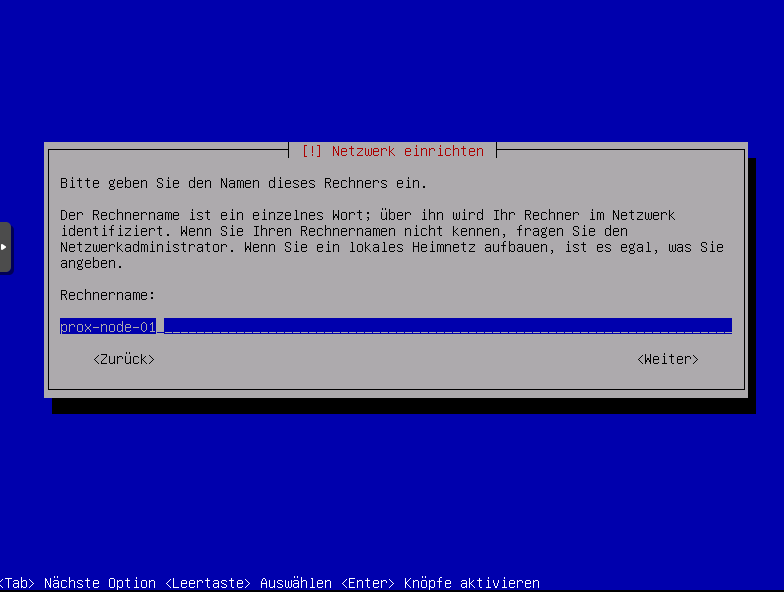
Rechner / Hostname vergeben
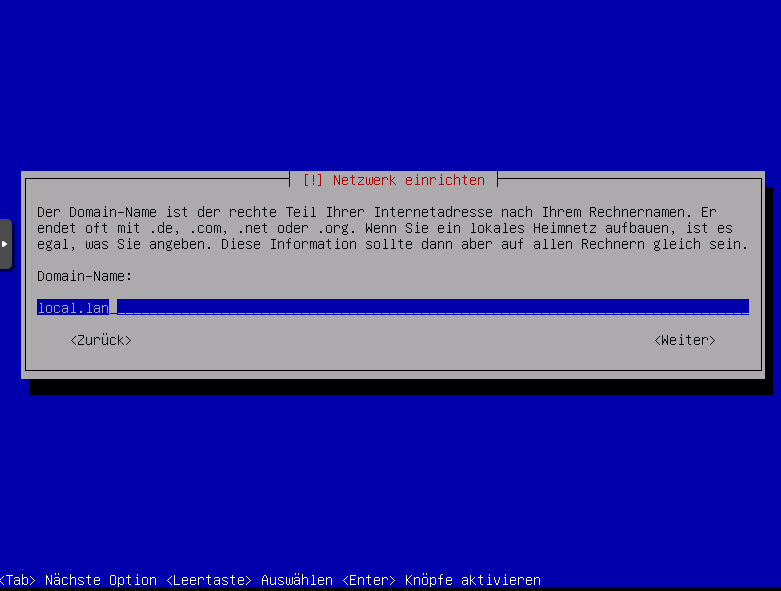
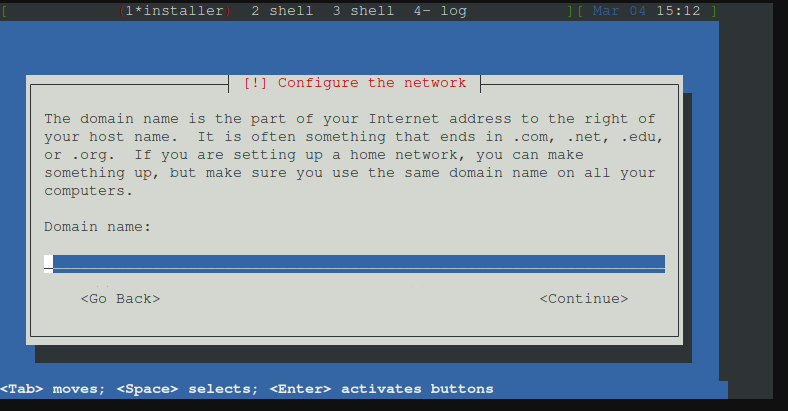
Domainnamen festlegen
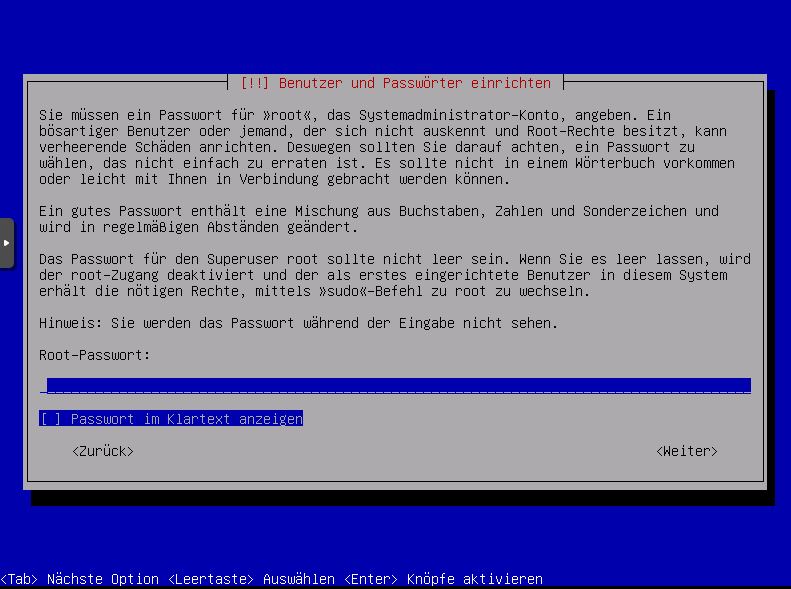
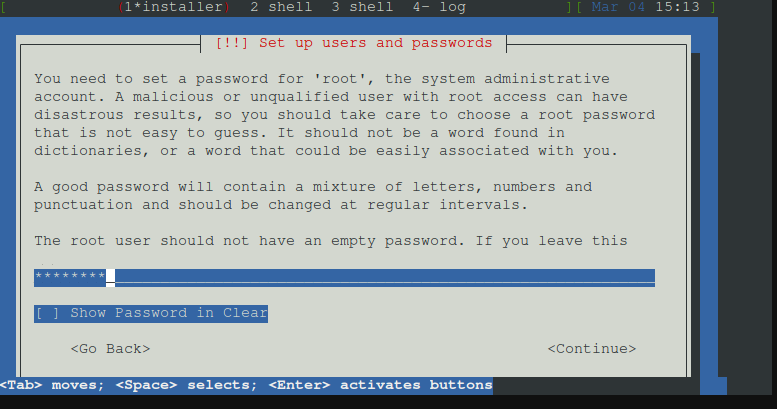
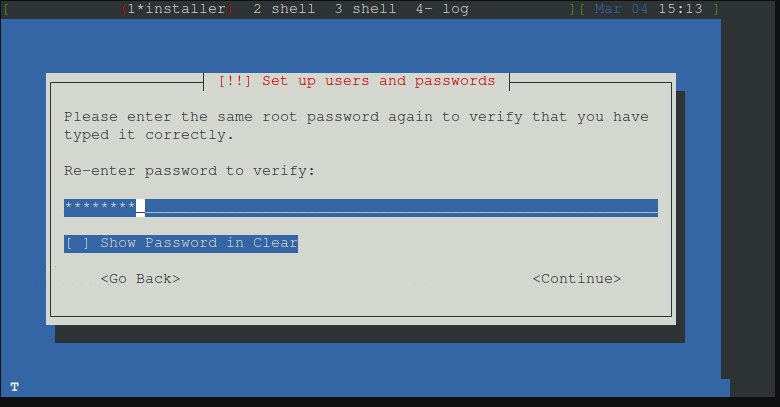
Root Passwort festlegen und wiederholen
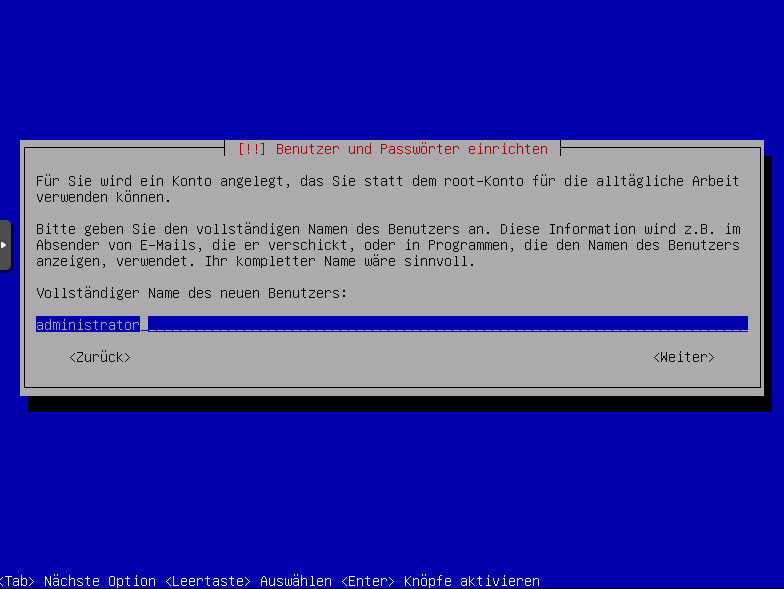
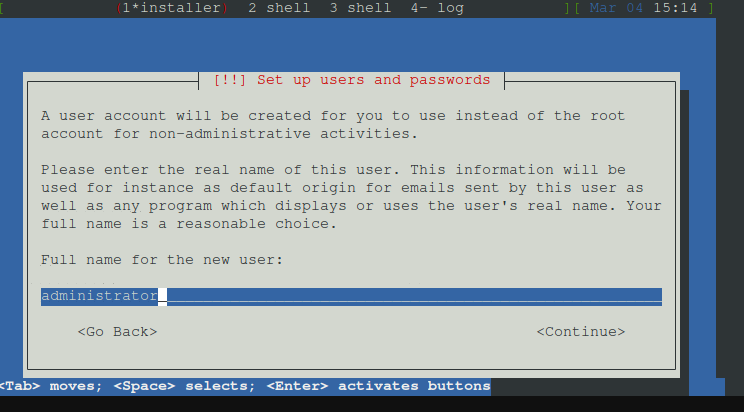
neuen Admin Benutzer erstellen z.b administrator
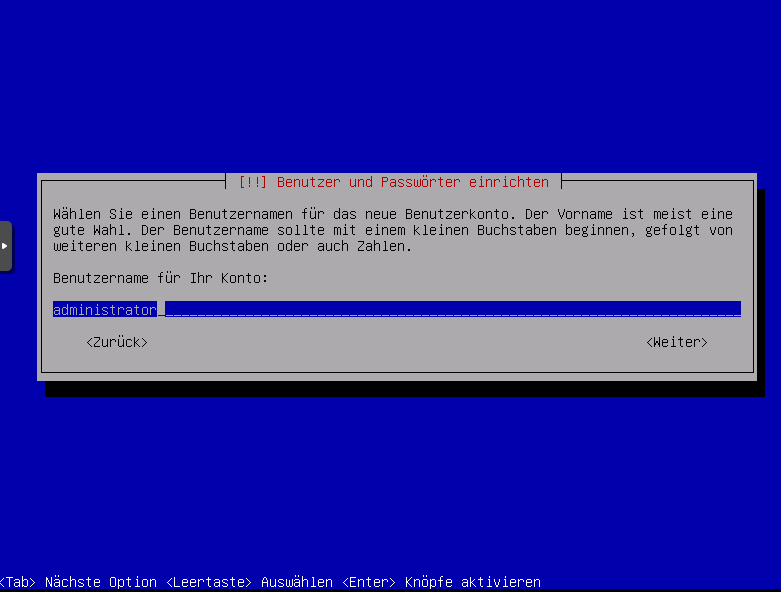
Benutzername angeben z.b administrator, wird auch vorgeschalgen
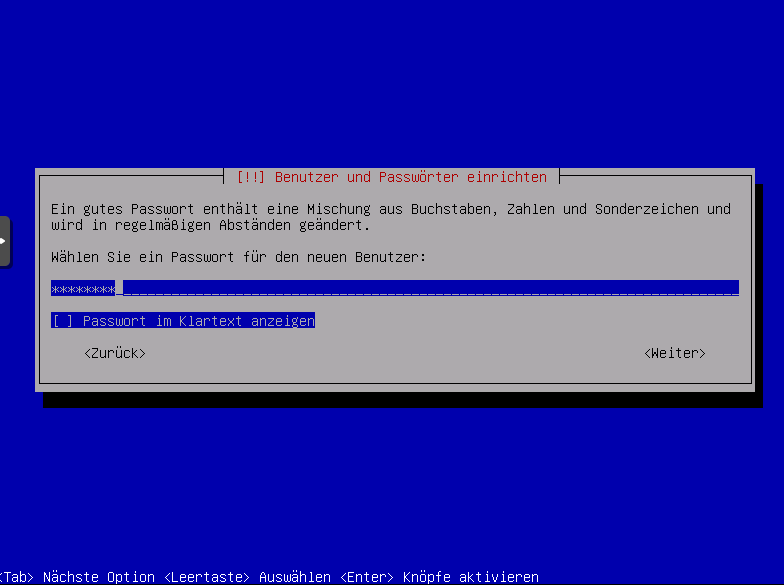
Passwort vergeben und wiederholen

Installation Debian 11 Bullseye (Installation mit Verschlüsselung)
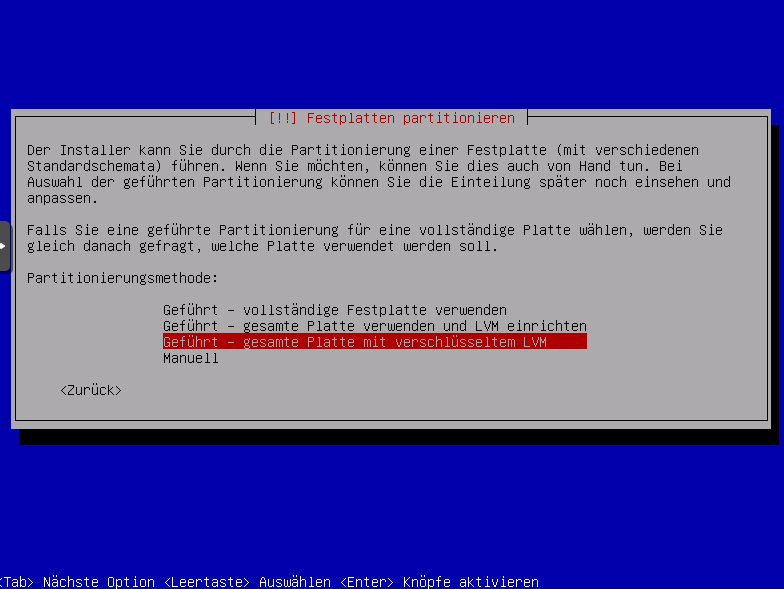
- Soll unverschlüsselt gewählt werden vollständige Festplatte verwenden oder manuell
Soll verschlüsselt werden, dann gesamte Platte mit verschlüsseltem LVM auswählen.
oder manuell wenn alles selbst ausgewählt werden soll.
Wir wählen hier:
Soll verschlüsselt werden, dann gesamte Platte mit verschlüsseltem LVM auswählen.
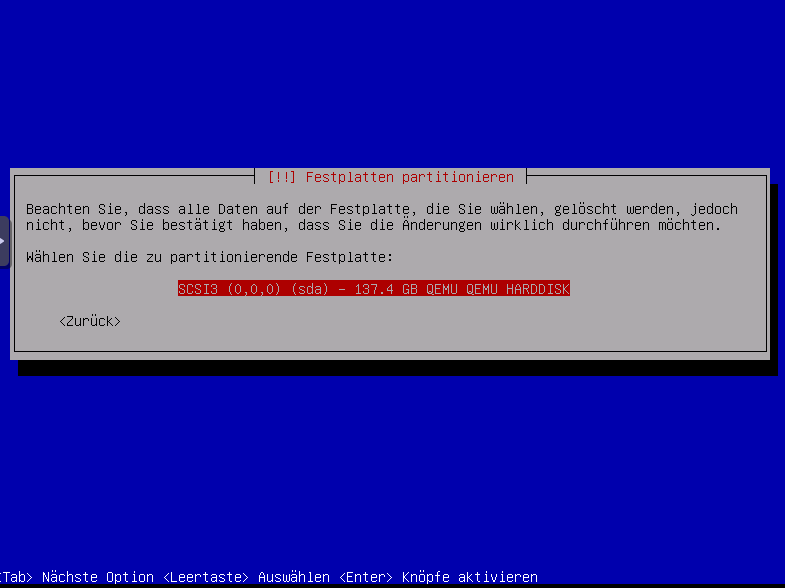
Festplatte auswählen
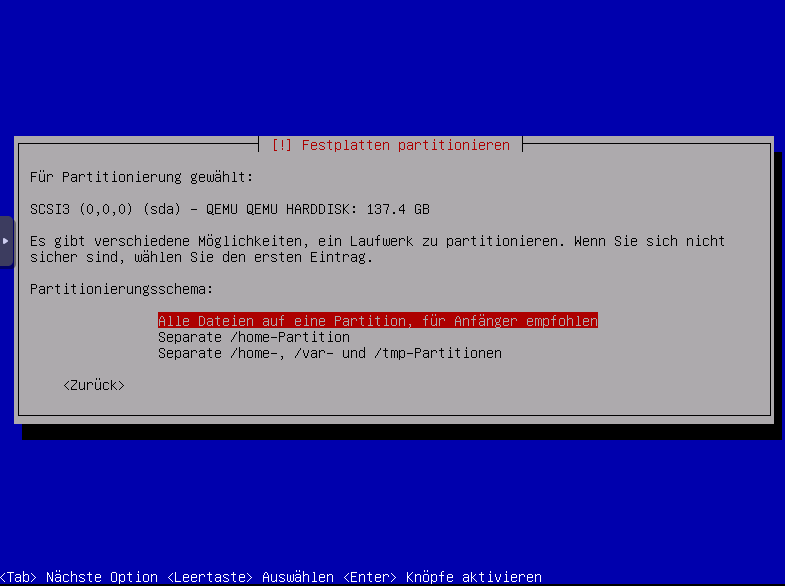
Alle Dateien auf eine Partition auswählen.
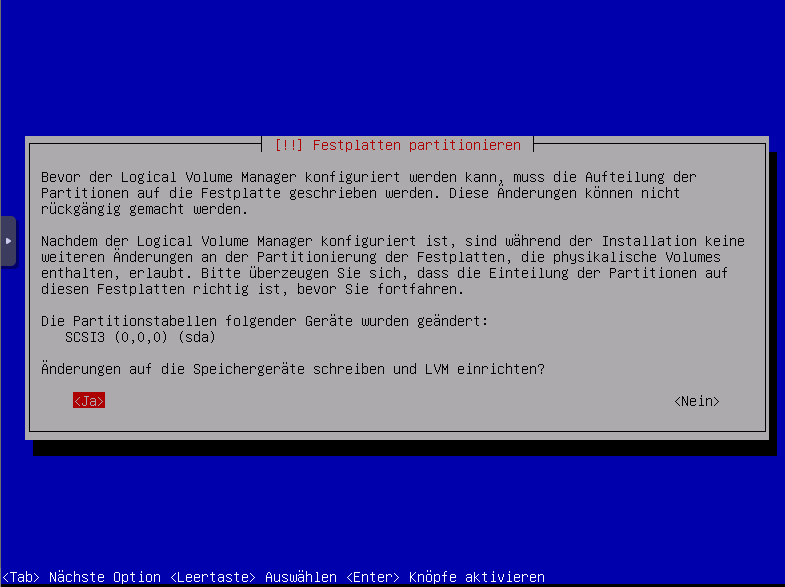
Änderungen speichern und schreiben
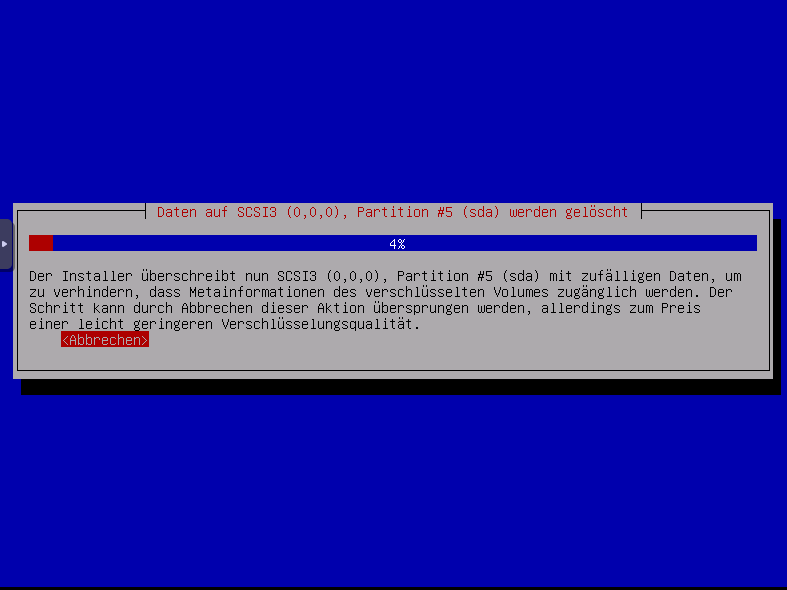
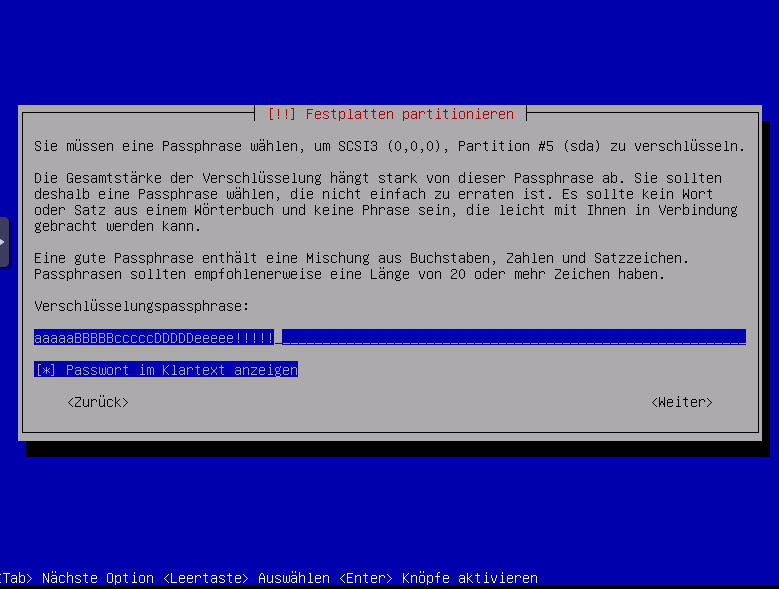
Festplatte wird überschrieben um Datenwiederherstellung zu vermeiden, ich drücke hier jetzt abbrechen, ihr solltest das durchlaufen lassen um weil sonst eine geringere Verschlüsselungsqualität zur Verfüng steht.
Kennwort / Passephrase eintippen.
Wir nutzen hier zur demonstration:
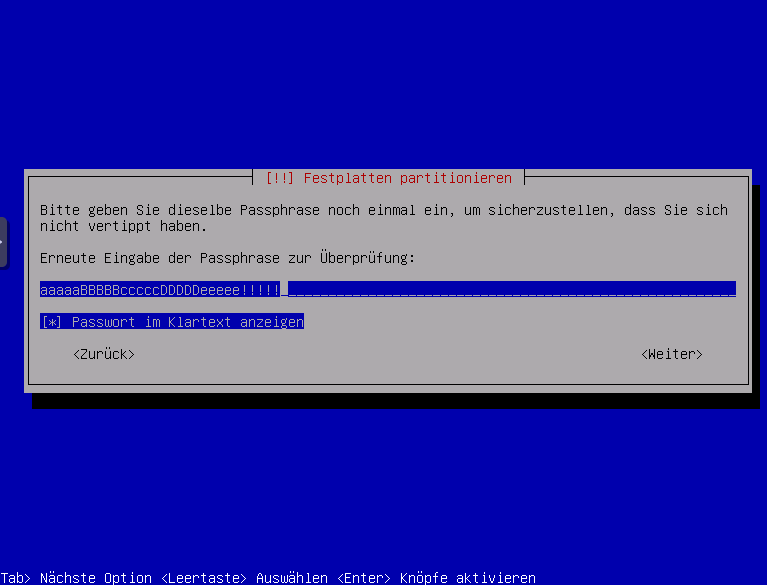
aaaaaBBBBBcccccDDDDDeeeee!!!!!
Diesen Kennwort natürlich nicht nutzen sondern logischerweise ein eigenes verwenden.
und noch einmal
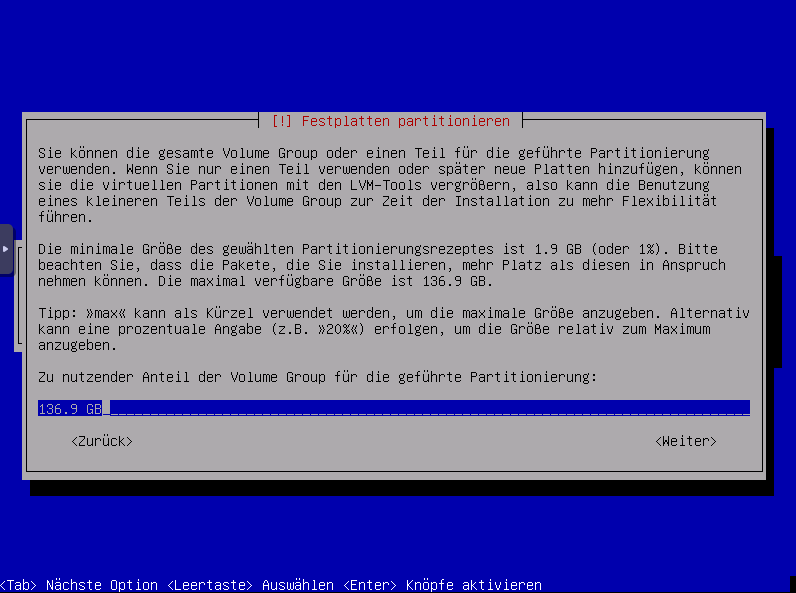
Größe fürs LVM Volume festlegen
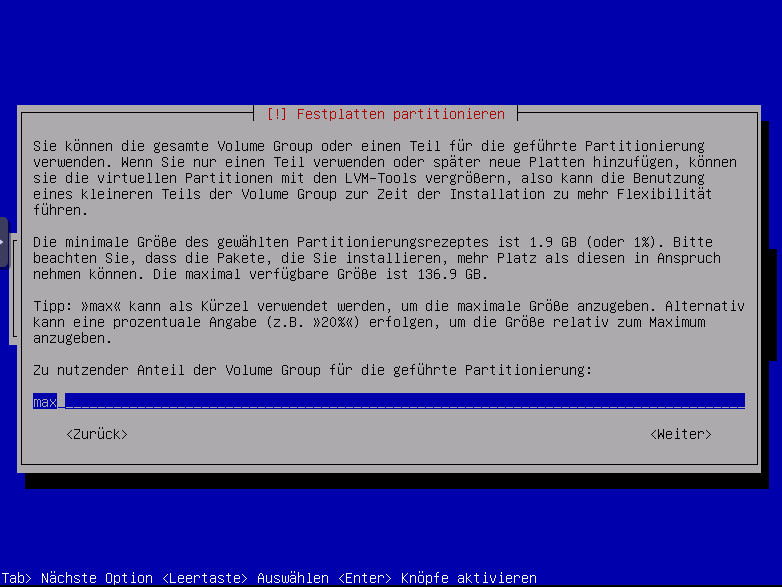
es kann auch max für die Gesamte Größe angegeben werden.
Hier der Vorschlag vom System
mit dem Wert max die gesamten Speicher für die Volumegroup nehmen
Partionierung durchführen und Anderungen speichern
Änderungen auf Festplatten schreiben Ja
Festplatte wird formatiert und Installation Grundsystem

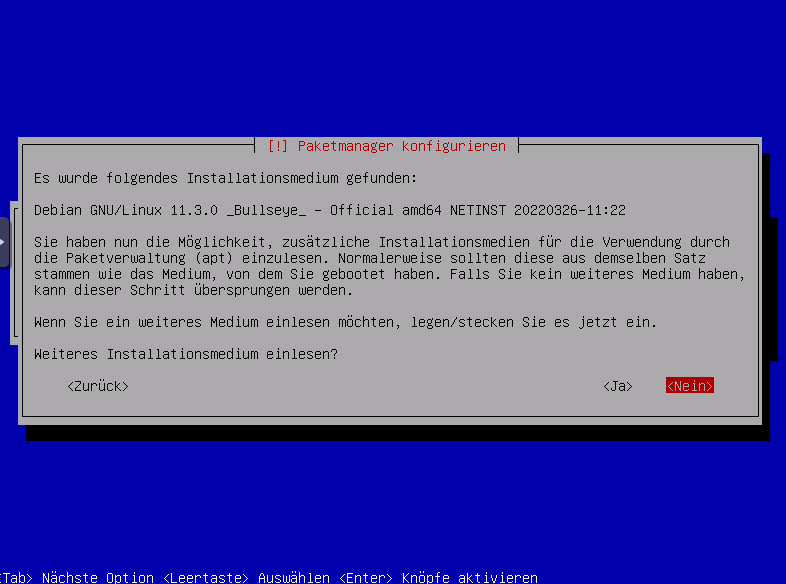
Weiteres installationsmedium verwenden? Nein
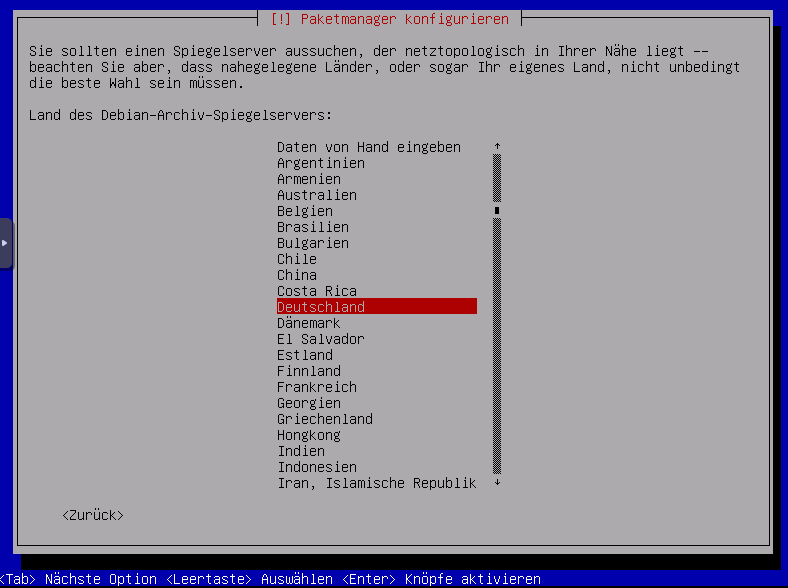
Sprache Paketmanager, hier Deutsch
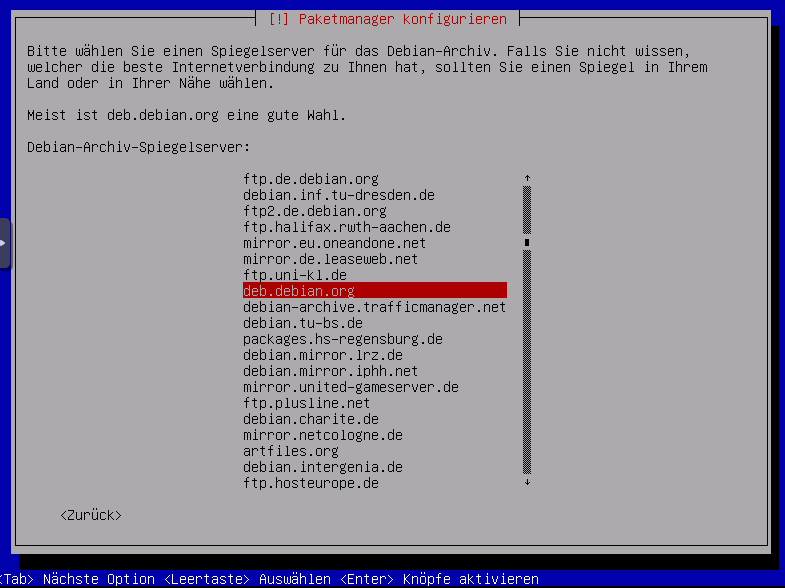
Archiv Server auswählen, debian.org
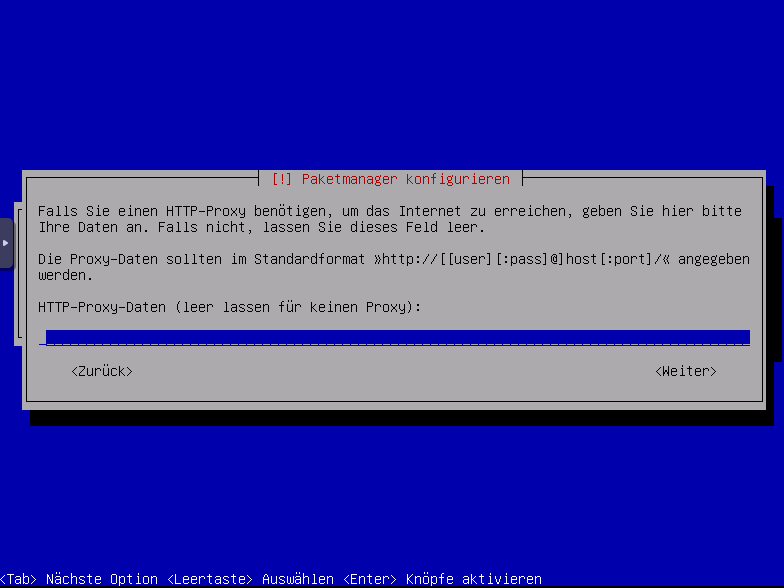
Proxy angeben, wenn vorhanden, hier haben wir keinen Proxy
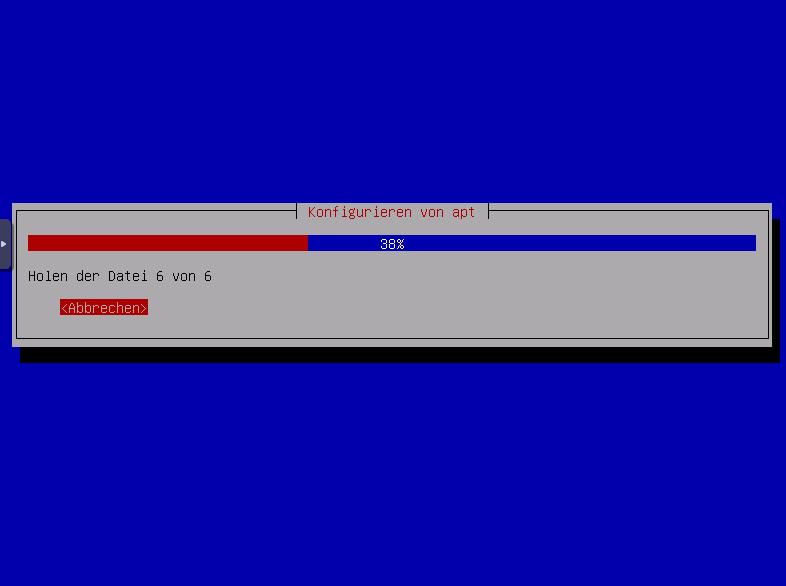
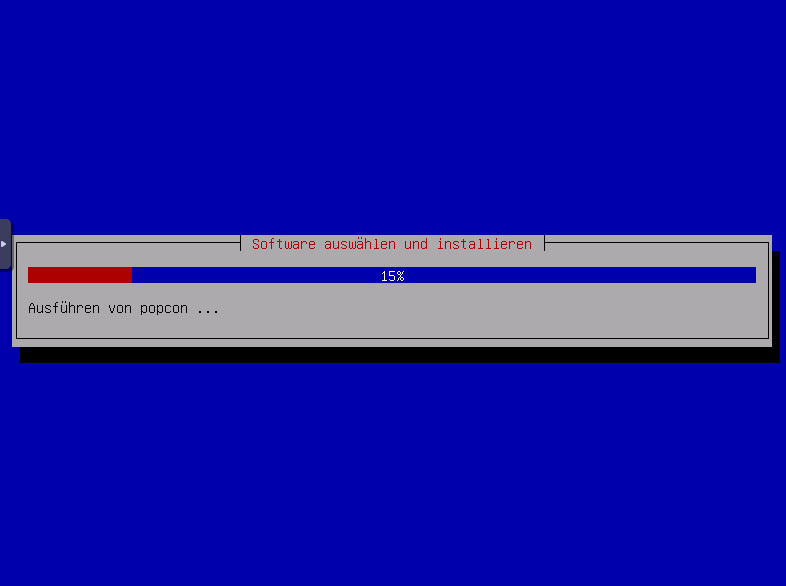
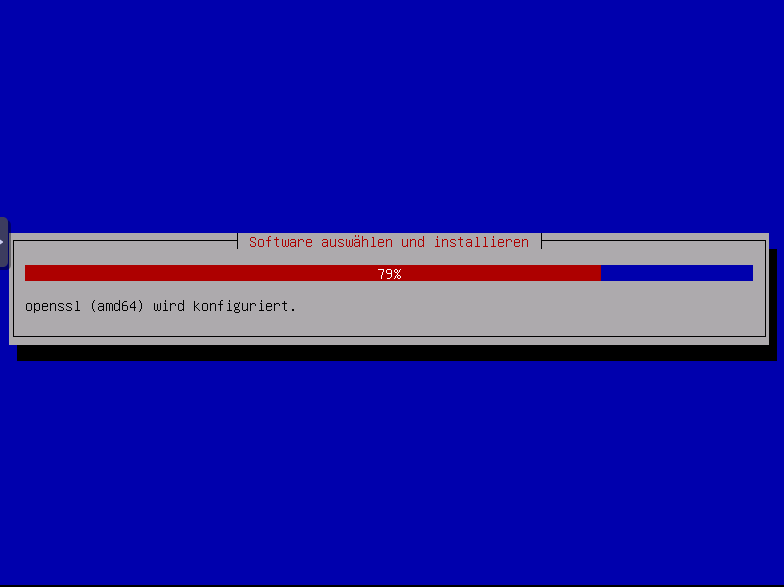
APT wird konfiguriert und software auswählen und installieren, simply wait

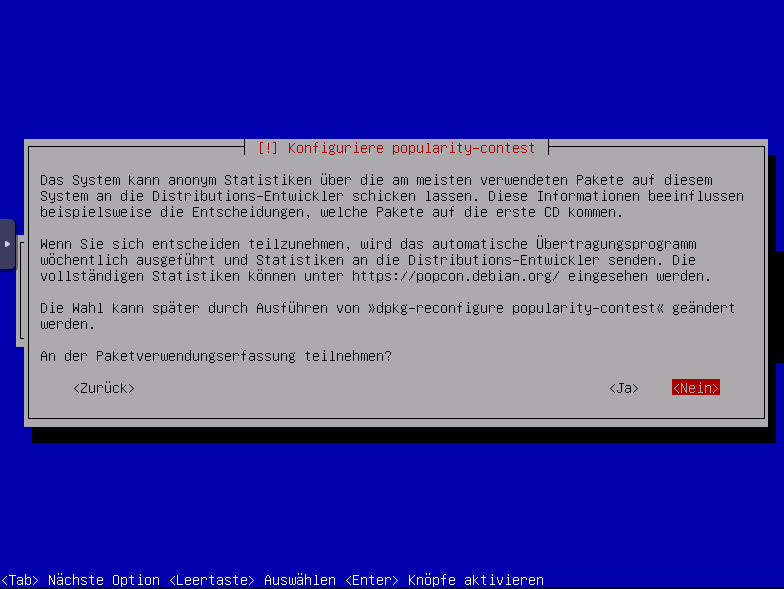
Paketverwendungserfassungteilnehmen. ich sag hier nein muss aber jeder selbst wissen
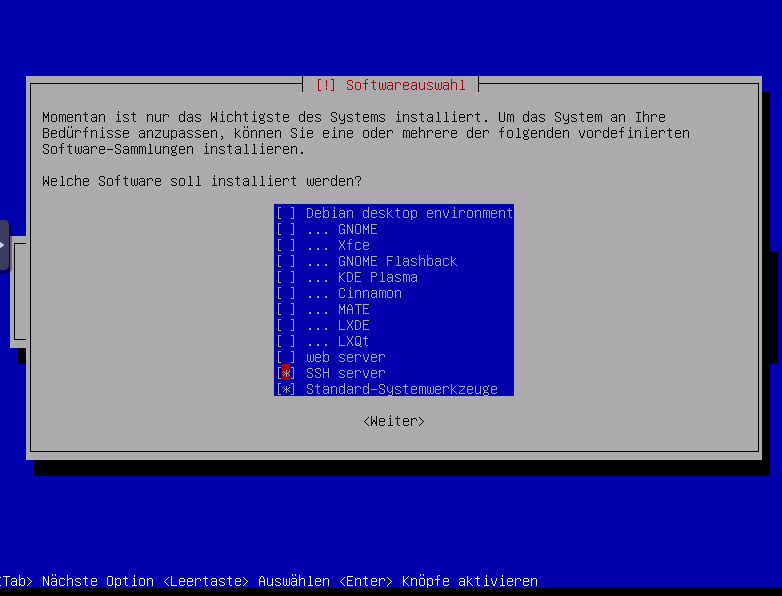
Sofware auswählen
ssh-Server und Standardsystemwerkzeuge
alles andere abhaken
Installation läuft...
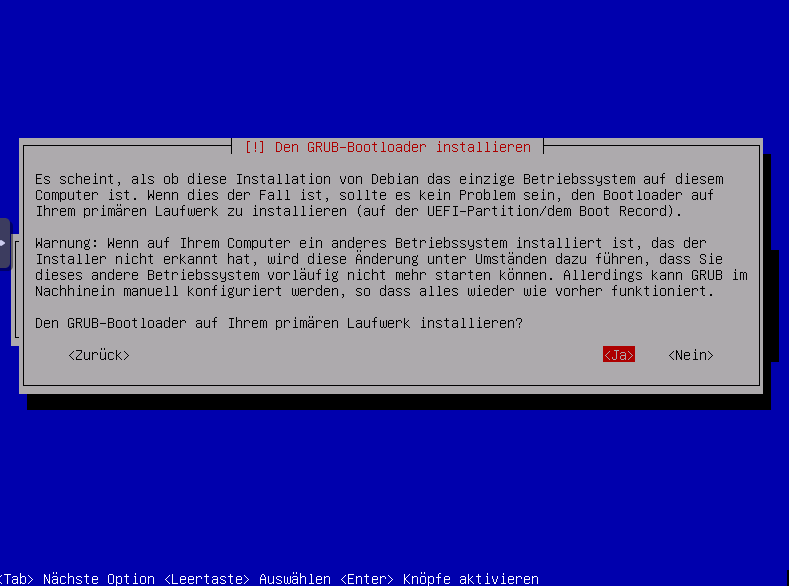
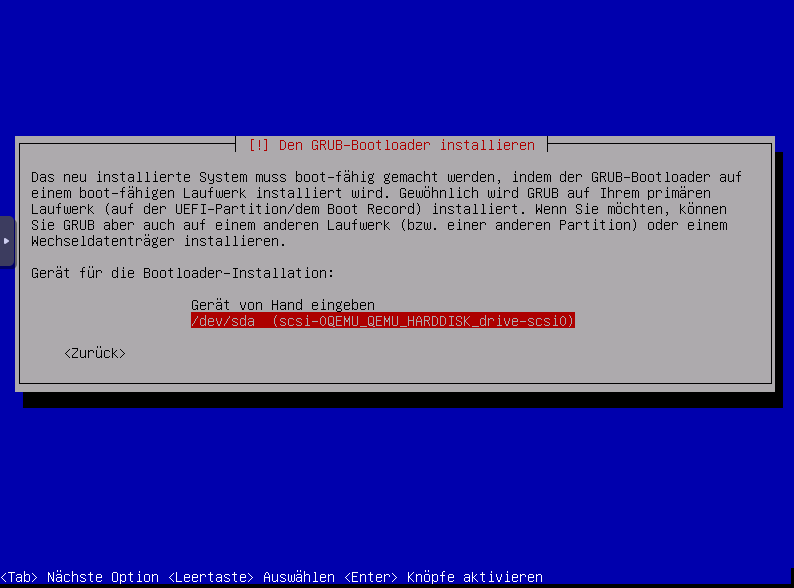
Grubloader auf auf Ihrem primären Laufwerk installieren? Ja auswählen
Festplatte auswählen.
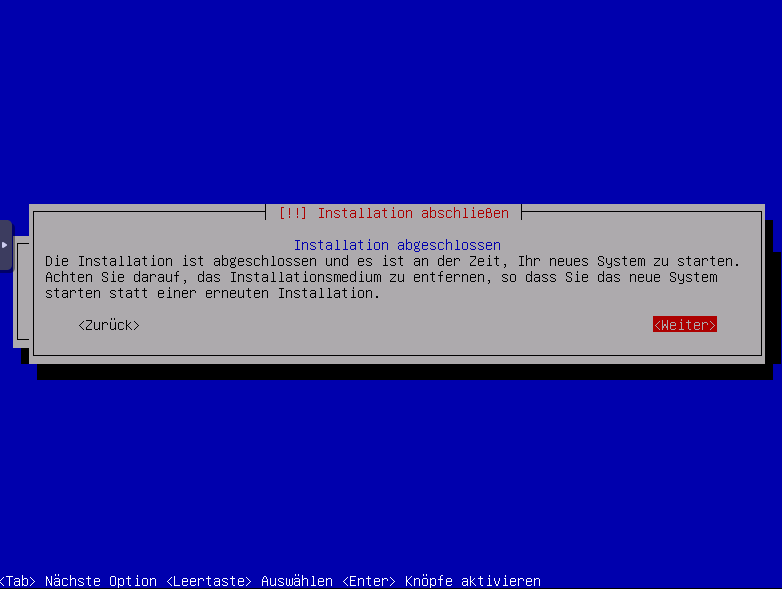
Installation abgeschlossen system wird neu gestartet
Nach dem neustart steht der Bildschirm zum Passphrase eingeben
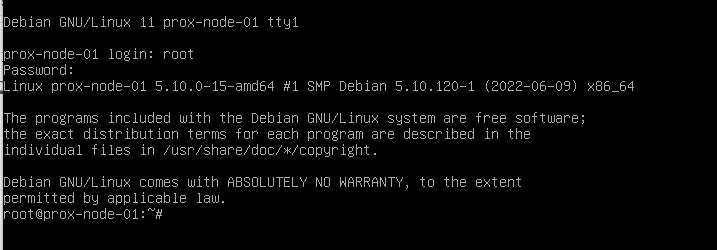
wir geben unser Kennwort an und e voila drin
login screen
nun können wir usn mit dem root passwort einloggen
Drin
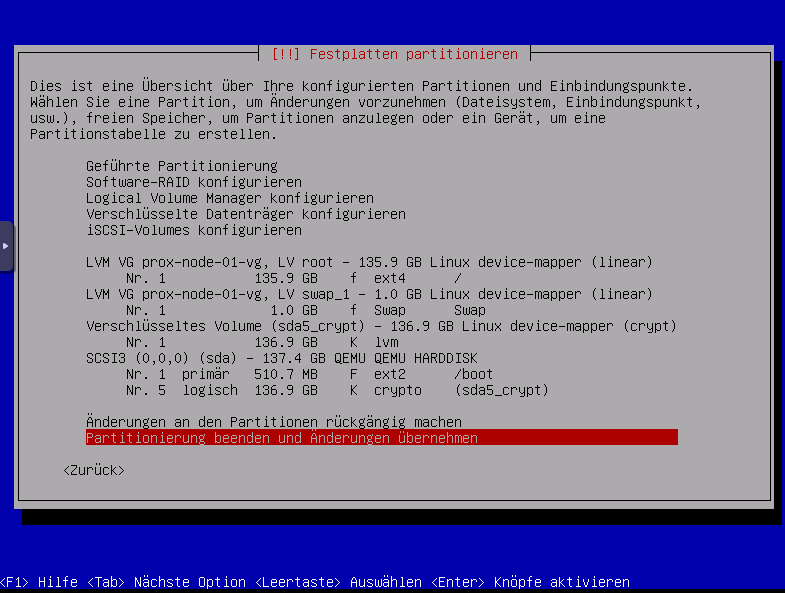
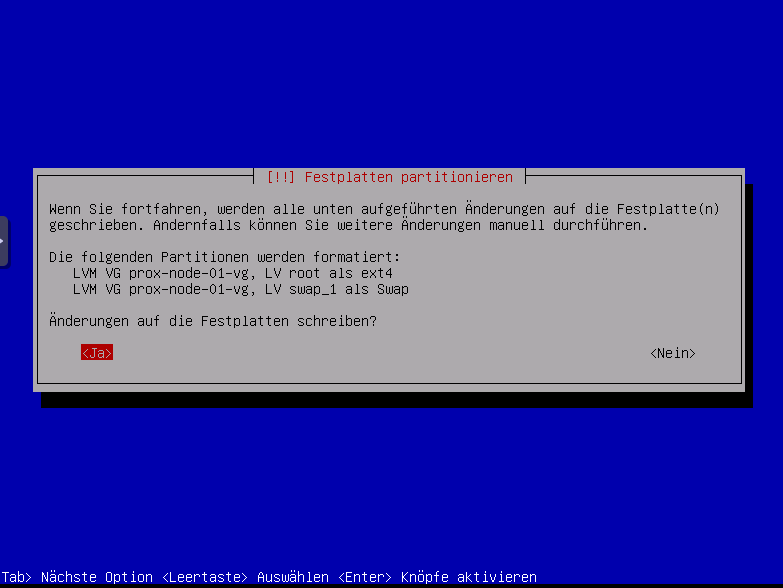
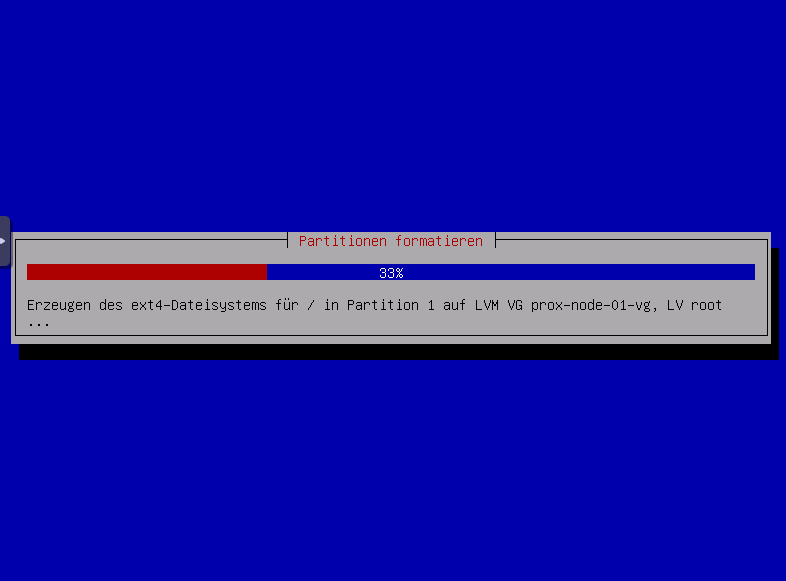
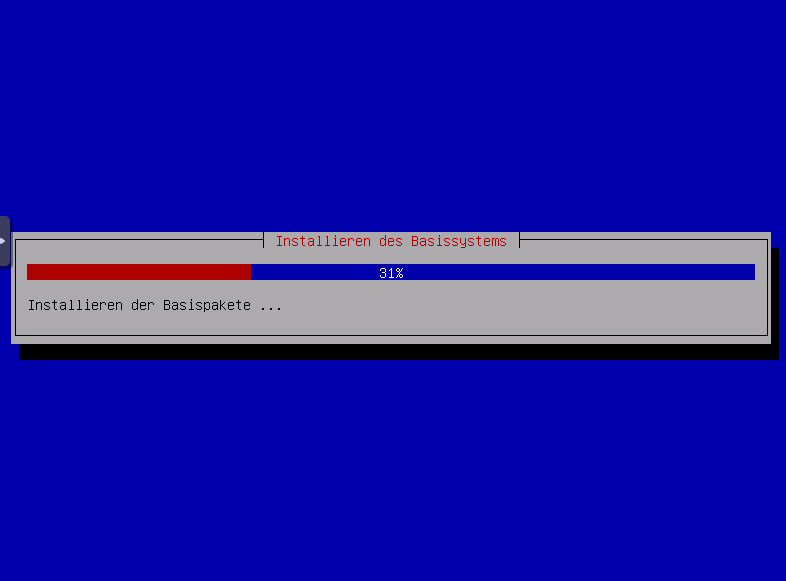

Einloggen per SSH Preauthentication ,damit Kennwort nicht per VNC eingeben weden muss
- Da es natürlich immer sehr mühselig ist, das Kennwort per Tastatur über VNC oder wenn es Bare Metal ist, direkt am Server einzutippen, installieren wir einen SSH Server in initramfs wo wir uns dann hin verbinden können um die Passphrase per copy und paste, einzufügen / eingeben zu können.
- root login per ssh freischalten und ssh-key kopieren macht
nano /etc/ssh/sshd_configauf yes ändern und dann den dienst neustarten
PermitRootLogin yesservice ssh restartNun kann ein login per ssh stattfinden. Jetzt kopieren wir mit
ssh-copy id root@ip-adresseunseren public ssh key auf den Server und kommentieren danach die
#PermitRootLogin yeswieder aus. Nun Dienst wieder neustarten.
service ssh restart - Dropbear initramfs
Mit y bestätigenapt update && apt install dropbear-initramfs update-initramfs -u
Nun bekommen wir die Meldung invalid authorized file
Dazu einen Pub key, am besten einen aderen als der der fürs eigentliche System benutzt wird in die Datei/etc/dropbear-initramfs/authorized_keys
nano /etc/dropbear-initramfs/authorized_keysund dort den Pub key rein und speichern.
Es empfiehlt sich einen aderen SSH-Port zu wählen
Dazu die Datei/etc/dropbear-initramfs/configöffnennano /etc/dropbear-initramfs/configUnd dort bei, sollte dropbear options auskemmntiert sein, das raute symbol natürlich entfernen
DROPBEAR_OPTIONS="-p 12345"
den Port angeben. In diesem Beispiel ist unser Port 12345
Nur durchführen wenn kein DHCP-Server vorhanden oder man die IP-Adresse selbst vergeben will/etc/initramfs-tools/initramfs.confInhalt:
IP Address=192.168.1.27 Gateway=192.168.1.1 Subnet Mask: 255.255.255.0 Hostname=nothing.local.lan
nun initramfs aktualisieren
update-initramfs -uNun keine Fehler mehr. SSH config dropbear scheint richtig zu sein. ;-)
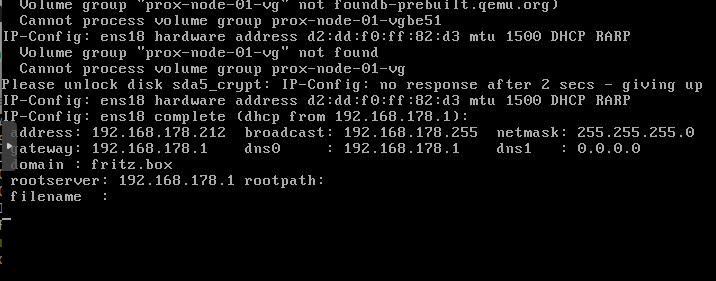
Nun neustartrebootNun steht beim starten die IP Adresse von drop-bear (DCHP-Server vorrausgesetzt)
in unserem Falle. 192.168.178.212
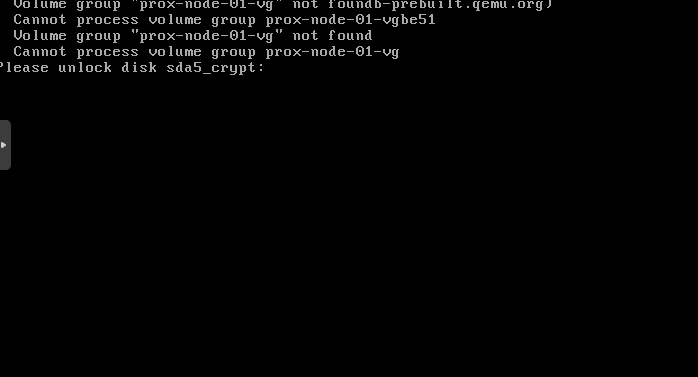
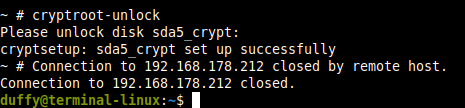
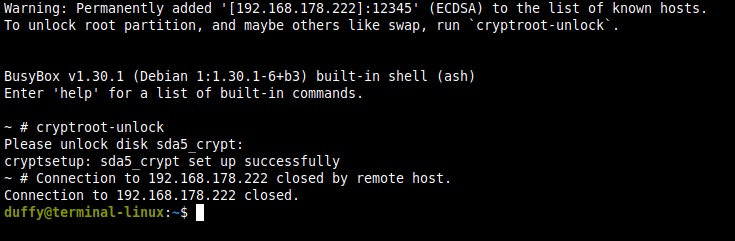
Nun per ssh verbinden (denkt daran port 12345ssh root@192.168.178.212 -p 12345in der busybox wird uns schon verraten das der Befehl zum entschlüsseln cryptroot-unlock ist
cryptroot-unlockNun das Passwort über die Zwischenablage oder Keepass einfügen
Die VNC Konsole oder Echter Bildschirm mit dem Login Fenster
Danach wird man ausgeloggt und der Server startet.


Die eigentliche Proxmox installation
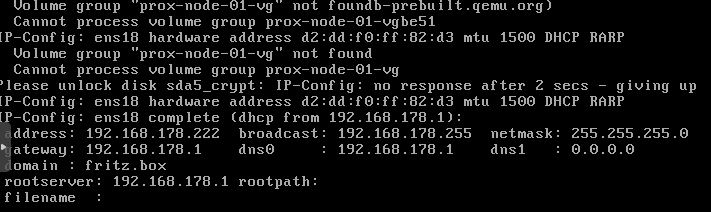
Die hosts Datei anpassen.
und in unserem Beispiel hat die Prox node die 192.168.178.222
127.0.0.1 localhost
192.168.178.222 prox-node-01.locallan prox-node-01 pvelocalhost- Netzwerkconfig anpassen
nano /etc/network/interfacesInhalt
iface ens18 inet manual auto vmbr0 iface vmbr0 inet static address 192.168.178.222 netmask 255.255.255.0 gateway 192.168.178.1 bridge_ports ens18 bridge_stp off bridge_fd 0Diese an seinen eigenen Interface Namen und ip Adressen anpassen
Danachservice networking restartausführen.
- Nun die Pakete installieren und nicht benötigte entfernen
Repo hinzufügen
echo "deb [arch=amd64] http://download.proxmox.com/debian/pve bullseye pve-no-subscription" > /etc/apt/sources.list.d/pve-install-repo.list wget https://enterprise.proxmox.com/debian/proxmox-release-bullseye.gpg -O /etc/apt/trusted.gpg.d/proxmox-release-bullseye.gpgPakete installieren. Bei der Postfix installation. Den Typ lokal auswählen.
apt update && apt full-upgrade apt install proxmox-ve postfix open-iscsi apt remove linux-image-amd64 'linux-image-5.10*' update-grub apt remove os-prober update-grubNun neustart mittels reboot, system entsperren und über https://192.168.178.222:8006 anmelden.
Nach dem neustart bekommt der ssh-server bei der Verschlüsselung, wenn verschlüsselung vorhanden, die gleiche Adresse wie der Proxmox host, in unserem beispiel auch die 192.168.178.222 was vorher ja noch die 212 war.
Dieser Abschnitt gillt nur wenn Verschlüsselung aktiv
siehe Monitor / VNC Konsole
Wieder unlock fertig.
Dieser Abschnitt gillt nur wenn Verschlüsselung aktiv
Nun sehen wir auf dem Bildschirm KVM Konsole den Login Bildschirm von proxmox
ende des Abschnittes
-
Nun mit dem Webbrowser per https://192.168.178.222:8006 aufrufen, selbsigniertes Zertifikat zur Ausnahme hinzufügen

und mit dem root Benutzer und Kennwort Anmelden. Fertig.


Proxmox - Installation eines arm64 VM Gastest
Vorbereiten der VM
Beschreibung
Es ist unter Proxmox dank Qemu/KVM auch möglich eine arm64 CPU zu emulieren. Z.b Für ein Raspberry System oder einen UniFi Videorekorder als Beispiel.
Vorbereitung
ISO Download in den Proxmox Storage. Unter Version 7 geht das direkt über die GUI ansonsten per WGET
Die aktuellen Dieban ARM64 ISOs findet man hier : https://cdimage.debian.org/debian-cd/current/arm64/iso-cd/
Ab Version 8.0 :
Muss das Efi Image in Proxmox nachinstalliert werden.
per ssh auf Proxmox gehen und
apt install pve-edk2-firmware-aarch64GUI-Methode wer sie noch nicht kennt:
AUf den gewünschten Speicher klicken wo die ISO heruntergeladen werden soll

Dann im Menü ISO Images auswählen
Nun oben auf Download from URL klicken
Nun die URL zur ISO einfügen, hier die : https://cdimage.debian.org/debian-cd/current/arm64/iso-cd/debian-11.6.0-arm64-netinst.iso und auf Query URL klicken.
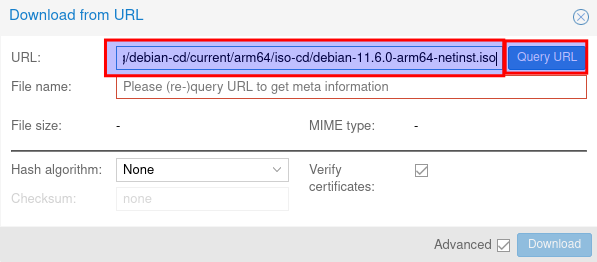
Nun wird der Name ermittelt und dann auf Download klicken

Download Fenster schließen über X wenn unten Task OK steht.
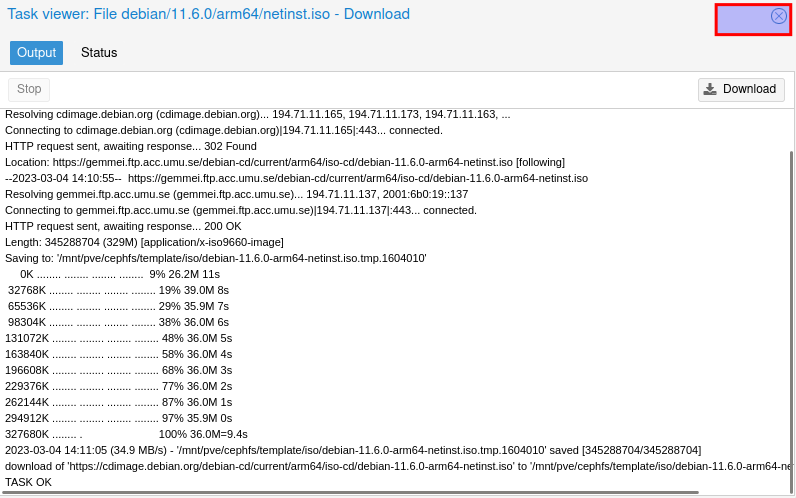
WGET Methode:
Auf dem Proxmoxhost als root per ssh einloggen und folgenden wget Befhl absetzten. Dazu die gewünschte URL zur ISO eingeben/einfügen zum Beispiel diese: wget https://cdimage.debian.org/debian-cd/current/arm64/iso-cd/debian-11.6.0-arm64-netinst.iso
#bei standard local storage
cd /var/lib/vz/template/iso
wget https://cdimage.debian.org/debian-cd/current/arm64/iso-cd/debian-11.6.0-arm64-netinst.iso
#bei anderen storages wie bei mir ein cephfs
cd /mnt/pve/<datastorename>/template/iso
cd /mnt/pve/cephfs/template/iso
wget https://cdimage.debian.org/debian-cd/current/arm64/iso-cd/debian-11.6.0-arm64-netinst.isoVirtuelle Machine anlegen
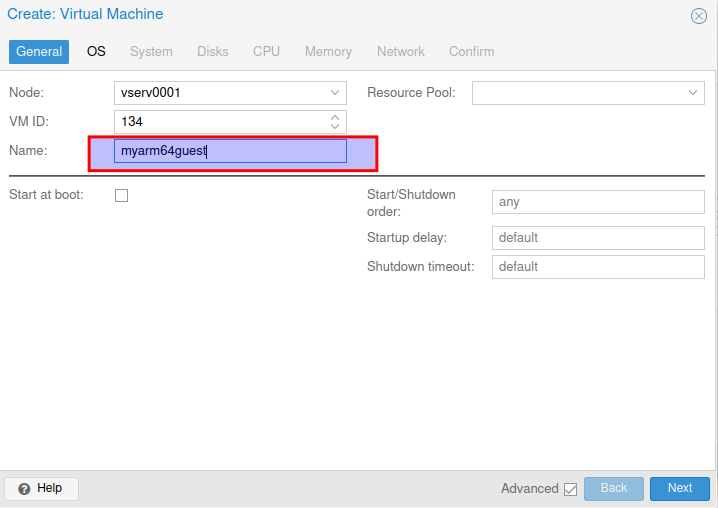
Auf Create VM klicken

Nun dem Kind einen Namen geben und auf weiter klicken.
Nun als ISO aus dem Storages die arm64 iso auswählen und auf weiter klicken.
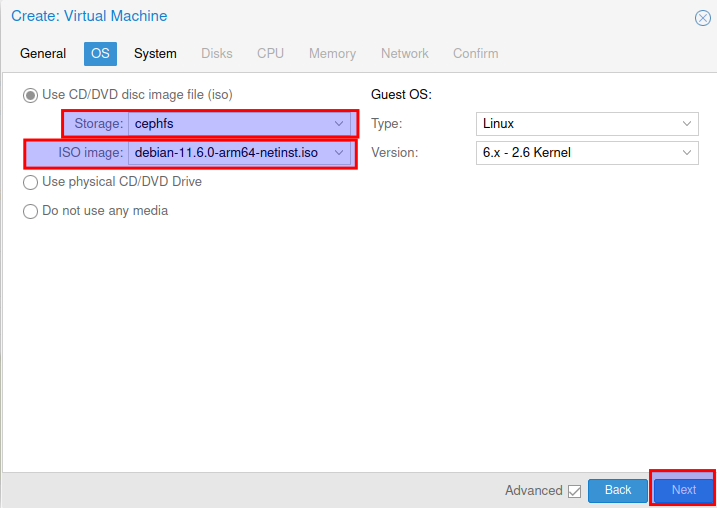
Nun als BIOS : OVMF (UEFI) auswählen
Add EFI Disk : abhaken
Auf weiter klicken

Storage auswählen und Größe angeben. Mir reichen 32GB, aber so wir Ihr es braucht
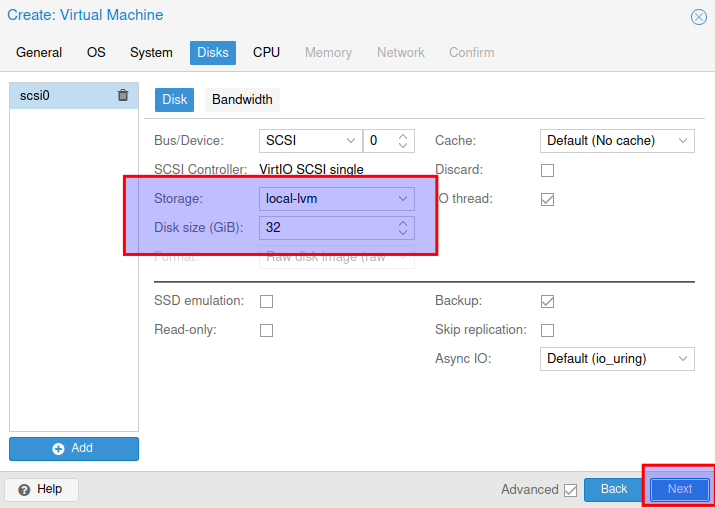
CPU Kerne auswählen. Ich nehme 4 aber das wieder nach den eigenen bedürfnissen anpassen
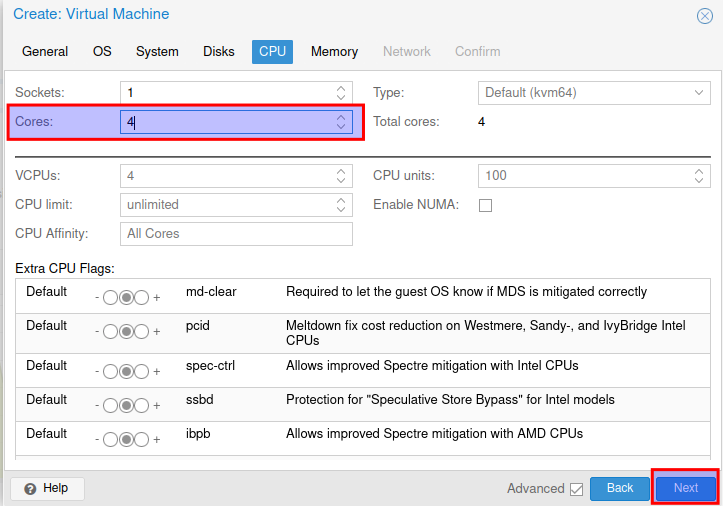
Genau wie bei Arbeistspeicher, ich nehme 4096 aber auch wieder nach den Bedürfnissen
Ballooning Device : haken raus
Auf weiter
Netzwerk passt bei mir so. Ansonsten euren Bedürfnissen anpassen und auf weiter.

Nun auf Finish klicken

Virtuelle machine bearbeiten
Nun Im Menü die Virtuelle Machine auswählen

Nun Auf den Menüpunkt Hardware klicken
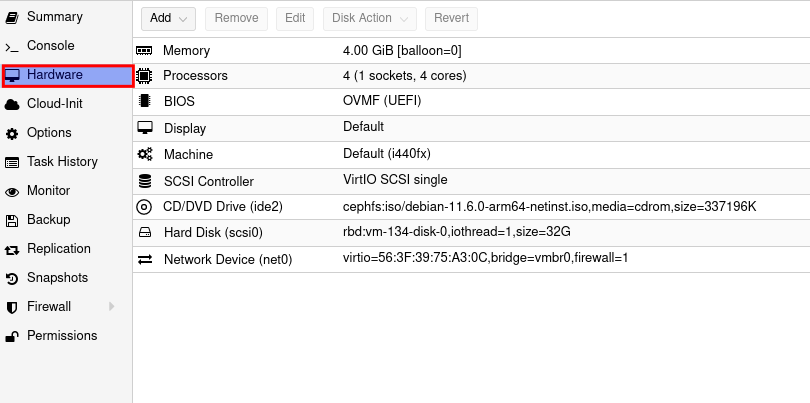
Nun das CD/DVD Laufwerk anklciken und danach oben auf remove klicken
Frage ob wirklich gelöscht werden soll, mit ja beantworten
Nun Oben im Neü auf ADd und dann Serial Port anklicken

Nun einfach auf Add klicken. Denn der Port 0 reicht uns

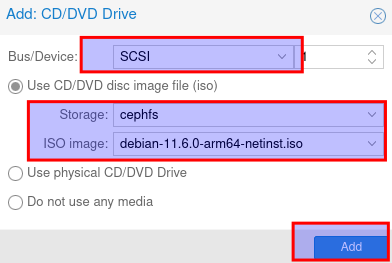
Nun wieder auf Add und CD/DVD auswählen

Als BUS SCSI auswählen
Den Stoarge wo die Iso liegt auswählen
Die arm64 iso auswählen
Auf add klicken
Nun doppelklick auf Display

Bei Graphiccard : Serial terminal 0 auswählen und ok

Nun doppelklick auf die Festplatte
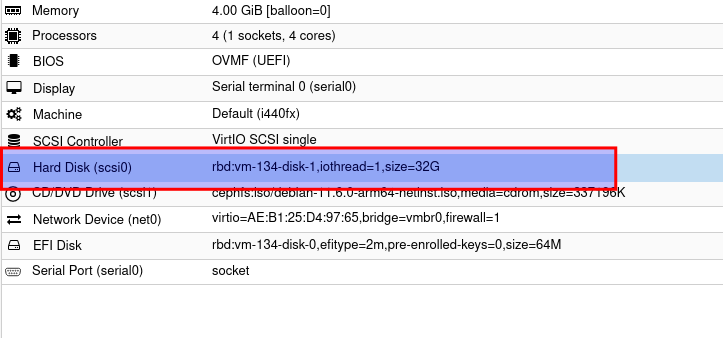
Dort dann den haken bei iothread raus und auf ok
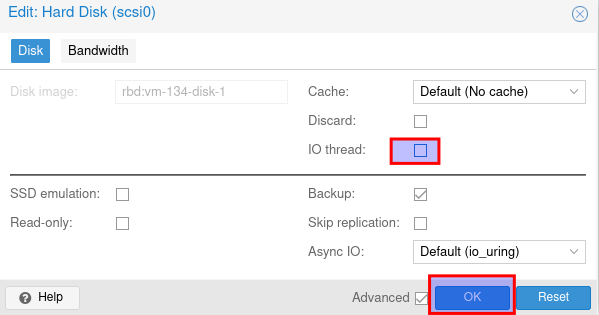
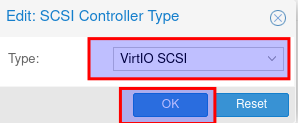
Nun doppelklick auf SCSI Controller

Nun den von VirtIO SCSI single auf VirtIO SCSI ändern und auf ok
Nun im Menü auf options klicken
Dann doppelklcik auf Boot Order
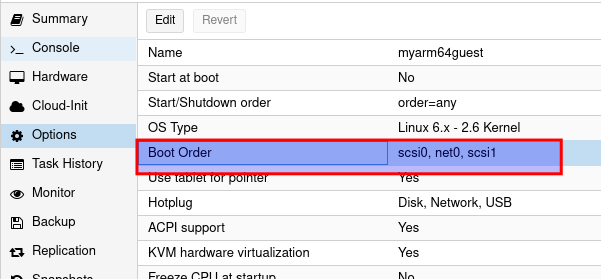
Nun das CD Laufwerk mit Linksgedrückt halten und an die erste stelle ziehen, so das es dann so aussieht
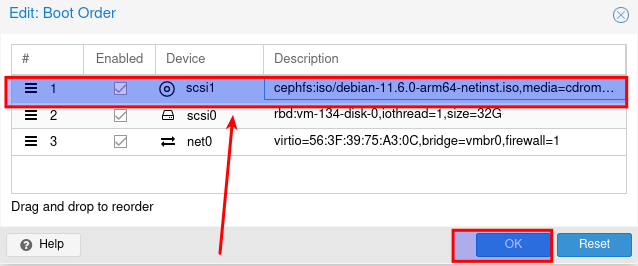
Anpassen der Architektur der Maschine
Dazu wieder per ssh auf dem Host einloggen und die Conf datei von der Machine zu editieren
nano /etc/pve/qemu-server/<vmid>.conf
in usnerem Fall
nano /etc/pve/qemu-server/134.confVon:
balloon: 0
bios: ovmf
boot: order=scsi1;scsi0;net0
cores: 4
memory: 4096
meta: creation-qemu=7.1.0,ctime=1677936909
name: myarm64guest
net0: virtio=56:3F:39:75:A3:0C,bridge=vmbr0,firewall=1
numa: 0
ostype: l26
scsi0: rbd:vm-134-disk-0,iothread=1,size=32G
scsi1: cephfs:iso/debian-11.6.0-arm64-netinst.iso,media=cdrom,size=337196K
scsihw: virtio-scsi-single
serial0: socket
smbios1: uuid=4d234d40-733c-4881-bc0c-38ec912e0432
sockets: 1
vga: serial0
vmgenid: 6794e873-22e6-4ff1-b35e-654e01d58f02
Nach ändern:
vmgenid: .... auskommentieren
und arch:aarch64 hinzufügen
Sieht dann so aus:
balloon: 0
bios: ovmf
boot: order=scsi1;scsi0;net0
cores: 4
memory: 4096
meta: creation-qemu=7.1.0,ctime=1677936909
name: myarm64guest
net0: virtio=56:3F:39:75:A3:0C,bridge=vmbr0,firewall=1
numa: 0
ostype: l26
scsi0: rbd:vm-134-disk-0,iothread=1,size=32G
scsi1: cephfs:iso/debian-11.6.0-arm64-netinst.iso,media=cdrom,size=337196K
scsihw: virtio-scsi-single
serial0: socket
smbios1: uuid=4d234d40-733c-4881-bc0c-38ec912e0432
sockets: 1
vga: serial0
#vmgenid: 6794e873-22e6-4ff1-b35e-654e01d58f02
arch:aarch64Nun noch die Efi Disk mit folgendem Befehl hinzufügen
efitype=2m, wenn es über die GUI gemacht wird, gibts an array fehler
qm set VMID -efidisk0 local:1,efitype=2m,pre-enrolled-keys=0,format=qcow2
Speicherpfad anpassen wenn nötig
Mein Beispiel:
Die formate sind qcow2 und raw.
je nachdem was euer Zielspeicher unterstützt.
RBD unterstützt nur raw
qm set 134 -efidisk0 rbd:1,efitype=2m,pre-enrolled-keys=0,format=raw
Output
<pre>pdate VM 134: -efidisk0 rbd:1,efitype=2m,pre-enrolled-keys=0,format=raw
transferred 0.0 B of 64.0 MiB (0.00%)
transferred 2.0 MiB of 64.0 MiB (3.12%)
transferred 4.0 MiB of 64.0 MiB (6.25%)
transferred 6.0 MiB of 64.0 MiB (9.38%)
transferred 8.0 MiB of 64.0 MiB (12.50%)
transferred 10.0 MiB of 64.0 MiB (15.62%)
transferred 12.0 MiB of 64.0 MiB (18.75%)
transferred 14.0 MiB of 64.0 MiB (21.88%)
transferred 16.0 MiB of 64.0 MiB (25.00%)
transferred 18.0 MiB of 64.0 MiB (28.12%)
transferred 20.0 MiB of 64.0 MiB (31.25%)
transferred 22.0 MiB of 64.0 MiB (34.38%)
transferred 24.0 MiB of 64.0 MiB (37.50%)
transferred 26.0 MiB of 64.0 MiB (40.62%)
transferred 28.0 MiB of 64.0 MiB (43.75%)
transferred 30.0 MiB of 64.0 MiB (46.88%)
transferred 32.0 MiB of 64.0 MiB (50.00%)
transferred 34.0 MiB of 64.0 MiB (53.12%)
transferred 36.0 MiB of 64.0 MiB (56.25%)
transferred 38.0 MiB of 64.0 MiB (59.38%)
transferred 40.0 MiB of 64.0 MiB (62.50%)
transferred 42.0 MiB of 64.0 MiB (65.62%)
transferred 44.0 MiB of 64.0 MiB (68.75%)
transferred 46.0 MiB of 64.0 MiB (71.88%)
transferred 48.0 MiB of 64.0 MiB (75.00%)
transferred 50.0 MiB of 64.0 MiB (78.12%)
transferred 52.0 MiB of 64.0 MiB (81.25%)
transferred 54.0 MiB of 64.0 MiB (84.38%)
transferred 56.0 MiB of 64.0 MiB (87.50%)
transferred 58.0 MiB of 64.0 MiB (90.62%)
transferred 60.0 MiB of 64.0 MiB (93.75%)
transferred 62.0 MiB of 64.0 MiB (96.88%)
transferred 64.0 MiB of 64.0 MiB (100.00%)
transferred 64.0 MiB of 64.0 MiB (100.00%)
efidisk0: successfully created disk 'rbd:vm-134-disk-0,efitype=2m,pre-enrolled-keys=0,size=64M'
</pre>Fehler:
EFI-DIsk
Sollte beim Efi Disk erstellen dieser Fehler auftauchen:
root@pve01:~# qm set 100 -efidisk0 local-lvm:1,efitype=2m,pre-enrolled-keys=0,format=raw
update VM 100: -efidisk0 local-lvm:1,efitype=2m,pre-enrolled-keys=0,format=raw
EFI base image '/usr/share/pve-edk2-firmware//AAVMF_CODE.fd' not found
Ap Version 8 gibt es keine aarch64 efi images mehr.
Nachinstallieren
apt install pve-edk2-firmware-aarch64Starten Fehler CPU Typ nicht erkannt
In Proxmox 8 und höher wird Standard mäßig der CPU Typ gesetzt.
Das heißt in der <vmid>.conf wird der cpu typ festgelegt.
Da aarch64 keine kvm64 oder host kennt, muss der cpu eintrag auskommentiert werden
Vorher
...
#vmgenid%3A 9f0a633a-762b-4c4b-a43e-59460eb51e92
arch: aarch64
balloon: 0
bios: ovmf
boot: order=scsi1;scsi0;net0
cores: 4
cpu: x86-64-v2-AES
efidisk0: local-lvm:vm-100-disk-1,efitype=2m,pre-enrolled-keys=0,size=64M
memory: 2048
meta: creation-qemu=8.1.5,ctime=1718456554
name: unvr
...
nachher
...
#vmgenid%3A 9f0a633a-762b-4c4b-a43e-59460eb51e92
arch: aarch64
balloon: 0
bios: ovmf
boot: order=scsi1;scsi0;net0
cores: 4
#cpu: x86-64-v2-AES #wurde hier auskommentiert
efidisk0: local-lvm:vm-100-disk-1,efitype=2m,pre-enrolled-keys=0,size=64M
memory: 2048
meta: creation-qemu=8.1.5,ctime=1718456554
name: unvr
...
Installation des Betriebssystems
Beschreibung:
Nachdem die VM konfiguriert und zum starten auf die ISO eingestellt ist, wird jett das Betriebssystem installiert.
In meinem Fall wird das ein Debian für Unifi UNVR aber ihr könnt den Namen natürlich an eure Bedürfnisse anpassen.
Installation:
VM auswahlen
Und oben recht im Menü auf start klicken
Nun einen Moment warten und dann auf den Buton Console klicken

Nun öffnet sich eine neue Console
Dort drin einmal die Enter Taste drücken. Dann Grub BootMenü wird leider nicht dargestellt.
Aber Gott sei Dank ist ETxtmodus Install vorausgewählt.
Danach erschein ein graes Fenster. Dieses abwarten

Denn nach dem kurzen warten, haben wir den Installer vor uns.
Hier wählen wir english aus und enter.
Bei Land other
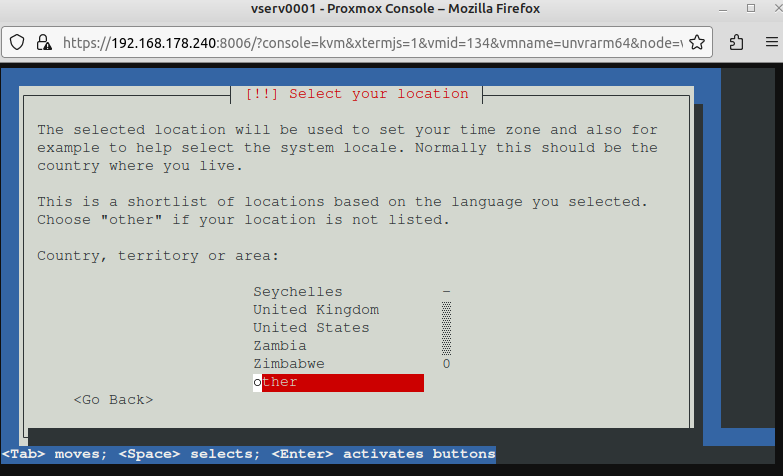
Hier bei location nun Europe auswählen

Nun Germany auswählen
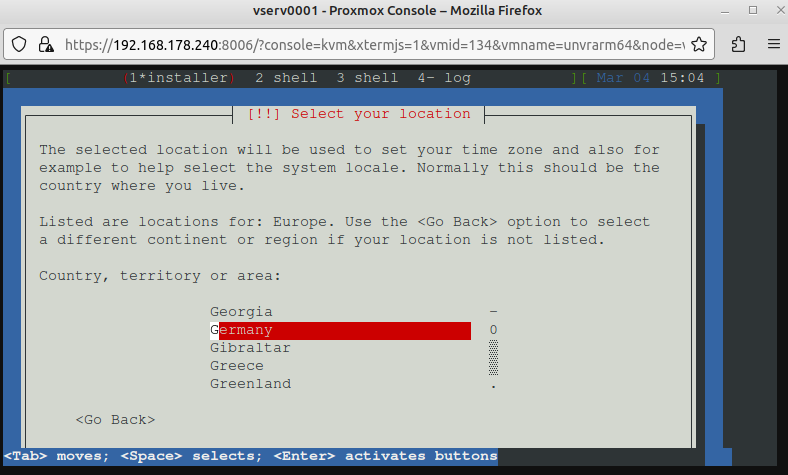 Nun United States auswählen.
Nun United States auswählen.
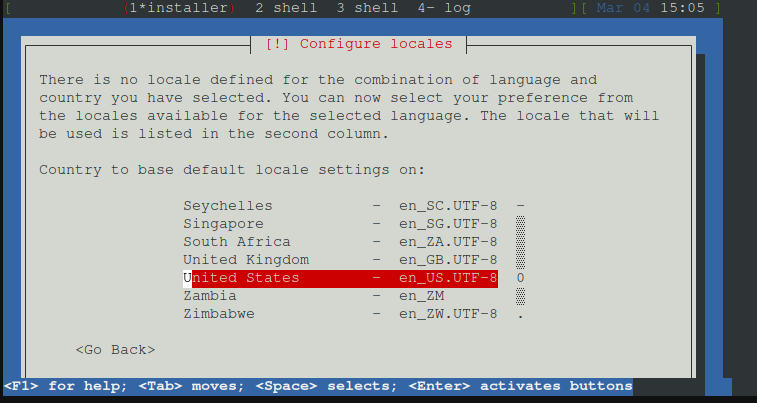
Jetzt lädt der Installer, da es ein emulirtes ARM64 System ist, das kann bis zu 5 Minuten dauern...
Nun den Hostnamen angeben. Ich lass den bei debian. Ihr könnt eintragen was ich möchtet
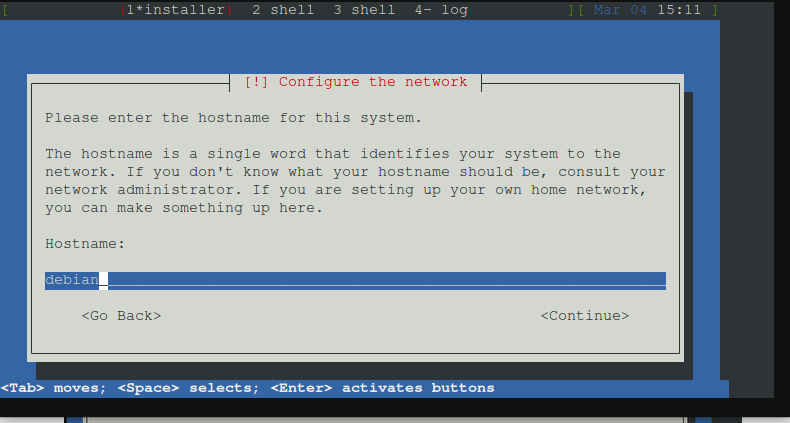
Domain Name eintragen oder leer lassen. Ich lass ihn leer.
Root Password vergeben
Root Passwort bestätigen
Nun einen Anzeige Namen vergeben, ich nehme Administrator
Nun einen Benutzernamen festlegen.
Ich nenne Ihn auch administrator, aber ihr könnt sonst jeden Namen nehmen der vom System NICHT reserviert ist.
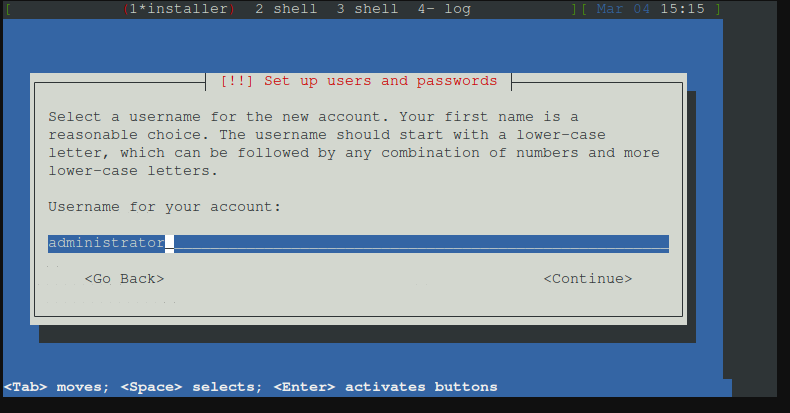
Nun auch für diesen Benutzer ein Kennwort vergeben

Dieses Kennwort bestätigen
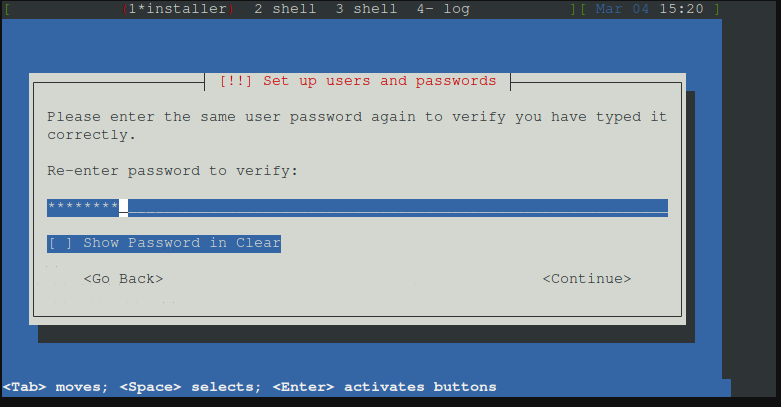
Nun hier die gesamte Disk auswählen.
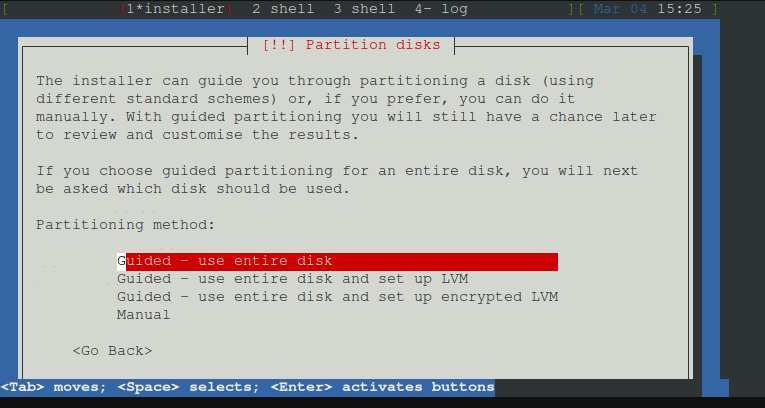
Nun die Festplatte auswählen
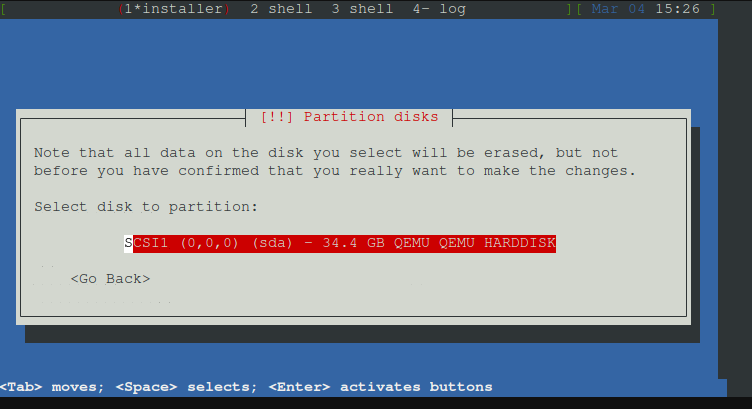
Alle Dateien in eine Partition
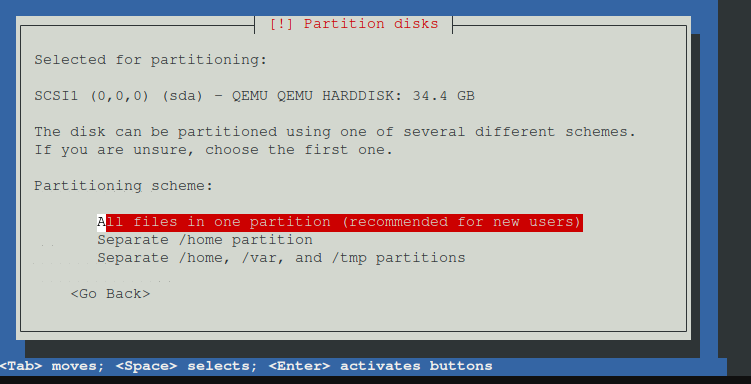
Nun auf Finish Partioning and write changes to disk
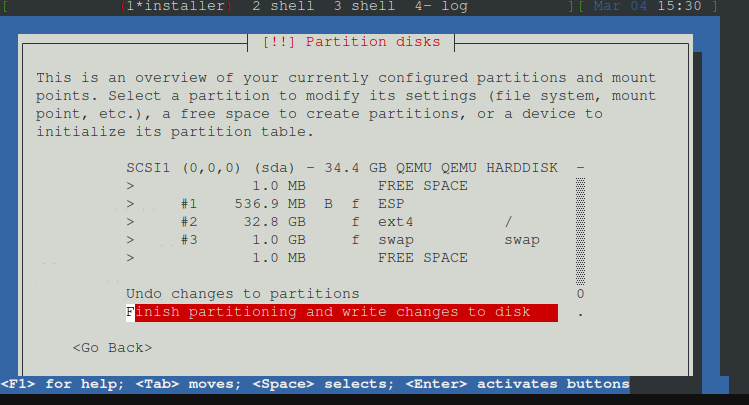
Nun auf Ja

und wieder warten kann bis zu 5 min dauern.
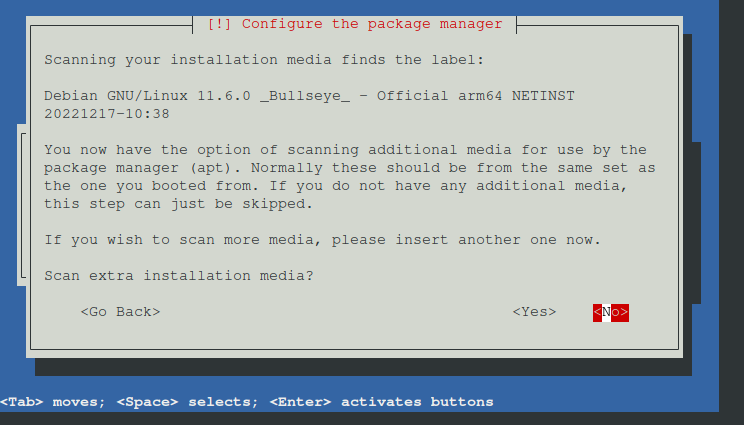
Nun die Frage nach extra medium mit nein beantworten
Nun die Sprache für den mirror auswählen, hier Germany
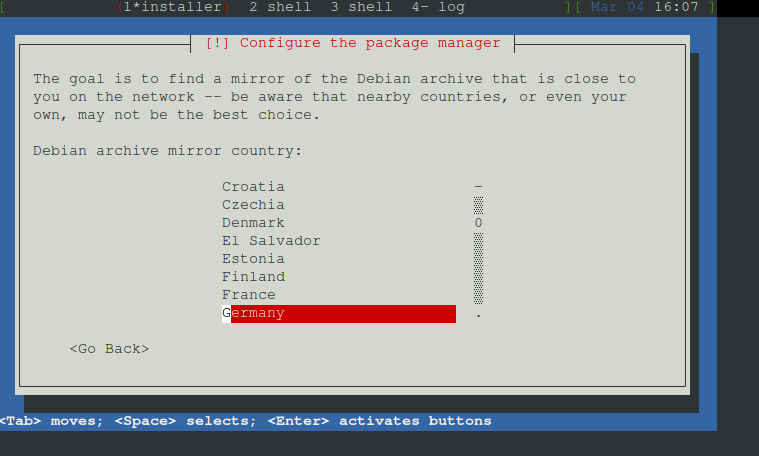
Mirror auswählen, in debian.org
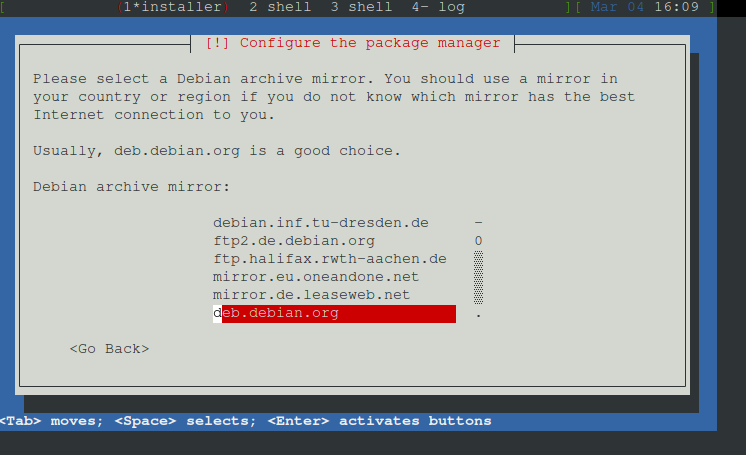
Proxy - auswählen, wenn Ihr einen Proxy nutz, eintragen.

Nun wird wieder installiert. Abwarten.
An der Paketanalyse teilnehmen : nein
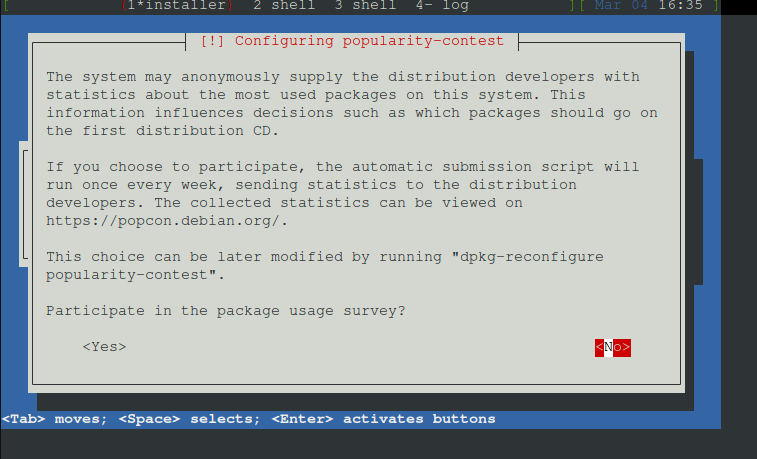
Nun alles abwählen außer SSH und Systemwerkzeuge und dann continue
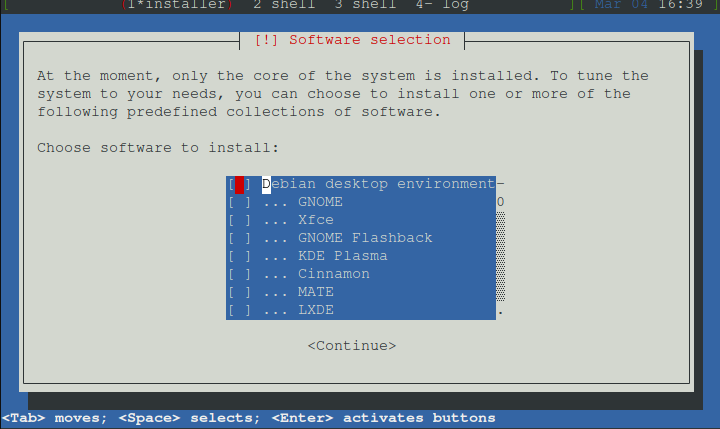

Nun einfach blind enter drücken. Dann kommt finish. Und das System startet mit der CD wieder neu.
Nun die Machine stoppen. Dazu oben im Menü bei Herunterfahren auf den Pfeil -> Stop

Installtion beendet. Auf der nächsten Seite, System startklar machen.
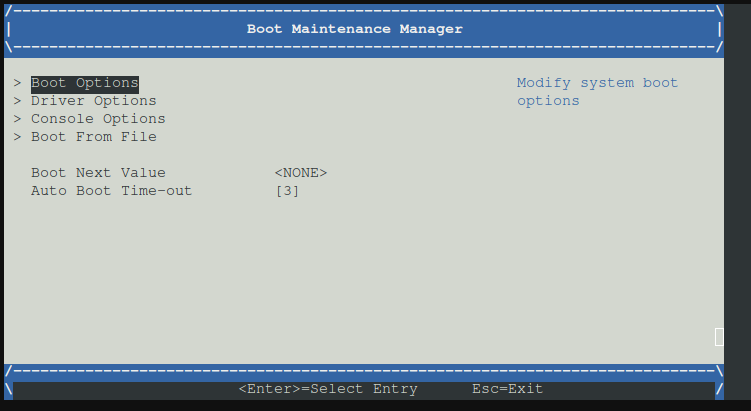
System Starten und startbar machen
- Unter Hardware bei der VM Eine EFI Disk hinzufügen. (hier ausgegraut weil schon vorhanden)

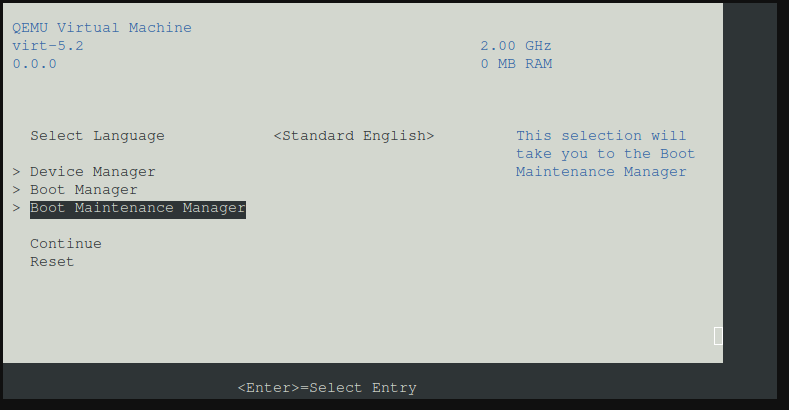
- VM Starten, Console öffnen und sofort mit der ESC Taste mehrfach drücken um ins EFI Bios zu gelangen.
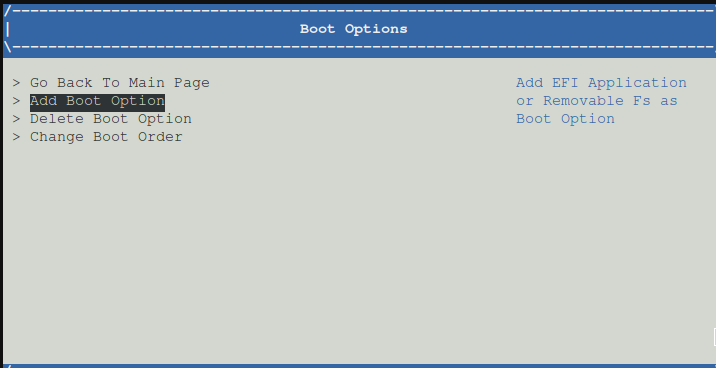
- Dort unter Boot Maintenance -> Boot options - >

Nun Add Boot option auswählen
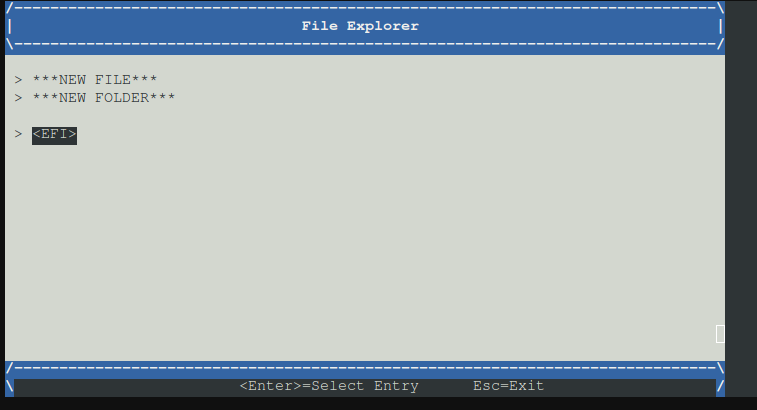
Festplatte auswählen
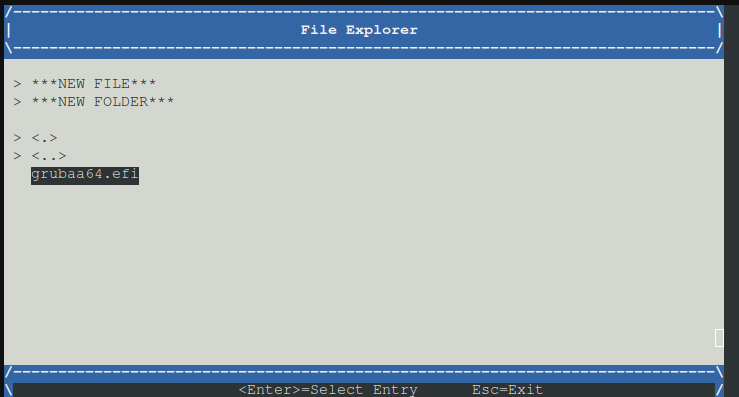
nun durch Daitsystem hangelb bis zur Efi file
Nun die EFI File auswählen
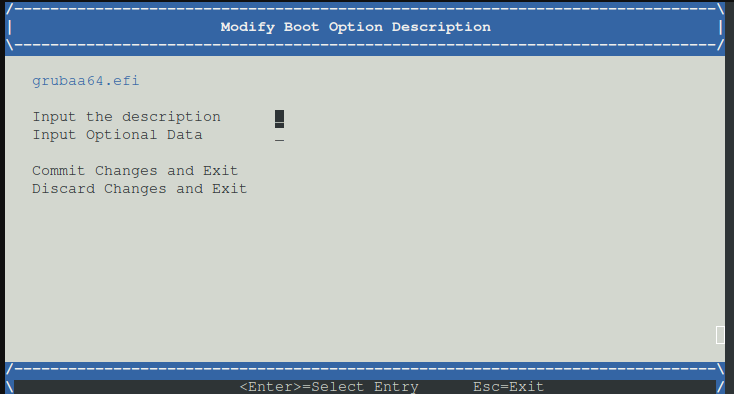
Nun eine Beschreibung angeben durch drücken von enter
Nun die Beschreibung eingeben zum Beispiel debian und mit enter bestätigen dann auf commit changes and exit
Zurück im Menü Change Boot order auswählen
Nun enter drücken und mittels enter um die liste zu verändern.
Debian auswählen und mittels +/- Taste den eintrag nach oben schieben
Nun oben vor CDROm falls man doch nochmals von CD starten möchte
Nun auf enter drücken dann auf esc, dann ist man wieder im Boot Maintenance Menü.
Nun auf Go Back To Main Page
Nun esc drücken
jetzt sind wir wieder im Hauptmenü und dort reset auswählen.
Nun startet das Debian System von selbst. - Fertig








System als Template anlegen (Optional)
Beschreibung:
Da die installation einer arm64 VM lange dauert. Werden wir uns dieses Grundsystem als Template anlegen.
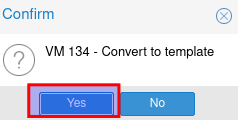
Template anlegen
DIe Machine stoppen falls sie noch nicht gestoppt ist.
Shutdown -> Stop
Rechtsklick auf dei VM und dann im Menü convert to template auswählen.

Die Frage mit ja beantworten
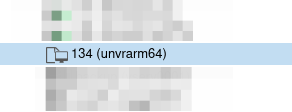
Nun haben wir die VM in ein Template umgewandelt.
Nun steht es hier in der Liste.
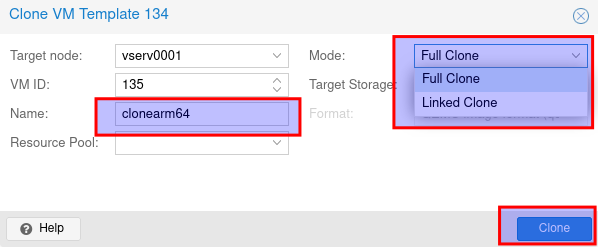
Eine VM aus dem Template erstellen
Rechtsklick auf das Template und clone auswählen

Nun Name ausfüllen zb: clonearm64
Mode : Full Clone oder Linked Clone
Ich nehme Full Clone, falls das Template mal nicht mehr bestehen sollte.
Fertig.
Proxmox - Benutzerverwaltung
Benutzer und Gruppe im Terminal anlegen
- Gruppe anlegen mit Admin Rechten
pveum group add admin -comment "System Administrators"Gruppe eine Rolle zuweisen
pveum acl modify / -group admin -role Administrator -
Nun einen Benutzeranlegen auf dem Realm PVE Server (PVE)
Realm PAM wäre ein Linux Benutzerpveum user add <username>r@pve --password <password>Möchte man im nach hinein nochmals das Kennwort ändern dann mittels Befehl
pveum passwd <username>@pveNun dem User die Gruppe admin zuweisen
pveum user modify stefanhacker@pve -group admin-
Proxmox - Hardware durchreichen in VM (KVM)
Um echte Hardware in die Virtuelle Machine durchzureichen (KVM)
Einschalten von vt-d für Intel CPUs (iommu)
Immou aktivieren für Intel CPUs. Hier wird unterschiedn ob es ein UEFI System oder legacy System ist mit oder ohne zfs.
Vorrausetzung ist das im BIOS alles mit vt-d eingeschlatet ist und somit das Mainboard und CPU das auch unterstützen.
Überpüfe welches System vorliegt
!!!!!VGA PASSTHROUGH funktioniert nur wenn das Host Betriebssystem im EFI Boot installiert wurde!!!!!
ls /sys/firmware/efiWenn kein Ergebnis vor liegt ist es BIOS legacy boot.
Unter Legacy Boot (also nicht EFI) in der Datei oder EFI ohne ZFS!
nano /etc/default/grubDort
GRUB_CMDLINE_LINUX_DEFAULT="quiet"zu
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=onändern und
update-grubausführen.
Unter EFI Boot mit ZFS in der Datei
nano /etc/kernel/cmdline Dort
root=ZFS=rpool/ROOT/pve-1 boot=zfszu
root=ZFS=rpool/ROOT/pve-1 boot=zfs intel_iommu=onändern und
pve-efiboot-tool refreshausführen.
Module beim start laden. Der Modules Datei anfügen
nano /etc/modulesvfio
vfio_iommu_type1
vfio_pci
vfio_virqfdWenn Grafikkarten durchgereicht werden sollen müssen noch die Treiber geblacklistet werden.
ansonsten kann dieser Teil übersprungen werden.
echo "blacklist radeon" >> /etc/modprobe.d/blacklist.conf
echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.conf
echo "blacklist nvidia" >> /etc/modprobe.d/blacklist.conf
update-initramfs -u
Hier gehts weiter. Wenn der Grafikkarten teil übersprungen wurde.
Nun die Machine neustarten. Ob iommu aktiv ist kann man mittels.
dmesg | grep IOMMUfestellen.
Ausgabe:
[ 0.028060] DMAR: IOMMU enabled
[ 0.090496] DMAR-IR: IOAPIC id 2 under DRHD base 0xfed90000 IOMMU 0
Sollte nichts ausgegeben werden, im bios nochmals schauen ob vt-d aktiv ist.
Nun iommu_unsafe_interruptssetzten
echo "options vfio_iommu_type1 allow_unsafe_interrupts=1" > /etc/modprobe.d/iommu_unsafe_interrupts.conf
update-initramfs -uFür ein Funktionieren pci passthroug müssen alle Geräte die in eine VM durchgereicht werden sollen in einer eigenen Gruppe befinden. Sprich alleine sein. Zur Not PCI Karte umstecken.
Um überhaupt seperate IOMMU Gruppen zu haben, must das feature ACS (Access Control Services, im BIOS aktiv sein.
find /sys/kernel/iommu_groups/ -type lAusgabe: In usn erem Beispiel ist es die 01:00, diese steckt aber noch mit 00:01.0
(00:01.0 PCI bridge: Intel Corporation 6th-10th Gen Core Processor PCIe Controller (x16) (rev 05)
in einer Gruppe.
Wenn PCI Karte umbauen nicht geht, so wie bei mir.
Dann dem grup loader noch
pcie_acs_override=downstream
Unter legancy
nano /etc/default/grub
update grub
Unter EFI
nano /etc/kernel/cmdline
pve-efiboot-tool refresh
und danach egal welches system
update-initramfs -u
mit geben.
Ausgabe ohne PCI KArte umsetzten oder grub Befehl Downstream
/sys/kernel/iommu_groups/7/devices/0000:00:1c.7
/sys/kernel/iommu_groups/5/devices/0000:00:1c.0
/sys/kernel/iommu_groups/3/devices/0000:00:16.0
/sys/kernel/iommu_groups/11/devices/0000:05:00.0
/sys/kernel/iommu_groups/1/devices/0000:00:01.0
/sys/kernel/iommu_groups/1/devices/0000:01:00.0
/sys/kernel/iommu_groups/1/devices/0000:01:00.1
/sys/kernel/iommu_groups/8/devices/0000:00:1f.2
/sys/kernel/iommu_groups/8/devices/0000:00:1f.0
/sys/kernel/iommu_groups/8/devices/0000:00:1f.3
/sys/kernel/iommu_groups/8/devices/0000:00:1f.4
/sys/kernel/iommu_groups/6/devices/0000:00:1c.5
/sys/kernel/iommu_groups/4/devices/0000:00:17.0
/sys/kernel/iommu_groups/2/devices/0000:00:14.2
/sys/kernel/iommu_groups/2/devices/0000:00:14.0
/sys/kernel/iommu_groups/10/devices/0000:03:00.0
/sys/kernel/iommu_groups/0/devices/0000:00:00.0
/sys/kernel/iommu_groups/9/devices/0000:02:00.0
Ausgabe mit grub parameter downstream. Es hat geklappt
/sys/kernel/iommu_groups/7/devices/0000:00:1c.7
/sys/kernel/iommu_groups/5/devices/0000:00:1c.0
/sys/kernel/iommu_groups/3/devices/0000:00:16.0
/sys/kernel/iommu_groups/11/devices/0000:03:00.0
/sys/kernel/iommu_groups/1/devices/0000:00:01.0
/sys/kernel/iommu_groups/8/devices/0000:00:1f.2
/sys/kernel/iommu_groups/8/devices/0000:00:1f.0
/sys/kernel/iommu_groups/8/devices/0000:00:1f.3
/sys/kernel/iommu_groups/8/devices/0000:00:1f.4
/sys/kernel/iommu_groups/6/devices/0000:00:1c.5
/sys/kernel/iommu_groups/4/devices/0000:00:17.0
/sys/kernel/iommu_groups/12/devices/0000:05:00.0
/sys/kernel/iommu_groups/2/devices/0000:00:14.2
/sys/kernel/iommu_groups/2/devices/0000:00:14.0
/sys/kernel/iommu_groups/10/devices/0000:02:00.0
/sys/kernel/iommu_groups/0/devices/0000:00:00.0
/sys/kernel/iommu_groups/9/devices/0000:01:00.0
/sys/kernel/iommu_groups/9/devices/0000:01:00.1
Die Grafikkarte ist jetzt unter der Gruppe 9 kann bei euch andersd sein . Zu der Grafikkarte gehören zwei Einträge.
/sys/kernel/iommu_groups/9/devices/0000:01:00.0
/sys/kernel/iommu_groups/9/devices/0000:01:00.1ff
VGA Grafikkarte in VM (KVM) durchreichen
Vorraussetzung wie im vorherigen Seite. Das auch die Grafikkarten geblacklistet wurden.
!!!!!VGA PASSTHROUGH funktioniert nur wenn das Host Betriebssystem im EFI Boot installiert wurde!!!!!
!!!!Wenn eine Onboard Grafikkarte verfügbar ist, diese als Primär im BIOS einstellen.!!!!!
Siehe: Einschalten von vt-d für Intel CPUs (iommu)
Eine VM Erstellen: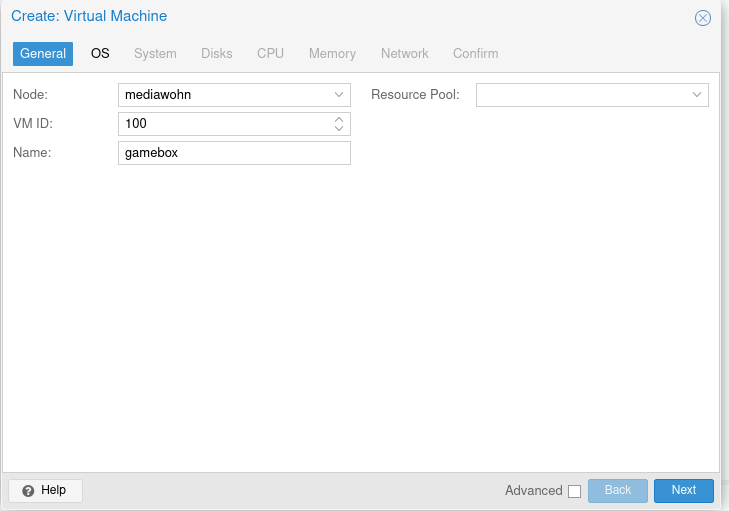
Nun ISO und OS auswählen, hier eine Windows 10 Machine mit ISO. Wenns ein Linux ist,linux auswählen.
Hier sind die Einstellungen egal.
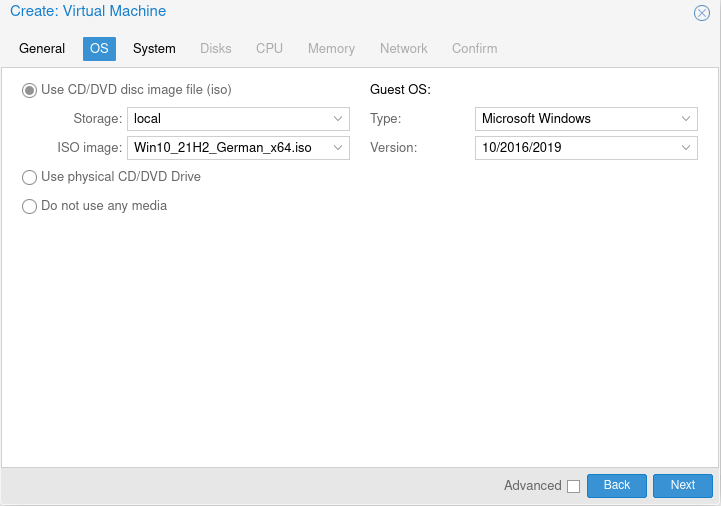
Hier:
Machine q53 auswählen.
BIOS : OVMF (UEFI) auswählen
Add EFI Disk : Haken rein
Storage dazu auswählen
Pre-Enroll-Keys : Haken rein
Qemu Agent : Haken rein
Add TPM : Haken rein
Storage dazu auswählen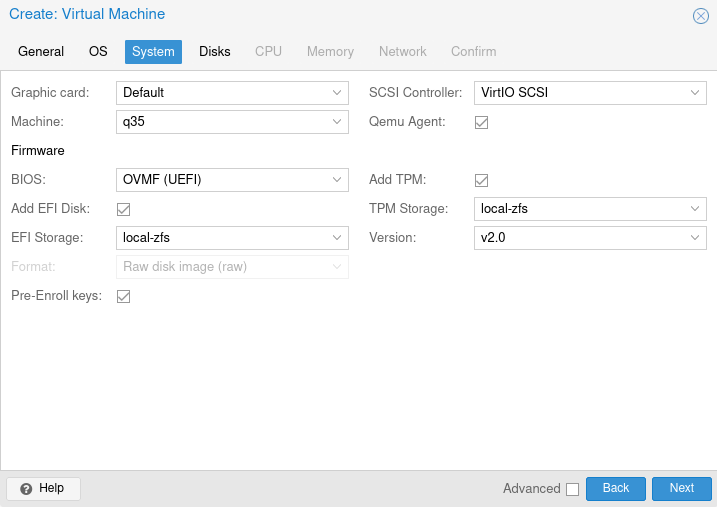
Nun wieder wie gehabt eine Festplatte zuweisen. Ich nehme hier virtio und 128 GB.
Denkt bei Windows dran, im Anschluss ein zweites CD/DVD Laufwerk mit den Virtio Treibern hinzuzufügen.
Download hier : https://github.com/virtio-win/virtio-win-pkg-scripts/blob/master/README.md
Die latest Stable und die guest tools sin im Anhang dieses Artikels.
Nun die CPU settings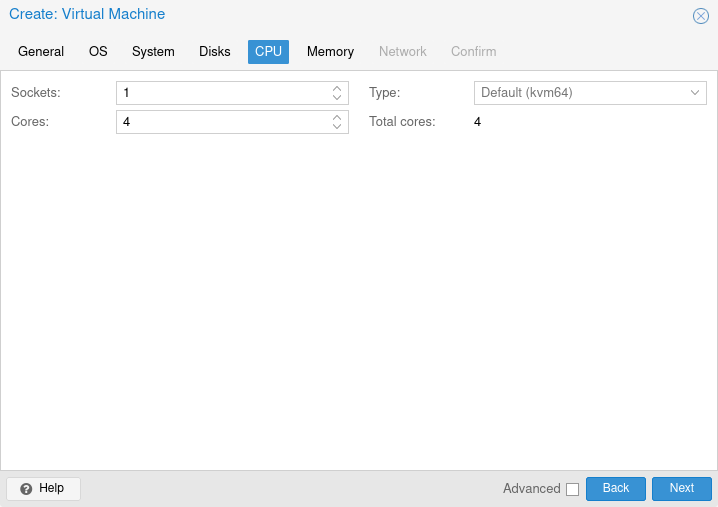
Memory Settings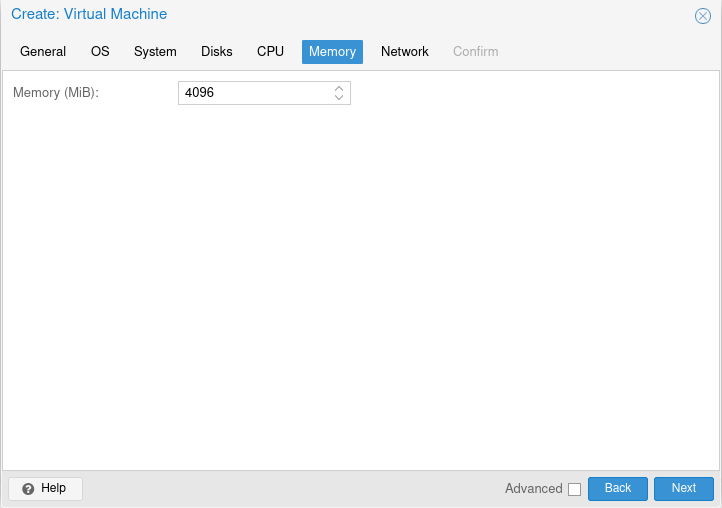
Network Settings.
Hier auf VirtIO stellen
Das schöne ist das Win 110/1 die Treiber nicht kennt und somit ein lokales Konto verwendet/erstellt werden kann,
Nun auf finisch, haken bei Start after creation raus.
Nun noch ein zweites CD/DVD Laufwerk erstellen für die VirtIO treiber. Aber nur nötig bei Windows VMS. sonst kann dieser Teil übersprungen werden.
Nun die Grafikkarte hinzufügen.
Dazu auf Add Hardware PCI, dann die Grafikkarte auswählen. mit der 0 bei der ID am ende.

Hier Haken bei :
All Funcktions rein
Primary GPU rein
Rom-BAR rein
PCI-Express rein
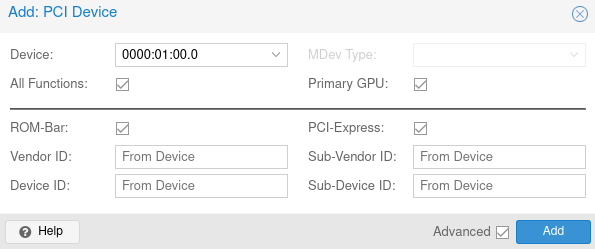
Damit die Graffikarte nicht geladen wird, müssen wir die IDs black listen.
Dazu erstmal die IDs bekommen.
Die bekommen wir mittels lspci -n -s 01:00
01:00 ist die erste PCI ID usnerer Graffikarte (Siehe Screenshot Grafikkarten auswahl in derVM
lspci -n -s 01:00
Ausgabe:
01:00.0 0300: 10de:1380 (rev a2)
01:00.1 0403: 10de:0fbc (rev a1)
Nun die Beiden IDS blacklisten. DIese IDS sind von der GPU und der Soundkarte auf der GPU (HDMI hat Sound)
echo "options vfio-pci ids=10de:1380,10de:0fbc" > /etc/modprobe.d/vfio.confDen Grub anhängen
initcall_blacklist=sysfb_init vfio_pci.ids=10de:1380,10de:0fbc iommu=pt vfio_iommu_type1.allow_unsafe_interrupts=1"In der GRUb conf hinzufügen
Für legacy
nano /etc/default/grub
update grubUnter EFI mit ZFS
Achtung in der cmdline kein gänsefüßchen am ende!!!!
nano /etc/kernel/cmdline
pve-efiboot-tool refreshhinzufügen
dann initrafs aktualisieren
update-initramfs -uFür Soundkartenasugabe kratzen verzerrung oder gar keinen Ton mehr
echo "options snd-hda-intel enable_msi=1" >> /etc/modprobe.d/snd-hda-intel.conf
Nun reboot, des Proxmox hosts.
rebootWenn alles geklappt hat sollte der Loginscreen nicht mehr kommen, sondern mitten im Boottext stecken bleiben, da die Grafikkarte hier abgewürgt wurde.
Nun nur noch die conf file der vm folgende Zeile am ende hinzufügen.
nano /etc/pve/qemu-server/<vmid>.conf
nano /etc/pve/qemu-server/100.conf ...
args: -cpu 'host,+kvm_pv_unhalt,+kvm_pv_eoi,hv_vendor_id=1234567890a4,kvm=off' -machine 'type=q35,kernel_irqchip=on'
Speichern.
Nun die Vm starten, voila oder aber nein Kein Bild.
Dann Fehlersuche hier
Fehlersuche
Wenn das Bild auf no signal bleibt.
In der /var/log/syslog schauen
tail -f /var/log/syslogHier der LOG Fehler. Bedeutet nicht im EFI Boot modus installiert der Host
Oct 21 16:15:57 mediawohn kernel: [ 32.695520] vfio-pci 0000:01:00.0: No more image in the PCI ROM
Oct 21 16:15:58 mediawohn pvedaemon[1616]: <root@pam> end task UPID:mediawohn:000007B2:00000C05:6352A99B:qmstart:100:root@pam: OK
Oct 21 16:15:59 mediawohn kernel: [ 34.964385] vfio-pci 0000:01:00.0: No more image in the PCI ROM
Oct 21 16:15:59 mediawohn kernel: [ 34.964435] vfio-pci 0000:01:00.0: No more image in the PCI ROM
weiterer Fehler:
Ab Kernel 5.15.+ muss in der grub conf video=efifb:off
durchinitcall_blacklist=sysfb_init
ersetzt werden
- Invalid PCI ROM header signature
- kernel: vfio-pci 0000:01:00.0: BAR 1: can't reserve [mem 0x4020000000-0x402fffffff 64bit pref]Jetzt bleibt nur noch Invalid PCI ROM header signature und cannot read device übrig
vfio-pci: Cannot read device rom at 0000:01:00.0
Oct 21 20:27:02 pve kernel: [ 298.009369] vfio-pci 0000:01:00.0: vfio_ecap_init: hiding ecap 0x1e@0x258
Oct 21 20:27:02 pve kernel: [ 298.009382] vfio-pci 0000:01:00.0: vfio_ecap_init: hiding ecap 0x19@0x900
Oct 21 20:27:02 pve kernel: [ 298.010765] vfio-pci 0000:01:00.0: Invalid PCI ROM header signature: expecting 0xaa55, got 0xffff
Bevor es weiter geht testen ob die Grafikarte UEFI OMFV fähig ist
apt install git gcc make
git clone https://github.com/awilliam/rom-parser
cd rom-parser
makeNun das rom aus der Grafikkarte holen ud testen
cd /sys/bus/pci/devices/0000:01:00.0/
echo 1 > rom
cat rom > /root/image.rom
echo 0 > rom
cd ~
cd rom-parser
./rom-parser /root/image.romAusgabe :
Hier ein Fehler, am ende.
Dies bedeutet das Auf das Rom nicht zugegriffen werden kann. In meinem Beispiel hab Ich legacy Boot.
Denn am einfachsten gets wenn das Hostsystem gleich als UEFI installiert ist.
Die gegenprobe mach ich noch. Also für die Grafikkarte ein VBIOS holen
alid ROM signature found @0h, PCIR offset 190h
PCIR: type 0 (x86 PC-AT), vendor: 10de, device: 1380, class: 030000
PCIR: revision 0, vendor revision: 1
Error, ran off the end
VBIOS holen:
unter https://www.techpowerup.com/vgabios/ sein passendes rom suchen.
Dann dort mit rechtsklick den Downlink undklicken und adresse kopiren meins liegt unter
https://www.techpowerup.com/vgabios/175522/Asus.GTX750Ti.2048.141104.rom
Nun per wget das image ablegen.
Wenn das passende rom nicht dabei selbst dumpen mit nvflash
https://www.techpowerup.com/download/nvidia-nvflash/
Usage:
chmox +x nvflash
./nvflash --save <filename>ansonsten mit wget das richtige file holen, wenn bei techpowerup verfügbar.
Beispiel für meine File
wget -O /usr/share/kvm/gtx750ti2048m.bin https://www.techpowerup.com/vgabios/175522/Asus.GTX750Ti.2048.141104.romROM File ablegen unter
/usr/share/kvm/meinromfile.bin
Nun die vm conf anpassen und die romfile reinpacken ohnepfad nur den dateinamen
nano /etc/pve/qemu-server/1<VMID>.conf
nano /etc/pve/qemu-server/100.confDort an die vga Zeile anfügen
,romfile=vbios.bin
Beispiel:
,romfile=gtx750ti2048m.bin
hostpci0: 0000:01:00,pcie=1,x-vga=1,romfile=gtx750ti2048m.binNun an die Syslog hängen
tail -f /var/log/syslog
ff
Proxmox - Tools / BUG Fixes Workarounds / Tipps und Tricks
Hier kommen alle Themen Rund um Fehlerbehebungen und Workarounds rein
Proxmox 7 - Deutsche Windows ISO nach installation keine Netzwerkkarten nur Ausrufungszeichen
Bei einem Proxmox update auf Version 7 können keine neuen Netzwerkkarten hinzugefügt werden und wenn doch Fehler 53
klassenkonfiguration wird von windows noch eingerichtet
Siehe Schreenshot.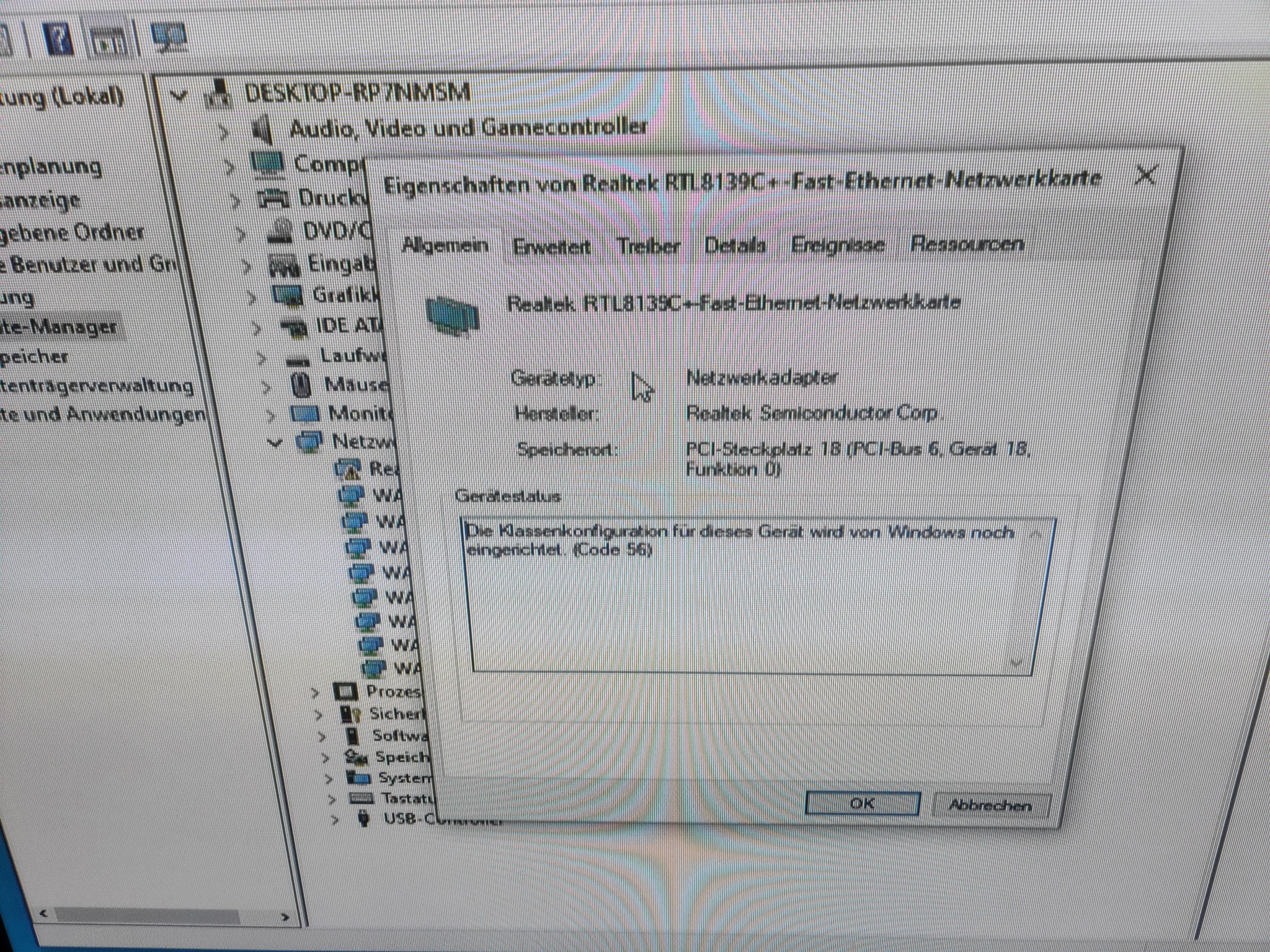
Abhilfe q35 auf version 5.1 umstellen.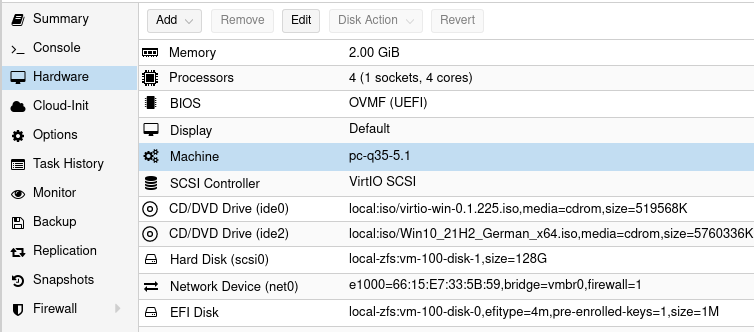
Beim neustart / starten könnte es einen Bluescreen geben.
einfach nochmals starten, läuft dann.
Fertig
Proxmox/Debian bei älteren Monitoren - Out of Range
Hat man am Server einen Monitor aus den 2000er angeschlossen und der unterstützt die akteullen modi nicht mehr.
Per SSH einloggen oder gleich nach der installation im grub nomodeset stezten.
Für GRUP legacy boot oder EFI ohne ZFS
nano /etc/default/grubFÜR EFI Boot mit ZFS
nano /etc/kernel/cmdlinehinter quiet einfach
nomodeset
schreiben
Beispiel
GRUB_CMDLINE_LINUX_DEFAULT="quiet nomodeset"
solltet ihr noch mehr custom paremter haben stehen die natürlich dahinterzum Schluss für legacy oder nur efi
update-grubfür EFI mit ZFS
pve-efiboot-tool refreshDann den Server neustarten fertig.
Nun haben wir auch endlich Bild mit nem alten Monitor
Proxmox ZFS Offline Mount mit PVE Install DVD/STICK
Beschreibung
Wie oft hat man das Problem zum Beispiel einen Proxmoxhost wo die Grafikkarte durchgereicht ist und so die Bedienung mit Tastatur und Maus nicht möglich ist. Es war immer nur möglich den Host per ssh und Weboberfläche zu steuern.
Jetzt kommt ein ein neues Mainboard oder neue Grafikkarte rein und schon ändert sich der Name der Netzwerkkarte.
Und nun? Mit der PVE DVD Starten das ZFS Mounten die Netzwerkkonfig ändern undfertig.
DVD Starten
Von der PVE Install DVD/Stick starten und den Debug Mode auswählen.

Nun sind wir in einem Debug Terminal.
in diesem können wir aber noch nicht wirkliche Befhele absetzten.
Deswegen hier mit STRG+D drücken um in das zweite Terminal zu gelangen.
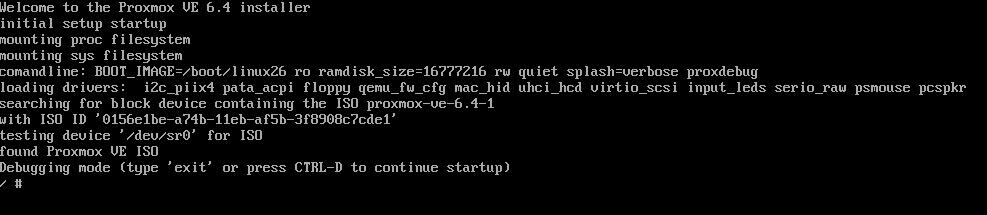
Hier können wir nun Befehle absetzten.
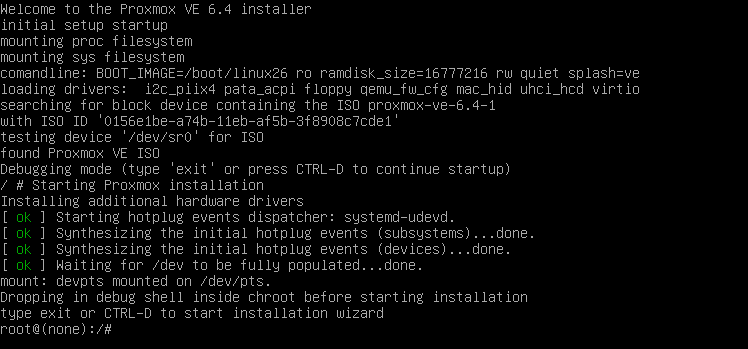
Netzwerkkarte ermitteln und Tastatursprache festlegen
Als erstes wollen wir wissen wir wissen wie unsere Netzwerkkarte heißt, das hat zwar nichts mit ZFS zu tun, allerings soll es hier ja auch einen Sinn machen.
ip aIn unserem Beispiel ens18

Die Tastaursprache legen wir mit
dpkg-reconfigure keyboard-configurationfest.
Nun werden wir nach dem Tastaturmodell gefragt.
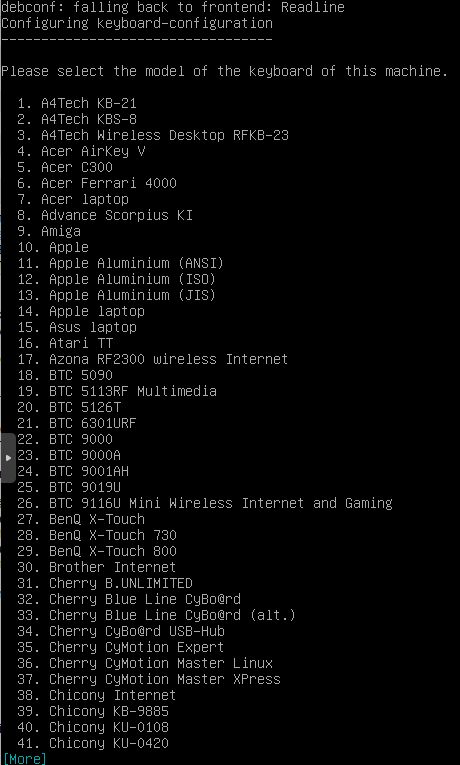
Mit Enter gehts auf die nächste Seite. Ich nehme die 71 Generic 105 intl..
Solange enter drücken bis Keyboardmodel dort steht, 71 eintippen enter drücken
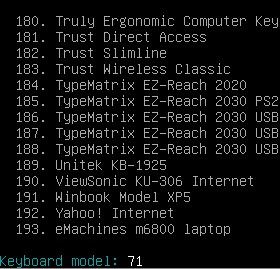
Nun das Layout, hier die 11 keine toten Tasten
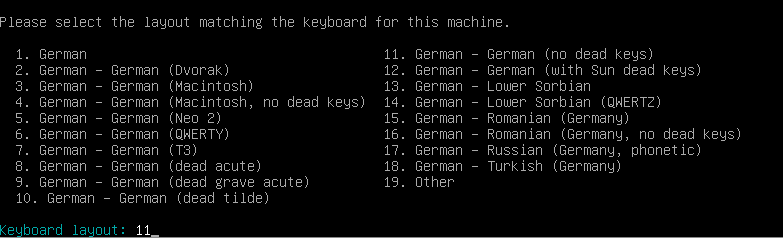
Nun ALT-GR Funktionstaste hier standard 1 wählen

Nun den Compose Key wählen (Ich habe keinen) da eure Einstellung wählen.
Also bei mir die 1

Da wir keinen X-Server haben hier nein (no) wählen

Vielleicht klappts bei euch bir mir nicht.
Legende für English
\ = #
- = ß
/ = -
? = shift + -
z = y
y = z
* = shift + 8
@ = shift + 2
# = shift + 3
^ = shift + 6
& = shift + 7
( = shift + 9
) = shift + 0
_ = shift + ß
: = shift + ö
ZFS einbinden
Pools auflisten.
Mit diesem Befehl werden alle pools aufgelistet ohne diese zu importieren. Villeicht möchte man ja nur einen bestimmten pool importieren. Wir haben hier nur einen. nämlich rpool.
zpool import -aHier bekommen wir nämlcih einen Hinweis, das der Pool schon mal woanders gemountet war. Diese machen wir uns zu nutze um die Pools aufzulisten.

Möchte man explicit einen pool importieren gibt man dessen namen an und nicht -a
zpool import rpoolDie selbe Meldung halt nur für den Pool

Da wir diesen aber importieren wollfen den Paramter -f hinter her.
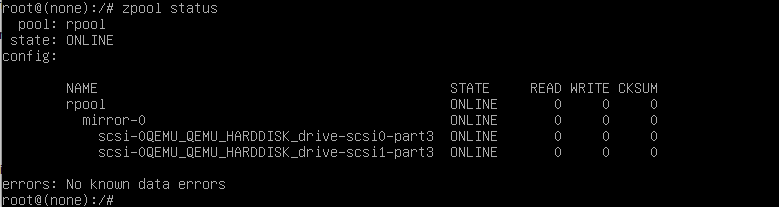
zpool import rpool -fNun schauen wir uns den Status an
zpool statusDem Pool gehts gut
Mit dem Befehl
mountsehen wir, wo er den Pool gemountet hat. Diese mount points unbedingt merken.
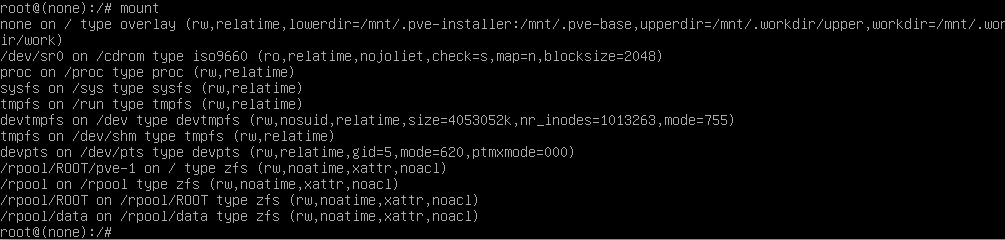
Das gleiche geht auch mit
zfs list
Wie wir sehen ist der PVE-1 eigentlich auf / gemountet, was natürlich nicht geht, da ja schon / vom system vergeben ist.
Also müssen wir den Mountpoint umbiegen
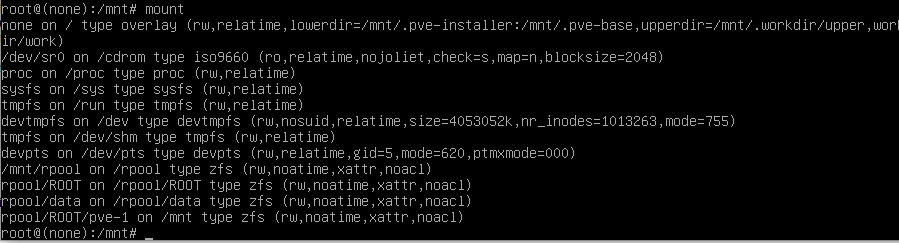
zfs set mountpoint=/mnt rpool/ROOT/pve-1
Nun wurde das Verzeichnis geremounted. Siehe mittels
mount
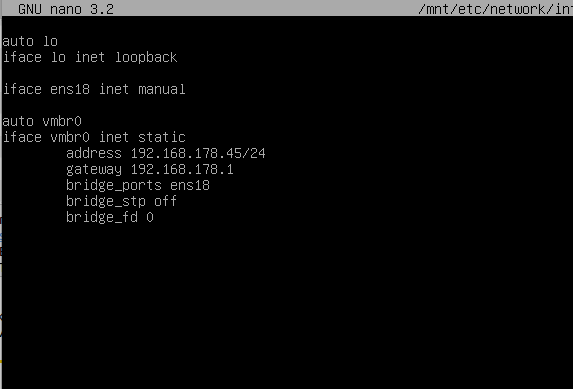
Nun können wir zum Beispiel die Netzwerkkarte editieren.
Das root Verzeichnis vom ZFS Pool wurde in /mnt gemountet
nano /mnt/etc/network/interfacesTadaaa unsere Netzwerk konfig. Diese oder noch andere sachen ändern
und zum Schluss den Mountpoint wieder zrucüksetzen auf /
Dazu auf / wechseln, denn das Verzeichnis darf nicht offen sein
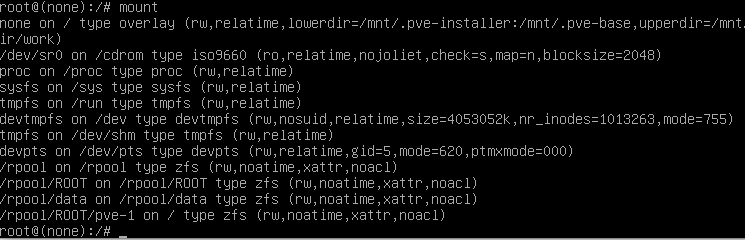
cd /Nun zurücksetzten
zfs set mountpoint=/ rpool/ROOT/pve-1Mit
mountnochmals überprüfen.
Passt. Fertig.
neustarten mit STRG+D
und dann abort auswählen.

Nun im Terminal wieder STRG+D drücken
Das System startet neu.
Beim Starten bekommen wir wieder den Hinweis das der pool fremdimportiert wurde.
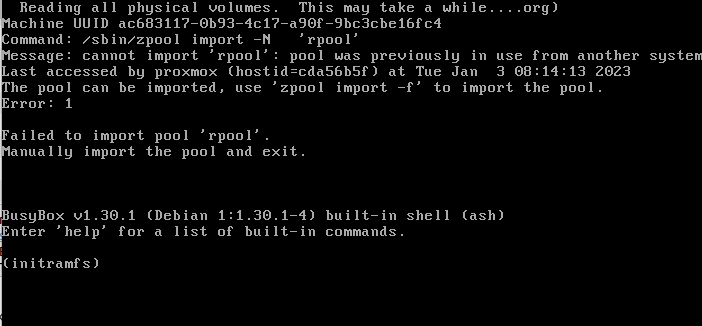
Wie in der Beschreibung ja auch zu lesen
zpool import rpool -f

Nun wieder STRG+D
Und die Kiste läuft.
Jetzt einloggen und nochmal neustarten.
Läuft so durch
fertig
LXC Conatiner startet nach Installation einer Software die als Dienst startet nicht mehr. (AppArmor)
Beschreibung
LXC Conatiner startet nach Installation einer Software die als Dienst startet nicht mehr.
So sieht das Bild aus. Einfach ein schwarzes terminal wo wir reinschreiben können.
Vorbereitung
Damit wir info bekommen, warum das ding nicht startet müssen wir in den Option des Containers die Console von tty auf Console umstellen.
Dazu auf Optionen des Containers und Doppelklick auf Console
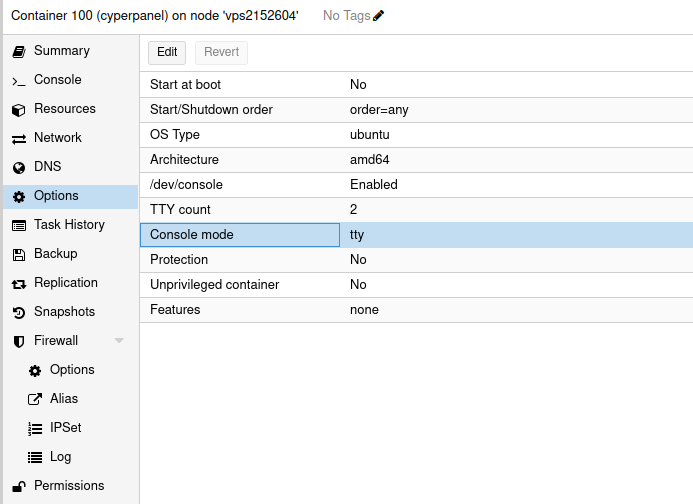
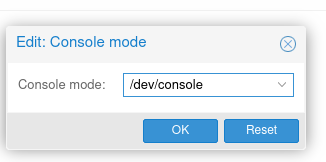
Nun aus der Liste /dev(console auswählen und ok
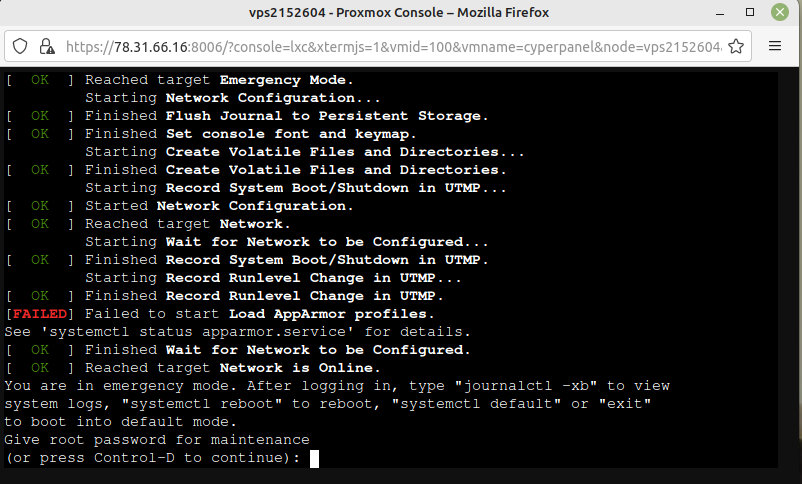
Wenn wir jetzt den Container neu starten und ein neues Konsolenfenter aufmachen bekommen wir infos.
Nun melden wir uns mit unserem Kennwort an und sheen wir sind als root eingeloggt
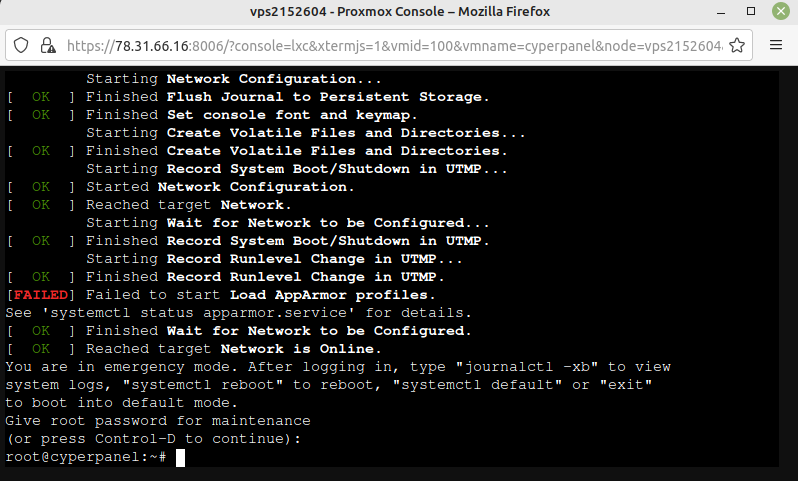
Nun mit journalctl -xe schauen was Sache ist. Dazu scrollen wir hoch bis zum Fehler.
emd[86]: /sbin/apparmor_parser: Unable to replace "lsb_release". Permission de>
emd[93]: /sbin/apparmor_parser: Unable to replace "/usr/bin/man". Permission d>
emd[92]: /sbin/apparmor_parser: Unable to replace "/usr/lib/NetworkManager/nm-d>
emd[96]: Skipping profile in /etc/apparmor.d/disable: usr.sbin.rsyslogd
emd[94]: /sbin/apparmor_parser: Unable to replace "tcpdump". Permission denied>
emd[118]: /sbin/apparmor_parser: Unable to replace "lsb_release". Permission d>
emd[121]: /sbin/apparmor_parser: Unable to replace "kmod". Permission denied; >
emd[121]: /sbin/apparmor_parser: Unable to replace "nvidia_modprobe". Permissi>
emd[133]: /sbin/apparmor_parser: Unable to replace "/usr/bin/man". Permission >
emd[131]: /sbin/apparmor_parser: Unable to replace "/usr/lib/NetworkManager/nm->
emd[139]: Skipping profile in /etc/apparmor.d/disable: usr.sbin.rsyslogd
emd[135]: /sbin/apparmor_parser: Unable to replace "tcpdump". Permission denie>
emd[77]: Error: At least one profile failed to load
pparmor.service: Main process exited, code=exited, status=1/FAILURE
scroll right
replace "lsb_release". Permission denied; attempted to load a profile while >
o replace "/usr/bin/man". Permission denied; attempted to load a profile while>
o replace "/usr/lib/NetworkManager/nm-dhcp-client.action". Permission denied; >
or.d/disable: usr.sbin.rsyslogd
o replace "tcpdump". Permission denied; attempted to load a profile while conf>
to replace "lsb_release". Permission denied; attempted to load a profile while>
to replace "kmod". Permission denied; attempted to load a profile while confin>
to replace "nvidia_modprobe". Permission denied; attempted to load a profile w>
to replace "/usr/bin/man". Permission denied; attempted to load a profile whil>
to replace "/usr/lib/NetworkManager/nm-dhcp-client.action". Permission denied;>
mor.d/disable: usr.sbin.rsyslogd
to replace "tcpdump". Permission denied; attempted to load a profile while con>
led to load
scroll right
ied; attempted to load a profile while confined?
nied; attempted to load a profile while confined?
cp-client.action". Permission denied; attempted to load a profile while confin>
attempted to load a profile while confined?
nied; attempted to load a profile while confined?
ttempted to load a profile while confined?
n denied; attempted to load a profile while confined?
enied; attempted to load a profile while confined?
hcp-client.action". Permission denied; attempted to load a profile while confi>
; attempted to load a profile while confined?
In dem Conatiner dann apparmor deaktivieren
systemctl disable apparmorDann sollte die Kiste starten.
Allerdings rate ich genau wegen solchen Dingen von Containern ab und empfehle KVM in Verbindung mit cloudinit.
Proxmox Wartungsmodus / Maintenance Mode - Diasable / Enable VMS at Start
Beschreibung
Man möchte den Server mehrmals neustarten, dann nervt es doch, wenn alle VMs/CTs mit starten.
Mit folgendem Script kann man das ein und auschalten
Installation des scripte
Auf den Server einloggen (sollte es ein Cluster sein, braucht das nur auf eine Node gepackt werden)
Nun eine Neue Datei erstellen
nano /root/save_boot_state.shDen Inhalt einfügen
#!/bin/bash
# boot-save-disable.sh
# Speichert alle onboot=1 VMs/CTs und deaktiviert sie
SAVEFILE="/root/boot-state.txt"
> "$SAVEFILE"
echo "=== Speichere Boot-Status ==="
for conf in /etc/pve/qemu-server/*.conf /etc/pve/lxc/*.conf; do
[ -f "$conf" ] || continue
if grep -q "^onboot: 1" "$conf"; then
id=$(basename "$conf" .conf)
type="vm"
[[ "$conf" == *"/lxc/"* ]] && type="ct"
echo "$type $id" >> "$SAVEFILE"
sed -i 's/^onboot: 1/onboot: 0/' "$conf"
echo " Deaktiviert: $type $id"
fi
done
echo ""
echo "Gespeichert in: $SAVEFILE"
echo "$(wc -l < "$SAVEFILE") Einträge"
Ausführbar machen
chmod +x /root/save_boot_state.shWiederherstellung Script
nano /root/restore-boot-state.shInhalt
#!/bin/bash
# boot-restore.sh
# Stellt onboot=1 für alle gespeicherten VMs/CTs wieder her
SAVEFILE="/root/boot-state.txt"
if [ ! -f "$SAVEFILE" ]; then
echo "Fehler: $SAVEFILE nicht gefunden!"
exit 1
fi
echo "=== Stelle Boot-Status wieder her ==="
while read -r type id; do
if [ "$type" = "vm" ]; then
conf="/etc/pve/qemu-server/${id}.conf"
else
conf="/etc/pve/lxc/${id}.conf"
fi
if [ -f "$conf" ]; then
if grep -q "^onboot:" "$conf"; then
sed -i 's/^onboot: 0/onboot: 1/' "$conf"
else
echo "onboot: 1" >> "$conf"
fi
echo " Aktiviert: $type $id"
else
echo " FEHLER: $conf nicht gefunden"
fi
done < "$SAVEFILE"
echo ""
echo "Fertig."Ausführbar machen
chmod +x /root/restore_boot_state.shStatus script
nano /root/status_boot_state.shInhalt
#!/bin/bash
# boot-status.sh
# Zeigt aktuellen onboot-Status aller VMs/CTs
SAVEFILE="/root/boot-state.txt"
echo "=== Aktueller onboot-Status ==="
echo ""
printf "%-6s %-6s %-8s %s\n" "Typ" "ID" "onboot" "Name"
echo "-------------------------------------"
for conf in /etc/pve/qemu-server/*.conf /etc/pve/lxc/*.conf; do
[ -f "$conf" ] || continue
id=$(basename "$conf" .conf)
type="vm"; [[ "$conf" == *"/lxc/"* ]] && type="ct"
name=$(grep "^name:" "$conf" | awk '{print $2}')
[ -z "$name" ] && name=$(grep "^hostname:" "$conf" | awk '{print $2}')
onboot=$(grep "^onboot:" "$conf" | awk '{print $2}')
[ -z "$onboot" ] && onboot="0"
printf "%-6s %-6s %-8s %s\n" "$type" "$id" "$onboot" "${name:-}"
done
echo ""
if [ -f "$SAVEFILE" ]; then
echo "Gespeicherte Einträge in $SAVEFILE: $(wc -l < "$SAVEFILE")"
else
echo "Kein Savefile vorhanden ($SAVEFILE)"
fiAusführbar machen
chmod +x /root/status_boot_state.sh
Proxmox Host aus VM herunterfahren
Beschreibung
Es gibt Situtationen, zum Beispiel bei einer VM mit durchgereichter Grafikkare und USB Ports, wo man den ganzen Host mit einem Doppelklick oder einem Befehl gerne herunterfahren möchte.
Damit die VMs auch das Signal bekommen zum herunterfahren muss der qemu Agent installiert sein.
Siehe : Proxmox - Qemu Agent installation
Proxmox aus einer Windows VM herunterfahren
Als erstes downloaden wir uns plink von der putty Seite.
https://www.putty.org
Nun auf Download klicken

Dort nun runterscrollen bis wir bei plink.exe ankommen.
Dort für eure Architektur plink.exe anklicken

Da ich ein 64 Bit Windows habe, nehme ich 64bit x86 und klicke es an.
Nun klicken wir aud das Ordnersymbol neben dem download
Nun öffnet sich der Download Ordner

Wir schneiden die plink exe aus
und legen sie in Program Files wieder ein
Drücken dann auf fortsetzen
Nun liegt die plink.exe im Programmverzeichnis.
Nun legen wir eine neue Verknüpfung auf dem Desktop an.
Rechtklick auf den Desktop -> Neu -> Verknüpfung
Nun auf den Durchsuchen button klicken
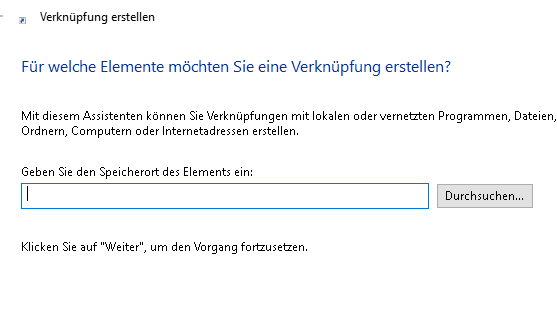
Nun AUf Dieser PC -> Laufwerk C-> Proragmme gehen
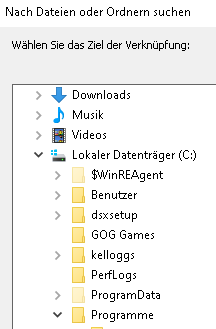
Nun runterscrollen bis plink.exe

Nun auf OK
Nun steht der Pfad dazu im Textfeld, hier noch NICHT auf weiter klicken, weil wir plink ein paar Paramter übergeben wollen
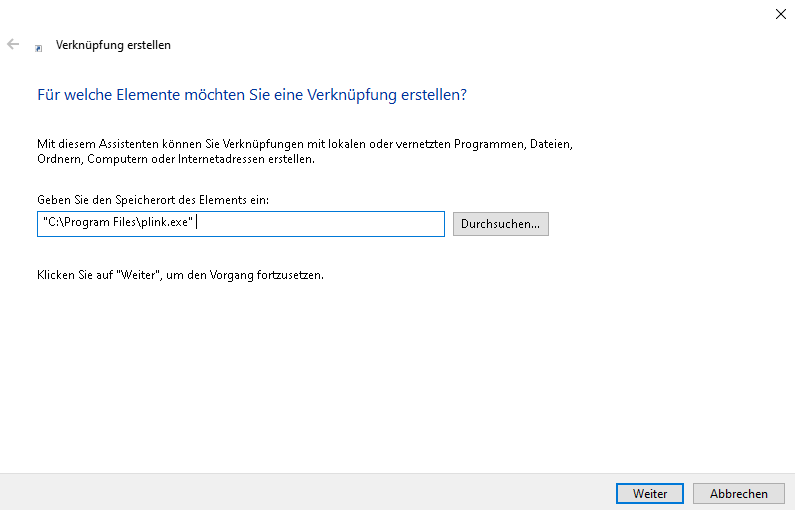
Diese wären
"C:\Program Files\plink.exe" -ssh -pw <proxmoxpasswort> root@<proxmoxhost> poweroff
Beispiel: "C:\Program Files\plink.exe" -ssh -pw 12345678 root@192.168.0.100 poweroffDann sähe das so aus, und nun auf weiter
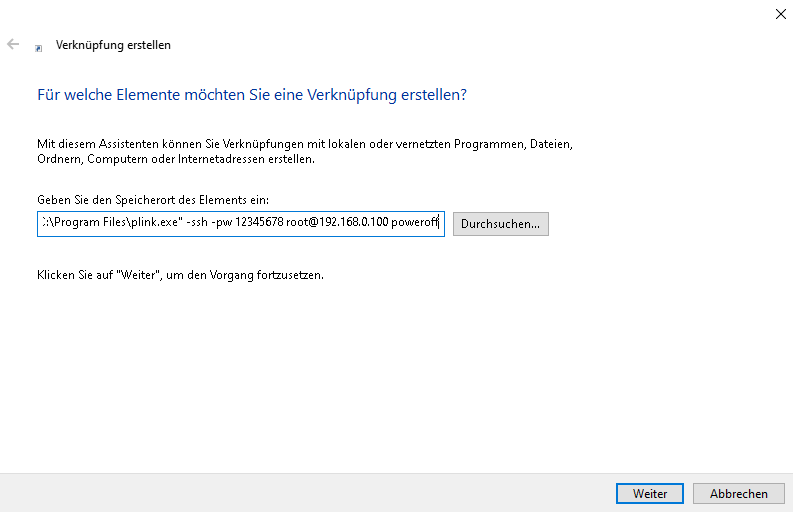
Jetz dem Kind noch ein Namen geben zum Beispiel Herunterfahren und dann auf Fertigstellen klicken
Nun haben wir eine Verknüpfung mit herunterfahren.
Doppelklick drauf dier Proxmoxhost fährt runter und beendet die VMs

Nun kommt die Frage ob der Key im cache store gespeichert werden soll. Mit y bestätigen
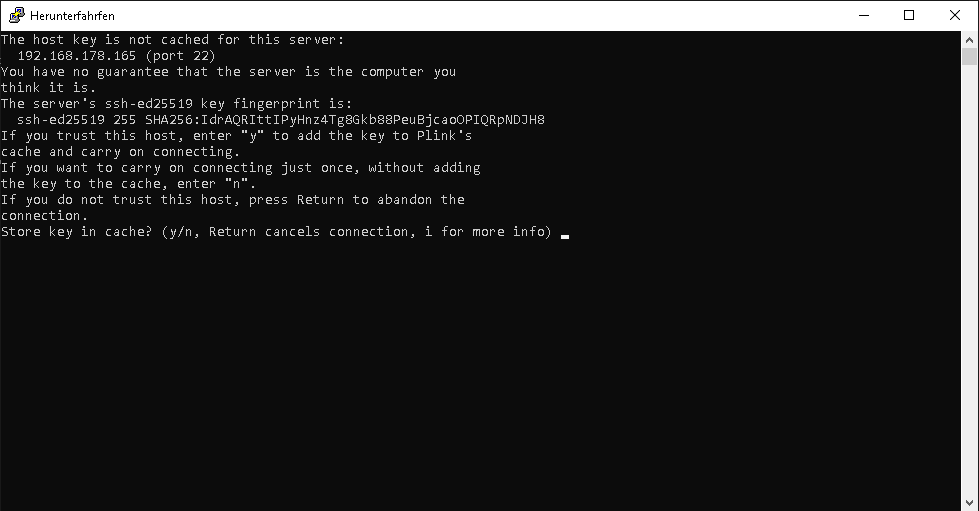
Nun kommt acces granted. Einfach enter drücken
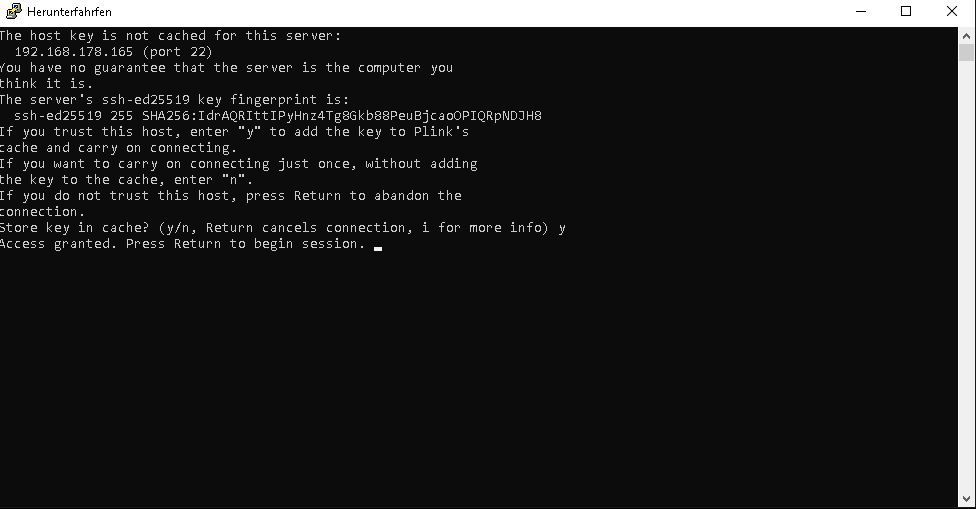
Nach jedem Ausführen kommt die frage ob ausgeführt werden soll. Einfach mit enter bestätigen.
nun fahren die VMs und dann der HOst herunter.
Proxmox - Es lassen sich keine Snapshots anlegen
Beschreibung:
Man hat einen proxmox Host und nur den Standard local-lvm Storage.
Aber aus irgendeinem Grund kann man keine Snapchots anlegen.
Fehler :
The current guest configuration does not support taking new snapshots
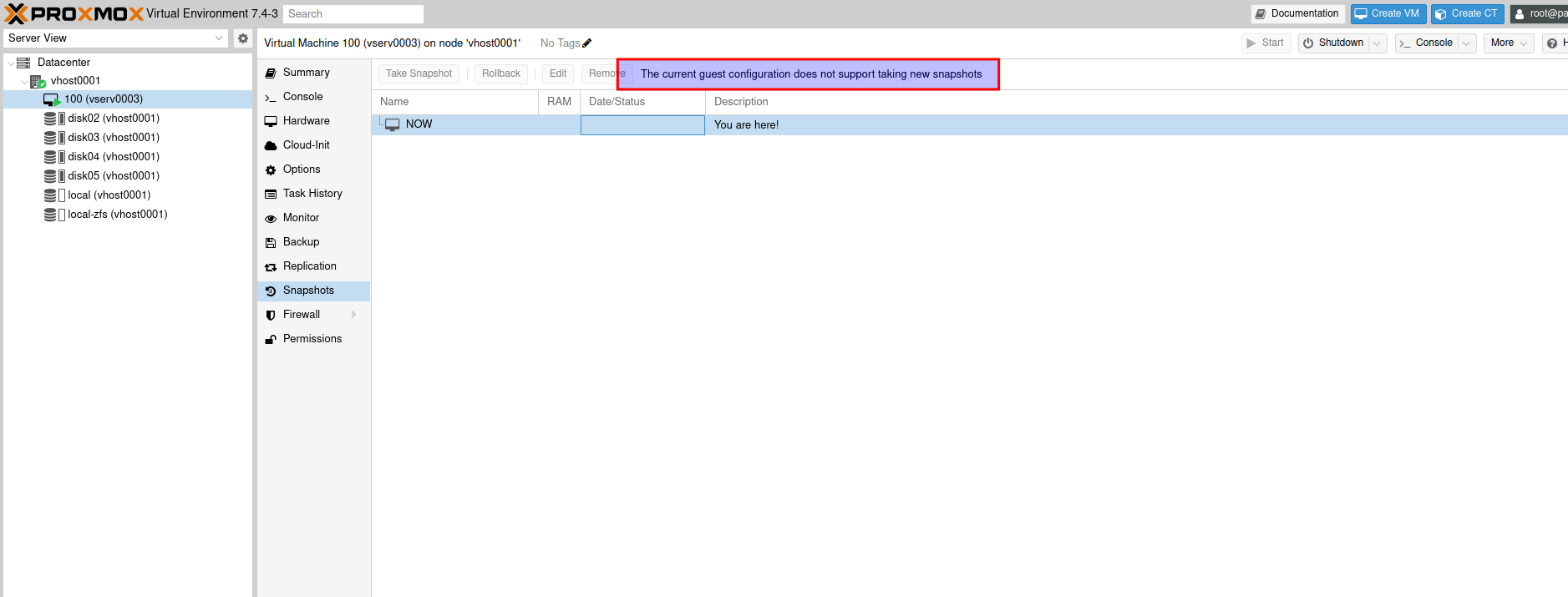
Vorrausetzungen für Snap-Shots:
-
Keine laufenden Migrationen oder Aufgaben: Wenn eine VM migriert oder andere Aufgaben ausgeführt werden, kann es nicht möglich sein, einen Snapshot zu erstellen. Sie müssen alle laufenden Aufgaben abschließen, bevor Sie einen Snapshot erstellen können.
-
Unterstützung auf Dateisystemebene: Das Dateisystem der VM muss Snapshots unterstützen. Zum Beispiel werden Snapshots auf der EXT4- und XFS-Dateisystemebene nicht unterstützt.
LVM-Thin (Nicht LVM, LVM ünterstützt keine Snapshots) und ZFS unterstützen jedoch Snapshots.
Ausnahme bei EXT4:Nur wenn das Disk-Image der VM im QCOW2-Format (QEMU Copy-On-Write) ist.
QCOW2 ist ein von QEMU entwickeltes Dateiformat, das Snapshots auf Dateiebene unterstützt. Diese Snapshots sind unabhängig vom zugrundeliegenden Dateisystem und funktionieren daher auf Ext4. Sie sind auch wesentlich flexibler und einfacher zu verwalten als LVM-Snapshots.
Bitte beachten Sie jedoch, dass das QCOW2-Format in einigen Situationen eine geringere Leistung aufweisen kann als RAW-Disk-Images oder LVM-basierte Speicher.
Es ist wichtig, die spezifischen Anforderungen und die Performance Ihrer Umgebung zu berücksichtigen, wenn Sie sich für ein Disk-Image-Format entscheiden. -
Disk-Konfiguration: In einigen Fällen kann die Konfiguration der VM-Festplatte die Erstellung von Snapshots verhindern. Zum Beispiel unterstützen Virtio-IDE uns SATA nicht das Erzeugen von Live-Snapshots (Snapshots, während die VM läuft).
-
QEMU-Gastagent: Der QEMU-Gastagent sollte installiert und laufend sein, wenn Sie versuchen, einen laufenden Snapshot zu erstellen (auch als Live-Snapshot bezeichnet). Der Gastagent ermöglicht eine bessere Interaktion zwischen dem Host und der VM, einschließlich der korrekten Verwaltung von Snapshots.
Wenn Ihre VM diese Anforderungen erfüllt, sollten Sie in der Lage sein, Snapshots zu erstellen. Wenn Sie trotzdem weiterhin Probleme haben, sollten Sie die Fehlermeldung und das VM-Setup genauer untersuchen.
Proxmox 7 installation hängt bei 99% make system bootable
Beschreibung:
Das System bleibt stehen bei 99% make System Bootable.
Bei einem Intel Board s5520hc soll das wohl standard so sein. Da das EFI broken ist.
Kann kein NVRAM schreiben.
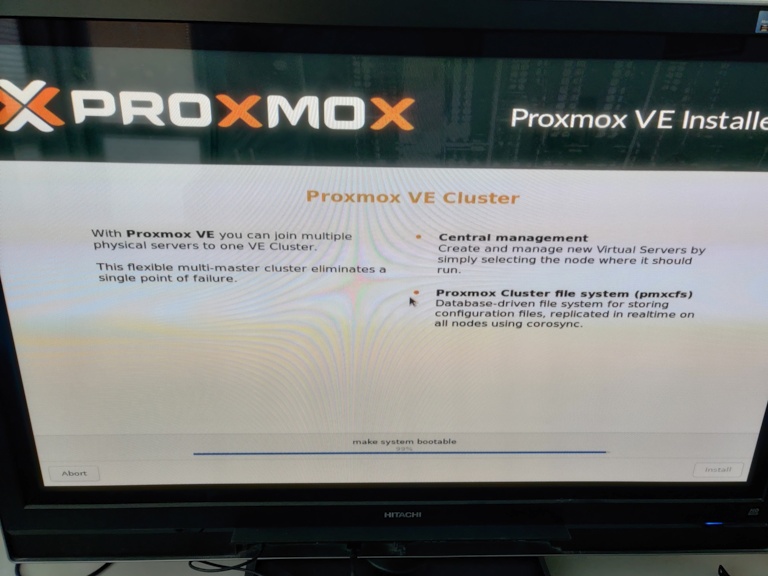
Was hab Ich probiert, sollte probiert werden:
Festplatte an Onboardcontroller gehängt -> kein Erfolg
Anderen Stick verwendet -> kein Erfolg
Proxmox 6.4 iso installtiert, dann inplace update durchgeführt -> kein Erfolg
(falls über Ventoy gebootet werden soll, hier wird die ISO nicht gefunden. Also vom Stick der mit Schreiber für Datenträger beschrieben wurde, sonst findet er die iso nicht)
Holzhammer Methode: Festplatte in anderen Rechner hängen, dort installieren.
Wieder zurückbauen, Netzwerkkonfig ändern. -> kein erfolg
Was brachte Erflog:
Installieren bis Fehler 99%
Dann ausschalten, von der Proxmox ISO Starten Advanced Debug Modus auswählen.
Dann STRG+D drücken damit ein System geladen wird.
Dann nochmals STRG+D damit ein System mit richtigem Terminal geladen wird
Dann nochmals STRG+D damit Netzwerk geladen wird un der Installer.
Dann im installer auf abort klciken
Nun sind wir wieder in der shell.
apt update
apt install openssh-server
Nun die sshd config anpassen
nano /etc/ssh/ssd_configund root zugriff erlauben
danach
service ssh restartNun das root Passwort neu setzten
passwdnun mit
ip aIP-Adresse ausgeben und per ssh verbinden.
Schlüsel akzeptierun, kennwort eingeben.
Wir sind drin ;-)
Nun den rpool mounten, wenn nichts zurück gegeben wird, hats geklappt
zpool import -f -R /mnt rpoolNun die Verzeichnisse mounten /dev /proc /sys
mount --rbind /dev /mnt/rpool/ROOT/pve-1/dev
mount --rbind /proc /mnt/rpool/ROOT/pve-1/proc
mount --rbind /sys /mnt/rpool/ROOT/pve-1/sysNun müssen wir noch unsere EFI Partion herausfinden.
in unserem Beispiel ist das Laufwerk sda, bei euch anpassen
gdisk /dev/sdaNun p drücken um die Partitionen angezeigt zu bekommen
isk /dev/sda: 937703088 sectors, 447.1 GiB
Model: KINGSTON SA400S3
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): E8AF2BF1-95B5-445D-89E4-E08361D101A3
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 937703054
Partitions will be aligned on 8-sector boundaries
Total free space is 0 sectors (0 bytes)
Number Start (sector) End (sector) Size Code Name
1 34 2047 1007.0 KiB EF02
2 2048 2099199 1024.0 MiB EF00
3 2099200 937703054 446.1 GiB BF01 Die Partition mit EF00 ist unsere Efi Boot Partition
in unserem Beispiel dann /dev/sda2
Nun mounten wir die Partition in /boot/efi unser chroot umgebung
mount /dev/sda2 /mnt/rpool/ROOT/pve-1/boot/efiDanach chrooten wir uns mit einer bash ins root Verzeichnis unserer Proxmox installtion
chroot /mnt/rpool/ROOT/pve-1 /bin/bashNun installieren wir endlich grub neu, aber ohne nv-ram
grub-install --no-nvramAusgabe:
root@proxmox:/# grub-install --no-nvram
Installing for x86_64-efi platform.
Installation finished. No error reported.
root@proxmox:/#
Grub aktualisieren
update-grubAusgabe, bedeutet er schaut nicht nach anderen systemen, diese werden nicht hinzugefügt
root@proxmox:/# update-grub
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.15.102-1-pve
Found memtest86+ image: /ROOT/pve-1@/boot/memtest86+.bin
Found memtest86+ multiboot image: /ROOT/pve-1@/boot/memtest86+_multiboot.bin
Warning: os-prober will not be executed to detect other bootable partitions.
Systems on them will not be added to the GRUB boot configuration.
Check GRUB_DISABLE_OS_PROBER documentation entry.
done
Dann exit.
Am richtigen Server wierder STRG+D drücken, dann startet der Server neu
aot install grub-efi-amd64
Nun haben wir ein System mit tools.
Dort den grubinstall neu konfiguriern
dpkg-reconfigure grub-efi-amd64
Nun herausfinden welche unsere EFI Partition ist.
lsblk -o +FSTYPEDie wählen wo VFAT steht, also /dev/sda2
Ausgabe:
Nun den rpool mounten
zpool import -f -R /mnt rpoolNun die Verzeichnisse mounten die wir brauchen
mount -o rbind /proc /mnt/rpool/ROOT/pve-1/proc
mount -o rbind /sys /mnt/rpool/ROOT/pve-1/sys
mount -o rbind /dev /mnt/rpool/ROOT/pve-1/dev
mount -o rbind /run /mnt/rpool/ROOT/pve-1/run
Nun in das root Verzeichnis vom pve-1 chrooten
chroot /mnt/rpool/ROOT/pve-1 /bin/bashJetzt den Bootloader neu installieren.
Dazu müssen wir vorher die EFI Partion mounten.
In meinem Beispiel ist das die 1GB partition
mount /dev/sda2 /mntNun können wir den Befehl zum Grub installieren absetzten
Anlegen / Clonen einer ARM64 VM Fehler
Beschreibung:
Ab Version 8.1 muss das Firmware Paket für arm64 manuell nachinstalliert werden.
Sonst bekommtman diesen Fehler:
TASK ERROR: clone failed: EFI base image '/usr/share/pve-edk2-firmware//AAVMF_CODE.fd' not foundLösung:
Folgendes Paket manuell installieren
apt install pve-edk2-firmware-aarch64Fertig.
nun lässt sich die VM wieder erstellen / clonen
LXC Conatiner - Routen beim start setzten,da post in interfaces nicht geht
Beschreibung:
leider unterstützen LCX keine einträge in der /etc/interfaces weil die bei jedem Start wieder gelöscht werden.
Abhilfe mit einem Systemd service
Einrichtung
Ein script erstellen was die route anlegt:
nano /usr/local/bin/set-routes.shInhalt
route add route add <zieladresse oder netz> gw <gateway> dev <netzwerkkarte>
route add 185.26.156.118 gw 222.222.0.7 dev eth1
bei einem netz sähe das so aus
bei einem 28er netz
route add 185.26.156.0/28 gw 222.222.0.7 dev eth1
bei einem 24 netz
route add 185.26.156.24 gw 222.222.0.7 dev eth1
also nun das script
#!/bin/bash
route add route add <zieladresse oder netz> gw <gateway> dev <netzwerkkarte>
Script ausführbar machen
chmod +x /usr/local/bin/set-routes.shNun einen Systemd Service Datei anlegen
nano /etc/systemd/system/set-routes.serviceInhalt:
[Unit]
Description=Set custom routes after network is up
After=network.target
[Service]
Type=oneshot
ExecStart=/usr/local/bin/set-routes.sh
RemainAfterExit=true
[Install]
WantedBy=multi-user.targetNun den systemctl neuladen den Dienst aktivieren und starten
systemctl daemon-reload
systemctl enable set-routes.service
systemctl start set-routes.serviceFertig
Ceph Upgrade von Pacific 17.2.7 auf reef 18.2.2 osd starten nicht
Beschreibung:
Beim Upgrade von 17.2.7 auf 18.2.2 starten die OSD nicht.
Lösung:
Erstmal auf 18.2.1 downgraden, dann warten bis die osds gestartet sind.
apt install ceph=18.2.1-pve2 ceph-mon=18.2.1-pve2 ceph-mgr=18.2.1-pve2 ceph-osd=18.2.1-pve2 ceph-mds=18.2.1-pve2 ceph-base=18.2.1-pve2 librados2=18.2.1-pve2 ceph-mgr-modules-core=18.2.1-pve2 libradosstriper1=18.2.1-pve2 libsqlite3-mod-ceph=18.2.1-pve2 librados2=18.2.1-pve2 librbd1=18.2.1-pve2 ceph-common=18.2.1-pve2 libcephfs2=18.2.1-pve2 python3-cephfs=18.2.1-pve2 python3-ceph-argparse=18.2.1-pve2 python3-ceph-common=18.2.1-pve2 python3-rados=18.2.1-pve2 python3-rbd=18.2.1-pve2 python3-rgw=18.2.1-pve2 librgw2=18.2.1-pve2 ceph-fuse=18.2.1-pve2 ceph-volume=18.2.1-pve2Nun die min version zurück auf quincy setzten
ceph osd require-osd-release quincyDanach leider die node neustarten, da aber eh alle OSDs offline sind, wäre das bei der Node auch egal.
Sollte das auch nicht gehen dann downgrade auf 17.2.7 zurück
apt install ceph=17.2.7-pve3 ceph-mon=17.2.7-pve3 ceph-mgr=17.2.7-pve3 ceph-osd=17.2.7-pve3 ceph-mds=17.2.7-pve3 ceph-base=17.2.7-pve3 librados2=17.2.7-pve3 ceph-mgr-modules-core=17.2.7-pve3 libradosstriper1=17.2.7-pve3 libsqlite3-mod-ceph=17.2.7-pve3 librados2=17.2.7-pve3 librbd1=17.2.7-pve3 ceph-common=17.2.7-pve3 libcephfs2=17.2.7-pve3 python3-cephfs=17.2.7-pve3 python3-ceph-argparse=17.2.7-pve3 python3-ceph-common=17.2.7-pve3 python3-rados=17.2.7-pve3 python3-rbd=17.2.7-pve3 python3-rgw=17.2.7-pve3 librgw2=17.2.7-pve3 ceph-fuse=17.2.7-pve3 ceph-volume=17.2.7-pve3Cpeh crash log löschen
Beschreibung:
Wenn ein Doamen crasht bleibt da in der log.
um diese zu lsöchen folgenden Befehl ausführen

Befehl:
To display a list of messages:
ceph crash ls
Wenn wir die Nachricht lesen wollen:
ceph crash info <id>
dann:
ceph crash archive <id>
or alle archivieren:
ceph crash archive-all
HDD Tray ermitteln LED blinken und/oder austauschen
Beschreibung:
Es gibt ein tolles Tool. Mit der man die LED zum Tray blinken lassen kann.
Noch ein kleines Script dazu wo man nur dass device angeben muss.Ein weiteres script zum Datenträger tausch.
Lässt slot blinken.
festplatte tauschen
Alte festplatte wird deregistriert und neue hinzugefügt.
LED ausgeschaltet.
BAM
Durchführung:
apt-get install -y lsscsi sg3-utilsFestplatten anzeigen lassen:
lsscsi -gAusgabe:
[1:0:0:0] cd/dvd Slimtype DVD A DS8ACSH LP5M /dev/sr0 /dev/sg17
[3:0:0:0] disk SEAGATE XS400ME70004 0004 /dev/sda /dev/sg0
[3:0:1:0] disk SEAGATE ST20000NM002D E004 /dev/sdb /dev/sg1
[3:0:2:0] disk WDC WUS721010AL5204 C980 /dev/sdc /dev/sg2
[3:0:3:0] disk SEAGATE ST20000NM002D E006 /dev/sdd /dev/sg3
[3:0:4:0] disk WDC WUS721010AL5204 C980 /dev/sde /dev/sg4
[3:0:5:0] disk SEAGATE ST20000NM002D E006 /dev/sdf /dev/sg5
[3:0:6:0] disk WDC WUS721010AL5204 C980 /dev/sdg /dev/sg6
[3:0:7:0] disk WDC WUS721010AL5204 C980 /dev/sdh /dev/sg7
[3:0:8:0] disk WDC WUS721010AL5204 C980 /dev/sdi /dev/sg8
[3:0:9:0] disk WDC WUS721010AL5204 C980 /dev/sdj /dev/sg9
[3:0:10:0] disk WDC WUS721010AL5204 C980 /dev/sdk /dev/sg10
[3:0:11:0] disk SEAGATE XS400ME70004 0004 /dev/sdl /dev/sg11
[3:0:12:0] disk WDC WUS721010AL5204 C980 /dev/sdm /dev/sg12
[3:0:13:0] disk WDC WUS721010AL5204 C980 /dev/sdn /dev/sg13
[3:0:14:0] disk WDC WUS721010AL5204 C980 /dev/sdo /dev/sg14
[3:0:15:0] disk WDC WUS721010AL5204 C980 /dev/sdp /dev/sg15
[3:0:16:0] enclosu BROADCOM VirtualSES 03 - /dev/sg16
[4:0:0:0] cd/dvd AMI Virtual CDROM0 1.00 /dev/sr1 /dev/sg18Script:
nano /usr/local/bin/identify-disk.shInhalt
#!/usr/bin/env bash
set -euo pipefail
usage() {
cat <<USAGE
Usage:
identify-disk [--on|--off|--blink SECONDS] [--symlink|--ses] [--all] [/dev/sdX|sdX|sdXn]
Optionen:
--on / --off / --blink SECONDS LED steuern
--symlink nur sysfs/enclosure_device* nutzen
--ses nur SES (sg_ses) nutzen
--all auf alle verfügbaren Slots anwenden
(ohne Methode) auto: erst symlink, dann SES-Fallback
Beispiele:
identify-disk --on sdi
identify-disk --blink 10 sdg8
identify-disk --off --symlink sdi
identify-disk --on --ses sdi
identify-disk --off --all # alle LEDs aus
identify-disk --blink 5 --all --symlink # alle via sysfs blinken
USAGE
}
MODE="on"
BLINK_SECS=0
METHOD="auto" # auto | symlink | ses
ALL=0
DISK=""
[[ $# -lt 1 ]] && { usage; exit 1; }
while [[ $# -gt 0 ]]; do
case "${1:-}" in
--on) MODE="on"; shift ;;
--off) MODE="off"; shift ;;
--blink) MODE="blink"; BLINK_SECS="${2:-}"; [[ -z "$BLINK_SECS" ]] && { echo "Fehlende Sekunden bei --blink"; exit 1; }; shift 2 ;;
--symlink) METHOD="symlink"; shift ;;
--ses) METHOD="ses"; shift ;;
--all) ALL=1; shift ;;
-h|--help) usage; exit 0 ;;
*)
DISK="$1"; shift ;;
esac
done
# ---------------------------
# Helpers (norm/req/printing)
# ---------------------------
need() { command -v "$1" >/dev/null 2>&1 || { echo "$1 fehlt. Bitte installieren."; exit 1; }; }
normalize_disk() {
local d="$1"
[[ "$d" =~ ^sd ]] && d="/dev/$d"
local base="$(basename "$d")"
local base_nopart="${base%%[0-9]*}"
echo "/dev/$base_nopart"
}
# --------------------------------------
# Einzel-Operationen (SYMLINK / per Disk)
# --------------------------------------
do_symlink_one() {
local disk="$1"
local base_nopart="$(basename "$disk")"
local p="/sys/class/block/${base_nopart}/device"
local enc=( "$p"/enclosure_device* )
[[ -e "${enc[0]}" ]] || { echo "Kein enclosure_device* für $disk gefunden."; return 2; }
local LOCATE="${enc[0]}/locate"
[[ -w "$LOCATE" ]] || { echo "'locate' nicht verfügbar/schreibbar unter ${enc[0]}."; return 3; }
local slot="$(cat "${enc[0]}/slot" 2>/dev/null || echo "")"
local slot_lbl=""; [[ -n "$slot" ]] && slot_lbl=" (Slot $slot)"
case "$MODE" in
on) echo 1 | sudo tee "$LOCATE" >/dev/null; echo "ON via sysfs$slot_lbl – $disk";;
off) echo 0 | sudo tee "$LOCATE" >/dev/null; echo "OFF via sysfs$slot_lbl – $disk";;
blink) echo 1 | sudo tee "$LOCATE" >/dev/null; echo "ON via sysfs$slot_lbl – $disk"; sleep "$BLINK_SECS"; echo 0 | sudo tee "$LOCATE" >/dev/null; echo "OFF via sysfs$slot_lbl – $disk";;
esac
}
# --------------------------------------
# Einzel-Operationen (SES / per Disk)
# --------------------------------------
do_ses_one() {
local disk="$1"
need lsscsi; need sg_ses
local LINE
LINE="$(lsscsi -g | awk -v d="$disk" '{if ($(NF-1)==d) {print; exit}}')"
[[ -n "$LINE" ]] || { echo "Konnte $disk nicht in 'lsscsi -g' finden."; return 6; }
local HOST BUS TARGET LUN
if [[ "$LINE" =~ \[([0-9]+):([0-9]+):([0-9]+):([0-9]+)\] ]]; then
HOST="${BASH_REMATCH[1]}"; BUS="${BASH_REMATCH[2]}"; TARGET="${BASH_REMATCH[3]}"; LUN="${BASH_REMATCH[4]}"
else
echo "Konnte SCSI-Adresse nicht parsen."; return 7
fi
local SES_LINE SES_DEV
SES_LINE="$(lsscsi -g | awk -v h="$HOST" -v b="$BUS" '$2=="enclosu" && $1 ~ ("\\["h":"b":"){print; exit}')"
[[ -n "$SES_LINE" ]] || { echo "Kein SES/Enclosure auf ${HOST}:${BUS} gefunden (HW-RAID? Hersteller-CLI nötig)."; return 8; }
SES_DEV="$(echo "$SES_LINE" | awk '{print $NF}')"
[[ -e "$SES_DEV" ]] || { echo "SES-Gerät existiert nicht: $SES_DEV"; return 9; }
local SAS_PATH="/sys/class/scsi_device/${HOST}:${BUS}:${TARGET}:${LUN}/device/sas_address"
[[ -r "$SAS_PATH" ]] || { echo "SAS-Adresse nicht lesbar: $SAS_PATH"; return 10; }
local DISK_SAS; DISK_SAS="$(tr -d '\n' < "$SAS_PATH")"
[[ -n "$DISK_SAS" ]] || { echo "Leere SAS-Adresse."; return 11; }
local INDEX SLOTNUM
read INDEX SLOTNUM < <(sg_ses -p aes "$SES_DEV" 2>/dev/null \
| awk -v want="$DISK_SAS" '
/Element index:/ {idx=$3; gsub(":","",idx); slot=""}
/device slot number:/ {slot=$5}
/SAS address:/ && $3 ~ /^0x/ {sas=$3; if (tolower(sas)==tolower(want)) {print idx, slot; exit}}
')
[[ -n "${INDEX:-}" ]] || { echo "Konnte SES-Index für $disk nicht ermitteln."; return 12; }
local slot_lbl=""; [[ -n "${SLOTNUM:-}" ]] && slot_lbl=" (Slot $SLOTNUM, idx $INDEX)" || slot_lbl=" (idx $INDEX)"
case "$MODE" in
on) sg_ses --index="$INDEX" --set=ident "$SES_DEV"; echo "ON via SES$slot_lbl – $disk";;
off) sg_ses --index="$INDEX" --clear=ident "$SES_DEV"; echo "OFF via SES$slot_lbl – $disk";;
blink) sg_ses --index="$INDEX" --set=ident "$SES_DEV"; echo "ON via SES$slot_lbl – $disk"; sleep "$BLINK_SECS"; sg_ses --index="$INDEX" --clear=ident "$SES_DEV"; echo "OFF via SES$slot_lbl – $disk";;
esac
}
# --------------------------------------
# ALL-Operationen (SYMLINK)
# --------------------------------------
do_symlink_all() {
local disks=()
for d in /sys/class/block/sd*; do
[[ -e "$d" ]] || continue
local name="$(basename "$d")"
[[ "$name" =~ [0-9]$ ]] && continue # nur Whole Disks
comp=( "$d"/device/enclosure_device* )
[[ -e "${comp[0]}" ]] || continue
disks+=( "/dev/$name" )
done
local n="${#disks[@]}"
[[ $n -gt 0 ]] || { echo "Keine sysfs/enclosure Slots gefunden."; return 2; }
if [[ "$MODE" == "blink" ]]; then
# Alle an, warten, alle aus
for disk in "${disks[@]}"; do
local loc=( "/sys/class/block/$(basename "$disk")/device"/enclosure_device*/locate )
[[ -w "${loc[0]}" ]] || continue
echo 1 | sudo tee "${loc[0]}" >/dev/null
local slot=""; [[ -r "${loc[0]%/*}/slot" ]] && slot="$(cat "${loc[0]%/*}/slot")"
echo "ON via sysfs$( [[ -n "$slot" ]] && echo " (Slot $slot)" ) – $disk"
done
sleep "$BLINK_SECS"
for disk in "${disks[@]}"; do
local loc=( "/sys/class/block/$(basename "$disk")/device"/enclosure_device*/locate )
[[ -w "${loc[0]}" ]] || continue
echo 0 | sudo tee "${loc[0]}" >/dev/null
echo "OFF via sysfs – $disk"
done
else
local val=$([[ "$MODE" == "on" ]] && echo 1 || echo 0)
for disk in "${disks[@]}"; do
local loc=( "/sys/class/block/$(basename "$disk")/device"/enclosure_device*/locate )
[[ -w "${loc[0]}" ]] || continue
echo $val | sudo tee "${loc[0]}" >/dev/null
local slot=""; [[ -r "${loc[0]%/*}/slot" ]] && slot="$(cat "${loc[0]%/*}/slot")"
echo "$( [[ $val -eq 1 ]] && echo ON || echo OFF ) via sysfs$( [[ -n "$slot" ]] && echo " (Slot $slot)" ) – $disk"
done
fi
}
# --------------------------------------
# ALL-Operationen (SES)
# --------------------------------------
do_ses_all() {
need lsscsi; need sg_ses
mapfile -t ENCS < <(lsscsi -g | awk '$2=="enclosu"{print $NF}')
[[ ${#ENCS[@]} -gt 0 ]] || { echo "Kein SES/Enclosure gefunden."; return 3; }
for SES_DEV in "${ENCS[@]}"; do
# Alle belegten Element-Indices sammeln (die eine SAS address haben)
mapfile -t IDX < <(sg_ses -p aes "$SES_DEV" 2>/dev/null \
| awk '
/Element index:/ {idx=$3; gsub(":","",idx); slot=""; has_sas=0}
/device slot number:/ {slot=$5}
/SAS address:/ && $3 ~ /^0x/ {has_sas=1}
has_sas && /SAS address:/ {print idx "|" slot}
')
[[ ${#IDX[@]} -gt 0 ]] || { echo "Keine befüllten Slots für $SES_DEV."; continue; }
if [[ "$MODE" == "blink" ]]; then
# alle an
for pair in "${IDX[@]}"; do
IFS='|' read -r index slot <<<"$pair"
sg_ses --index="$index" --set=ident "$SES_DEV" || true
[[ -n "$slot" ]] && echo "ON via SES (Slot $slot, idx $index) – $SES_DEV" || echo "ON via SES (idx $index) – $SES_DEV"
done
sleep "$BLINK_SECS"
# alle aus
for pair in "${IDX[@]}"; do
IFS='|' read -r index slot <<<"$pair"
sg_ses --index="$index" --clear=ident "$SES_DEV" || true
[[ -n "$slot" ]] && echo "OFF via SES (Slot $slot, idx $index) – $SES_DEV" || echo "OFF via SES (idx $index) – $SES_DEV"
done
else
local cmd=$([[ "$MODE" == "on" ]] && echo "--set=ident" || echo "--clear=ident")
for pair in "${IDX[@]}"; do
IFS='|' read -r index slot <<<"$pair"
sg_ses --index="$index" $cmd "$SES_DEV" || true
local state=$([[ "$MODE" == "on" ]] && echo ON || echo OFF)
[[ -n "$slot" ]] && echo "$state via SES (Slot $slot, idx $index) – $SES_DEV" || echo "$state via SES (idx $index) – $SES_DEV"
done
fi
done
}
# -----------------------
# Main-Dispatch
# -----------------------
if [[ $ALL -eq 1 ]]; then
case "$METHOD" in
symlink)
do_symlink_all
;;
ses)
do_ses_all
;;
auto)
# erst symlink-Variante probieren; wenn nichts gefunden, SES-all
if ! do_symlink_all; then
echo "(Auto) Fallback auf SES (alle)…"
do_ses_all
fi
;;
*) echo "Unbekannte Methode: $METHOD"; usage; exit 1 ;;
esac
exit 0
fi
# Einzel-Disk-Pfad (keine --all)
[[ -n "$DISK" ]] || { echo "Bitte /dev/sdX angeben oder --all nutzen."; exit 1; }
DISK="$(normalize_disk "$DISK")"
[[ -b "$DISK" ]] || { echo "Gerät nicht gefunden: $DISK"; exit 1; }
case "$METHOD" in
symlink)
do_symlink_one "$DISK" || exit $?
;;
ses)
do_ses_one "$DISK" || exit $?
;;
auto)
if do_symlink_one "$DISK"; then
exit 0
else
echo "(Auto) Fallback auf SES…"
do_ses_one "$DISK"
fi
;;
*)
echo "Unbekannte Methode: $METHOD"; usage; exit 1 ;;
esac
Ausführbar machen
chmod +x /usr/local/bin/identify-disk.shHilfe/Bedienung
Usage:
identify-disk [--on|--off|--blink SECONDS] [--symlink|--ses] [--all] [/dev/sdX|sdX|sdXn]
Optionen:
--on / --off / --blink SECONDS LED steuern
--symlink nur sysfs/enclosure_device* nutzen
--ses nur SES (sg_ses) nutzen
--all auf alle verfügbaren Slots anwenden
(ohne Methode) auto: erst symlink, dann SES-Fallback
Beispiele:
identify-disk --on sdi
identify-disk --blink 10 sdg8
identify-disk --off --symlink sdi
identify-disk --on --ses sdi
identify-disk --off --all # alle LEDs aus
identify-disk --blink 5 --all --symlink # alle via sysfs blinkenAlte Laufwerke entfernen:
Sobald alte Laufwerke entfernt werden, bleiben Sie tot in der Liste.
Erst Laufwerk entfernen. Dann neu einschieben.
Das machen wir wieder mit einem script. Das Script wartet solange bis wir die festplatte getauscht haben.
wenn getauscht bestätigen.
nano /usr/local/bin/scsi-hotswap.shInhalt
#!/usr/bin/env bash
set -euo pipefail
usage() {
cat <<USAGE
Usage:
scsi-hotswap [--method auto|symlink|ses] [--blink N|--no-led] [--no-prompt] /dev/sdX|sdX|sdXn
Optionen:
--method M M = auto (default) | symlink | ses
--blink N LED vor dem Tausch N Sekunden blinken (statt dauerhaft an)
--no-led keine LED-Steuerung
--no-prompt nicht auf ENTER warten (setze voraus, dass neue Platte schon steckt)
Beispiele:
scsi-hotswap sdi
scsi-hotswap --method symlink --blink 8 sdg8
scsi-hotswap --method ses --no-prompt sdm
USAGE
}
METHOD="auto" # auto | symlink | ses
BLINK_SECS=0 # 0 = steady on
USE_LED=1
PROMPT=1
[[ $# -lt 1 ]] && { usage; exit 1; }
while [[ $# -gt 0 ]]; do
case "${1:-}" in
--method) METHOD="${2:-}"; shift 2 ;;
--blink) BLINK_SECS="${2:-}"; [[ -z "$BLINK_SECS" ]] && { echo "Fehlende Sekunden bei --blink"; exit 1; }; shift 2 ;;
--no-led) USE_LED=0; shift ;;
--no-prompt) PROMPT=0; shift ;;
-h|--help) usage; exit 0 ;;
*) DISK="$1"; shift ;;
esac
done
# --- Device normalisieren ---
[[ "$DISK" =~ ^sd ]] && DISK="/dev/$DISK"
BASE="$(basename "$DISK")"
BASE_NOPART="${BASE%%[0-9]*}"
DISK="/dev/$BASE_NOPART"
[[ -b "$DISK" ]] || { echo "Gerät nicht gefunden: $DISK"; exit 1; }
need() { command -v "$1" >/dev/null 2>&1 || { echo "$1 fehlt. Bitte installieren."; exit 1; }; }
# --------------------------
# LED via sysfs (symlink-Weg)
# --------------------------
# merkt sich LOCATE_PATH_CACHED+SLOT_CACHED, damit "off" nach dem Swap immer klappt
LOCATE_PATH_CACHED=""
SLOT_CACHED=""
led_symlink() {
local mode="$1" # on|off|blink
local LOCATE_PATH=""
local SLOT=""
# bereits gecachten Pfad benutzen, wenn vorhanden
if [[ -n "$LOCATE_PATH_CACHED" && -e "$LOCATE_PATH_CACHED" ]]; then
LOCATE_PATH="$LOCATE_PATH_CACHED"
SLOT="$SLOT_CACHED"
else
local p="/sys/class/block/${BASE_NOPART}/device"
local enc=( "$p"/enclosure_device* )
[[ -e "${enc[0]}" ]] || return 2
LOCATE_PATH="${enc[0]}/locate"
[[ -w "$LOCATE_PATH" ]] || return 3
SLOT="$(cat "${enc[0]}/slot" 2>/dev/null || echo "")"
LOCATE_PATH_CACHED="$LOCATE_PATH"
SLOT_CACHED="$SLOT"
fi
local slot_label=""
[[ -n "$SLOT" ]] && slot_label=" (Slot $SLOT)"
case "$mode" in
on)
echo 1 | sudo tee "$LOCATE_PATH" >/dev/null
echo "LED an${slot_label} via sysfs – $DISK"
;;
off)
echo 0 | sudo tee "$LOCATE_PATH" >/dev/null
echo "LED aus${slot_label} via sysfs – $DISK"
;;
blink)
echo 1 | sudo tee "$LOCATE_PATH" >/dev/null
echo "LED an${slot_label} – blinke ${BLINK_SECS}s…"
sleep "$BLINK_SECS"
echo 0 | sudo tee "$LOCATE_PATH" >/dev/null
echo "LED aus."
;;
esac
return 0
}
# -------------------------------------------
# SES-Index + Slotnummer + SES-Device ermitteln (per SAS)
# -------------------------------------------
get_ses_index() {
# Outputs (echo): "<SES_DEV> <INDEX> <SLOTNUM> <HOST> <BUS> <TARGET> <LUN>"
need lsscsi; need sg_ses
local LINE
LINE="$(lsscsi -g | awk -v d="$DISK" '{if ($(NF-1)==d) {print; exit}}')"
[[ -n "$LINE" ]] || { echo "Konnte $DISK nicht in 'lsscsi -g' finden." >&2; return 1; }
if [[ "$LINE" =~ \[([0-9]+):([0-9]+):([0-9]+):([0-9]+)\] ]]; then
local HOST="${BASH_REMATCH[1]}" BUS="${BASH_REMATCH[2]}" TARGET="${BASH_REMATCH[3]}" LUN="${BASH_REMATCH[4]}"
else
echo "Konnte SCSI-Adresse nicht parsen." >&2; return 1
fi
local SES_LINE SES_DEV
SES_LINE="$(lsscsi -g | awk -v h="$HOST" -v b="$BUS" '$2=="enclosu" && $1 ~ ("\\["h":"b":"){print; exit}')"
[[ -n "$SES_LINE" ]] || { echo "Kein SES/Enclosure auf ${HOST}:${BUS} gefunden (HW-RAID?)." >&2; return 1; }
SES_DEV="$(echo "$SES_LINE" | awk '{print $NF}')"
[[ -e "$SES_DEV" ]] || { echo "SES-Gerät existiert nicht: $SES_DEV" >&2; return 1; }
local SAS_PATH="/sys/class/scsi_device/${HOST}:${BUS}:${TARGET}:${LUN}/device/sas_address"
[[ -r "$SAS_PATH" ]] || { echo "SAS-Adresse nicht lesbar: $SAS_PATH" >&2; return 1; }
local DISK_SAS; DISK_SAS="$(tr -d '\n' < "$SAS_PATH")"
[[ -n "$DISK_SAS" ]] || { echo "Leere SAS-Adresse." >&2; return 1; }
# In einem Durchlauf: Index + physische Slotnummer zu *dieser* Disk finden
local INDEX SLOTNUM
read INDEX SLOTNUM < <(sg_ses -p aes "$SES_DEV" 2>/dev/null \
| awk -v want="$DISK_SAS" '
/Element index:/ {idx=$3; gsub(":","",idx); slot=""}
/device slot number:/ {slot=$5}
/SAS address:/ && $3 ~ /^0x/ {sas=$3; if (tolower(sas)==tolower(want)) {print idx, slot; exit}}
')
# Fallback über physische Slotnummer aus sysfs (falls vorhanden)
if [[ -z "${INDEX:-}" || -z "${SLOTNUM:-}" ]]; then
local p="/sys/class/block/${BASE_NOPART}/device"
local enc=( "$p"/enclosure_device* )
if [[ -e "${enc[0]}" && -r "${enc[0]}/slot" ]]; then
local PHY_SLOT; PHY_SLOT="$(cat "${enc[0]}/slot" 2>/dev/null || true)"
if [[ -n "$PHY_SLOT" ]]; then
SLOTNUM="$PHY_SLOT"
INDEX="$(sg_ses -p aes "$SES_DEV" 2>/dev/null \
| awk -v slot="$PHY_SLOT" '
/Element index:/ {idx=$3; gsub(":","",idx)}
/device slot number:/ {if ($5==slot) {print idx; exit}}
')"
fi
fi
fi
# Es kann vorkommen, dass SLOTNUM leer bleibt → ist ok; dann nur Index nutzen
[[ -n "$INDEX" ]] || { echo "SES-Index konnte nicht ermittelt werden." >&2; return 1; }
echo "$SES_DEV" "$INDEX" "${SLOTNUM:-}" "$HOST" "$BUS" "$TARGET" "$LUN"
}
# -----------------------
# LED via SES (sg_ses)
# -----------------------
led_ses() {
local mode="$1" SES_DEV="$2" INDEX="$3" SLOTNUM="${4:-}"
need sg_ses
local slot_label=""
[[ -n "$SLOTNUM" ]] && slot_label=" (Slot $SLOTNUM)"
case "$mode" in
on)
sg_ses --index="$INDEX" --set=ident "$SES_DEV"
echo "LED an${slot_label}, SES index $INDEX via $SES_DEV – $DISK"
;;
off)
sg_ses --index="$INDEX" --clear=ident "$SES_DEV"
echo "LED aus${slot_label}, SES index $INDEX via $SES_DEV – $DISK"
;;
blink)
sg_ses --index="$INDEX" --set=ident "$SES_DEV"
echo "LED an${slot_label} – blinke ${BLINK_SECS}s (SES index $INDEX)…"
sleep "$BLINK_SECS"
sg_ses --index="$INDEX" --clear=ident "$SES_DEV"
echo "LED aus."
;;
esac
}
# ---------------------------------------------
# Methode wählen & LED einschalten (falls gew.)
# ---------------------------------------------
SES_DEV=""; INDEX=""; SLOTNUM=""; HOST=""; BUS=""; TARGET=""; LUN=""
OLDDEV=""
if (( USE_LED )); then
case "$METHOD" in
symlink)
led_symlink "$([[ $BLINK_SECS -gt 0 ]] && echo blink || echo on)" \
|| { echo "Symlink-LED nicht verfügbar."; exit 1; }
# H:B:T:L & OLDDEV für delete/scan:
need lsscsi
LINE="$(lsscsi -g | awk -v d="$DISK" '{if ($(NF-1)==d) {print; exit}}')"
[[ -n "$LINE" ]] || { echo "Konnte $DISK nicht in 'lsscsi -g' finden."; exit 1; }
OLDDEV="$(awk '{print $(NF-1)}' <<<"$LINE")"
if [[ "$LINE" =~ \[([0-9]+):([0-9]+):([0-9]+):([0-9]+)\] ]]; then
HOST="${BASH_REMATCH[1]}"; BUS="${BASH_REMATCH[2]}"; TARGET="${BASH_REMATCH[3]}"; LUN="${BASH_REMATCH[4]}"
else
echo "Konnte SCSI-Adresse nicht parsen."; exit 1
fi
;;
ses)
read SES_DEV INDEX SLOTNUM HOST BUS TARGET LUN < <(get_ses_index) || exit 1
led_ses "$([[ $BLINK_SECS -gt 0 ]] && echo blink || echo on)" "$SES_DEV" "$INDEX" "$SLOTNUM"
# OLDDEV zusätzlich erfassen (nur Info)
need lsscsi
LINE="$(lsscsi -g | awk -v d="$DISK" '{if ($(NF-1)==d) {print; exit}}')"
[[ -n "$LINE" ]] && OLDDEV="$(awk '{print $(NF-1)}' <<<"$LINE")" || true
;;
auto)
if ! led_symlink "$([[ $BLINK_SECS -gt 0 ]] && echo blink || echo on)"; then
echo "(Auto) Fallback auf SES…"
read SES_DEV INDEX SLOTNUM HOST BUS TARGET LUN < <(get_ses_index) || exit 1
led_ses "$([[ $BLINK_SECS -gt 0 ]] && echo blink || echo on)" "$SES_DEV" "$INDEX" "$SLOTNUM"
else
# Symlink-Weg erfolgreich: H:B:T:L & OLDDEV besorgen
need lsscsi
LINE="$(lsscsi -g | awk -v d="$DISK" '{if ($(NF-1)==d) {print; exit}}')"
[[ -n "$LINE" ]] || { echo "Konnte $DISK nicht in 'lsscsi -g' finden."; exit 1; }
OLDDEV="$(awk '{print $(NF-1)}' <<<"$LINE")"
if [[ "$LINE" =~ \[([0-9]+):([0-9]+):([0-9]+):([0-9]+)\] ]]; then
HOST="${BASH_REMATCH[1]}"; BUS="${BASH_REMATCH[2]}"; TARGET="${BASH_REMATCH[3]}"; LUN="${BASH_REMATCH[4]}"
else
echo "Konnte SCSI-Adresse nicht parsen."; exit 1
fi
fi
;;
*) echo "Unbekannte Methode: $METHOD"; exit 1 ;;
esac
else
# Keine LED: wir brauchen nur H:B:T:L & OLDDEV
need lsscsi
LINE="$(lsscsi -g | awk -v d="$DISK" '{if ($(NF-1)==d) {print; exit}}')"
[[ -n "$LINE" ]] || { echo "Konnte $DISK nicht in 'lsscsi -g' finden."; exit 1; }
OLDDEV="$(awk '{print $(NF-1)}' <<<"$LINE")"
if [[ "$LINE" =~ \[([0-9]+):([0-9]+):([0-9]+):([0-9]+)\] ]]; then
HOST="${BASH_REMATCH[1]}"; BUS="${BASH_REMATCH[2]}"; TARGET="${BASH_REMATCH[3]}"; LUN="${BASH_REMATCH[4]}"
else
echo "Konnte SCSI-Adresse nicht parsen."; exit 1
fi
fi
# -------------
# Deregister
# -------------
echo ">>> Entferne $DISK (SCSI ${HOST}:${BUS}:${TARGET}:${LUN})"
echo 1 | sudo tee "/sys/class/scsi_device/${HOST}:${BUS}:${TARGET}:${LUN}/device/delete" >/dev/null || true
# -------------
# Prompt / Swap (ohne Slotnummer)
# -------------
if (( PROMPT )); then
read -p ">>> Bitte neue Festplatte einsetzen und ENTER drücken… " _
fi
# -------------
# Rescan (gezielt für den Target-Slot)
# -------------
echo ">>> Rescanne Slot (Target ${TARGET}) über host${HOST}…"
echo "${HOST} ${BUS} ${TARGET}" | sudo tee "/sys/class/scsi_host/host${HOST}/scan" >/dev/null
# -------------
# Neues Device finden (by H:B:T:L)
# -------------
echo ">>> Warte auf neues Blockdevice im Slot (Target ${TARGET})…"
need lsscsi
NEWDISK=""
for i in {1..20}; do
NEWLINE="$(lsscsi -g | awk -v h="$HOST" -v b="$BUS" -v t="$TARGET" '$1==sprintf("[%d:%d:%d:0]",h,b,t){print; exit}')"
if [[ -n "$NEWLINE" ]]; then
NEWDISK="$(awk '{print $(NF-1)}' <<<"$NEWLINE")"
echo ">>> Neues Device: $NEWDISK ($NEWLINE)"
break
fi
sleep 1
done
if [[ -n "$NEWDISK" ]]; then
if [[ -n "$OLDDEV" ]]; then
if [[ "$NEWDISK" == "$OLDDEV" ]]; then
echo ">>> Hinweis: Laufwerksbuchstabe unverändert geblieben ($NEWDISK) – alles ok."
else
echo ">>> Hinweis: Buchstabe wechselte: alt=$OLDDEV neu=$NEWDISK (normal bei Hot-Swap)."
fi
fi
else
echo "Hinweis: Im Zeitfenster kein neues Device sichtbar. Entweder Treiber/Controller langsam, oder der Slot wurde noch nicht neu gemeldet. Prüfe lsscsi/Logs."
fi
# -------------
# LED aus
# -------------
if (( USE_LED )); then
case "$METHOD" in
symlink)
led_symlink off || true # nutzt den gecachten locate-Pfad
;;
ses)
led_ses off "$SES_DEV" "$INDEX" "$SLOTNUM" || true
;;
auto)
if [[ -n "${SES_DEV:-}" && -n "${INDEX:-}" ]]; then
led_ses off "$SES_DEV" "$INDEX" "$SLOTNUM" || true
else
led_symlink off || true
fi
;;
esac
fi
echo ">>> Fertig."
Nun noch ausführbar machen
chmod +x /usr/local/bin/scsi-hotswap.shHilfe/Benutzung:
Usage:
scsi-hotswap [--method auto|symlink|ses] [--blink N|--no-led] [--no-prompt] /dev/sdX|sdX|sdXn
Optionen:
--method M M = auto (default) | symlink | ses
--blink N LED vor dem Tausch N Sekunden blinken (statt dauerhaft an)
--no-led keine LED-Steuerung
--no-prompt nicht auf ENTER warten (setze voraus, dass neue Platte schon steckt)
Beispiele:
scsi-hotswap sdi
scsi-hotswap --method symlink --blink 8 sdg8
scsi-hotswap --method ses --no-prompt sdmAusgabe:
root@backupsrv001:~# scsi-hotswap.sh /dev/sdq
>>> Entferne /dev/sdq (SCSI 3:0:17:0)
>>> Bitte neue Festplatte in Slot 17 einsetzen...
Weiter mit ENTER, wenn neue Platte steckt.
>>> Rescanne Slot 17...
>>> Neue Device-Liste:Proxmox - Lets Encrypt Zertifikat
Einrichtung Lets Encrypt Zertifikat über Port 80 und im Terminal
Einrichtung des Clients
1. Als erstes Git installieren. Dazu per ssh einloggen
apt install git -y
2. Client herunterladen
cd /root/
git clone https://github.com/Neilpang/acme.sh.git acme-masterClient konfigurieren unsere einstellungen speichern wir unter /etc/pve/.le
Dazu wird das Verzeichnis erstellt.
mkdir /etc/pve/.le
cd /root/acme-masterNun die Konfiguration erstellen, dazu benötigen wir eine Emailadresse
./acme.sh --install --accountconf /etc/pve/.le/account.conf --accountkey /etc/pve/.le/account.key --accountemail "eMail@addresse.de"Danach aus der Shell ausloggen und wieder einloggen, um die bashrc neu zu laden
Das erste Zertifikat
zuerst wird ein Probezertifikat erstellt um zu sehen ob auch alles klappt bevor wir uns sperren lassen.
$DOMAIN wird mit unserer Domain ersetzt z.b meinedomain.org oder subdomain.meinedomain.org
cd /root/acme-master
./acme.sh --issue --standalone --keypath /etc/pve/local/pveproxy-ssl.key --fullchainpath /etc/pve/local/pveproxy-ssl.pem --reloadcmd "systemctl restart pveproxy" -d $DOMAIN --testIst das Zertifikat durchgelaufen, dann wird test durch --force ersetzt
./acme.sh --issue --standalone --keypath /etc/pve/local/pveproxy-ssl.key --fullchainpath /etc/pve/local/pveproxy-ssl.pem --reloadcmd "systemctl restart pveproxy" -d $DOMAIN --forceZertifikat Updaten
Einen cronjob anlegen
crontab -eNun im crontab diese zeile einfügen
0 0 * * * "/root/.acme.sh"/acme.sh --cron --home "/root/.acme.sh" > /dev/nullFertig
Proxmox Lets Encyrpt Zertifikat über Webgui und DNS Challenge
Einrichtung Acme Account und DNS Plugin
Auf der Weboberfläche einloggen, Dann auf Datacenter -> Acme gehen.

Nun bei Accounts auf den Button Add klicken.
Nun eine gültige Emailadresse anlegen und die TOS Bedinnungen akzeptieren.
Wer möchte kann auch einen anderen namen verwenden, falls mehrere Accounts benötigt werden. Ich lasse es bei default
Dann auf Register klicken.
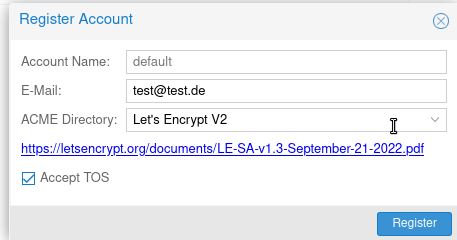
Wenn alles geklappt hat,bekommt eine Medlung mit TASK OK
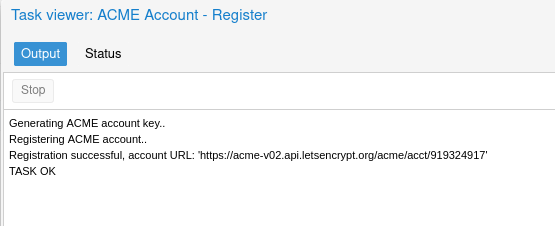
Nun das DNS Plugin erstellen.
Dazu bei Challenge Plugin auf Add klicken
Plugin Name vergeben in meinem Fall plesk, dann das Plugin auswählen für den Hoster. In meinem Fall auch pleskxml
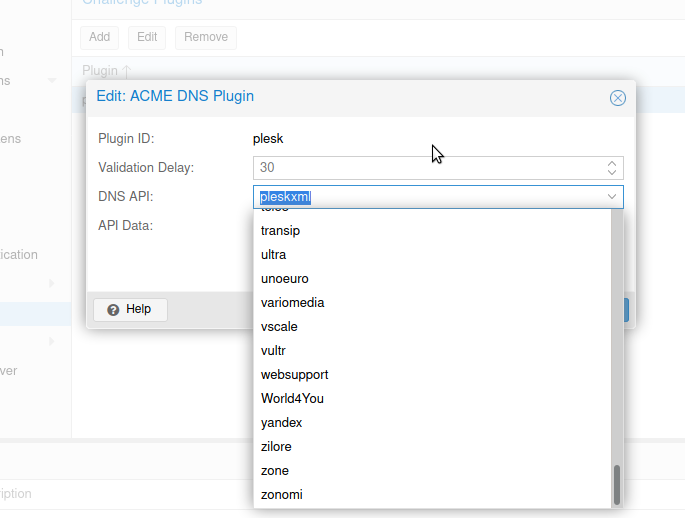
Nun die Api Daten also Benutzername Kennwort angeben und dann auf ok.

Nun haben wir einen Account und ein Plugin konfiguriert
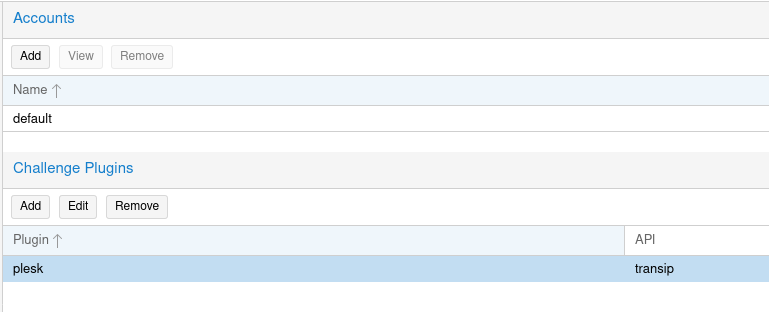
Dann den Vserver anklicken für den das Zertifikat gelten soll, hat man mehrer VServer muss das für jeden VServer wiederholt werden. Vserver anklicken -> Certificates anklicken.
Nun sieht man auch schon das er das Lets Encrypt Konto default verwendet. Nun bei Acme auf Add klicken
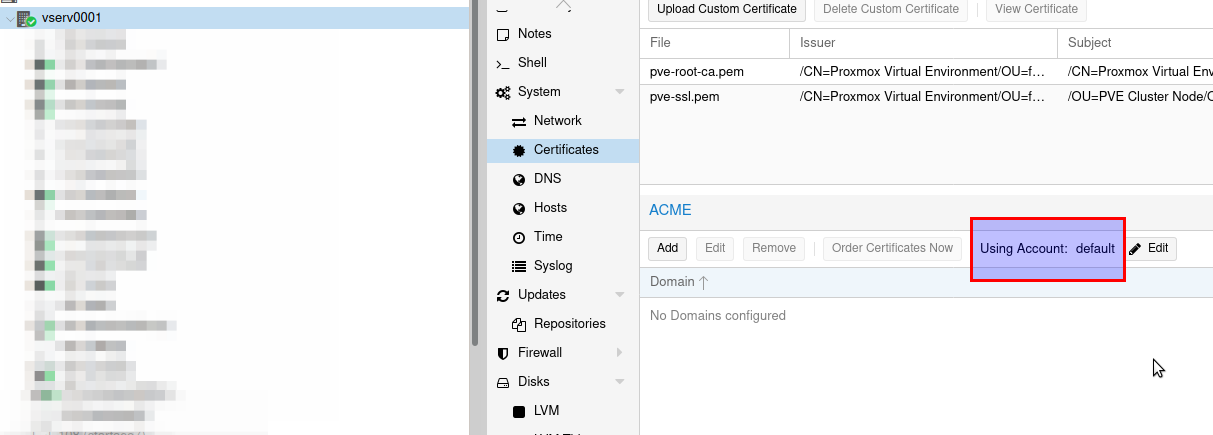
Nun Channlenge Type DNS auswählen
Plugin : plesk auswählen
Domain namen eintragen.
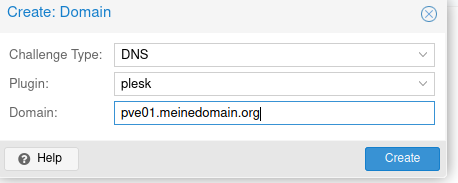
Nun haben wir die Domain in der Übersicht. Dort dann auf order Certificates now klicken

Proxmox . Nested Virtualisierung
Einschalten von Nested Virtualisation
Beschreibung
Damit man in eine VM einen Proxmoxhost virtualisieren kann, muss im oberen Host Nested Virtualisation eingeschaltet werden. Wenn es nicht aktiv ist bekommt man bei der Proxmox installation diesen Fehler
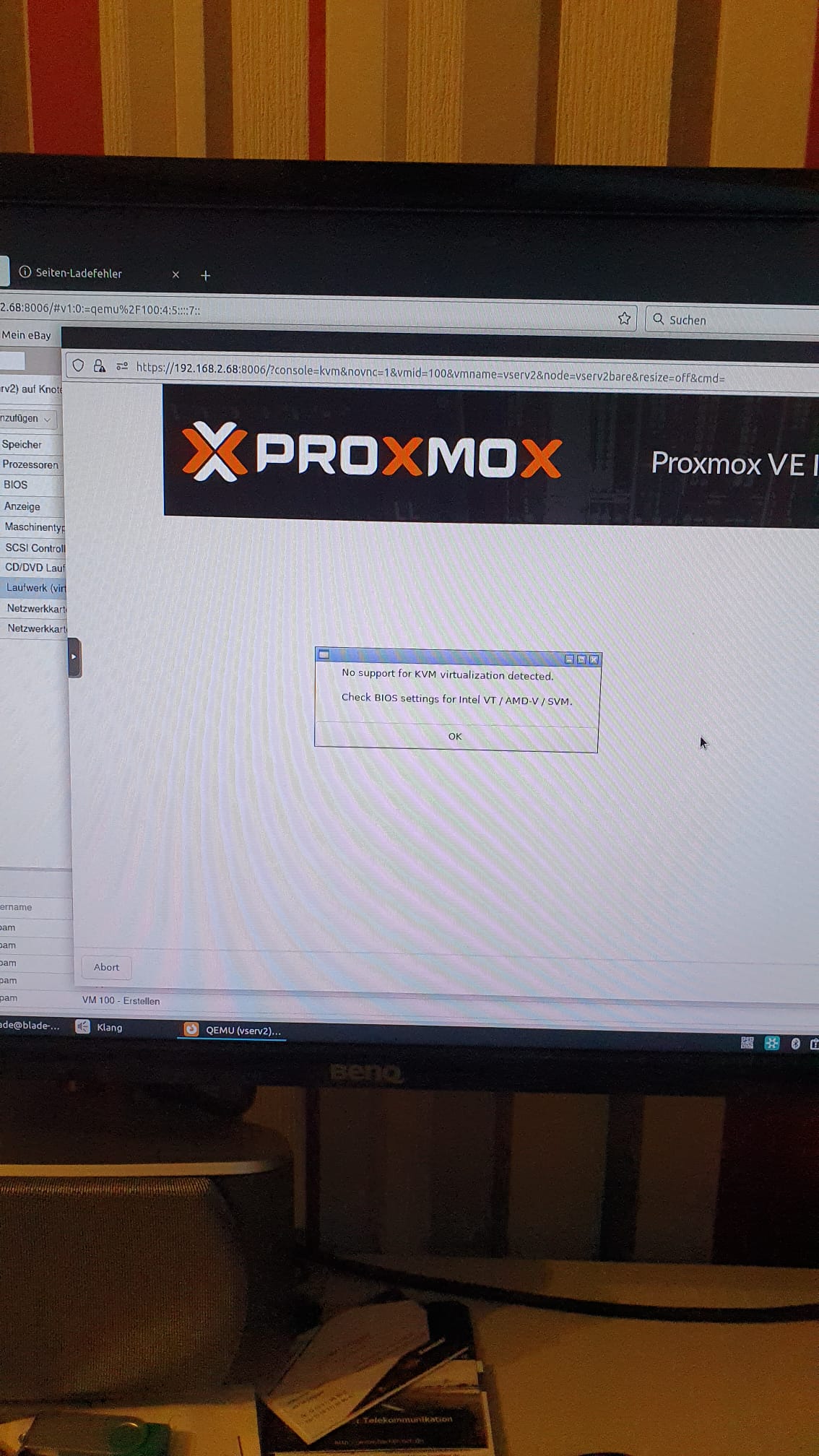
Einschalten
Ein Terminal auf dem Realen Host öffnen.
Nun checken ob Nested aktiv ist.
cat /sys/module/kvm_intel/parameters/nestedAusgabe, in der Regel ist hier dann ein N für No
Für Intel CPUs diesen Befehl zum aktivieren
echo "options kvm-intel nested=Y" > /etc/modprobe.d/kvm-intel.confFür AMD CPUs diesen Befehl zum aktivieren
echo "options kvm-amd nested=1" > /etc/modprobe.d/kvm-amd.conf
Nun den Host neustarten oder die Module reloaden
reboot
oder
modprobe -r kvm_intel
modprobe kvm_intelWichtig das die VM die Nested benutzen soll, als CPU TYP Host hat.
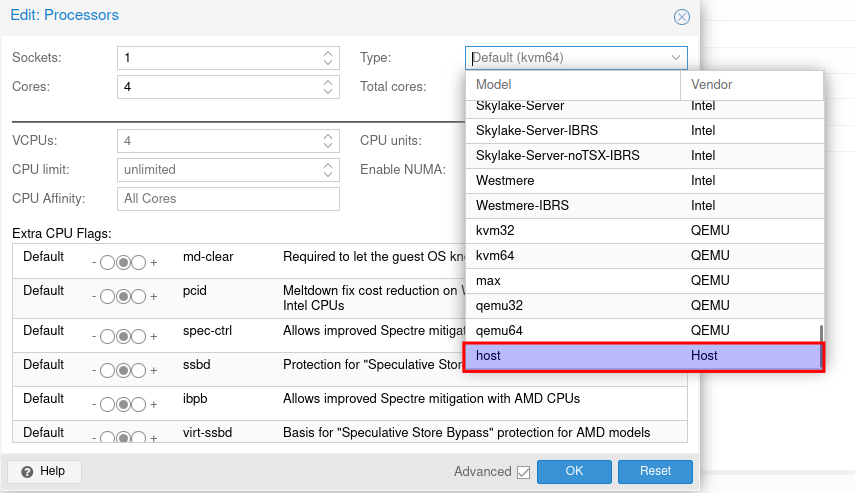
Fertig.
Proxmox - Import VirtualBoxAppliance
Kopieren der Appliance und Import des OVF Images
Beschreibung
Es ist auch in Proxmox möglich eine VirtualBox (OVF) Vorlage zu importieren.
Abbhängigkeiten auf dem Proxmox Server: unzip
apt install unzipKopieren und entpacken Zip Datei der Appliance.
In Unserem Beispiel der OpenThinClientAppliance.
Von unserem Computer kopieren wir die Appliance in das Root Home Verzeichnis.
scp Downloads/openthinclient-Appliance-2022.1.1-virtualbox.zip root@<proxmoxhost>:/rootoder wenn möglich gleich von der website per wget runterladen ins Root Home Verzeichnis
wget "https://archive.openthinclient.org/openthinclient/customer/virtual-appliance_ZkiPsbW/openthinclient-Appliance-2022.1.1-virtualbox.zip" --no-check-certificate Nun das archiv entpacken und ins entpackte Verszeichnis gehen.
unzip openthinclient-Appliance-2022.1.1-virtualbox.zip
cd openthinclient-Appliance-2022.1.1-virtualboxImport des OVF Images
qm importovf <vmid> <vorlagendatei>.ovf <speicher>
Beispiel
qm importovf 121 openthinclient-Appliance-2022.1.1.ovf vmsFehler
Bei Fehler invalid host ressource /disk/vmdisk1, skipping folgendes durchführen.
Die gerade angelegte VM wieder löschen
Den Befehl nochmals ausführen aber diesmal das Format der Festplatte muss angegeben werden also.
qm importovf <vmid> <vorlagendatei>.ovf <speicher> --format qcow2
Beispiel
qm importovf 121 openthinclient-Appliance-2022.1.1.ovf vms --format raw|qcow2|vmdkSollte der Fehler weiterhin bestehen, die vmdk einzeln importieren. Die 121 Machine wurde ja schon angelegt.
Also diesmal nicht löschen.
Dann den qm importdisk Befehl nutzen
qm importdisk <vmid> <source> <storage>
Besipiel
qm importdisk 121 openthinclient-Appliance-2022.1.1-disk001.vmdk vmsAusgabe:
WARNING: dos signature detected on /dev/datenpool/vm-121-disk-0 at offset 510. Wipe it? [y/n]: [n]
Aborted wiping of dos.
Logical volume "vm-121-disk-0" created.
1 existing signature left on the device.
(0.00/100%)
(27.00/100%)
Nun warten bis fertig.
Unzip OVA Datei, inder dann die ovf liegt
Beschreibung:
Manchmal liegen die Dateien nicht in einer Zip file sondern in eine OVA Datei.
Diese kann entpackt werden wie ein tar archiv und darin befindet sich dann die ovf.
Das archiv von meineovafile.tar nach meineovafile.tar umbenennen.
Sonst lässt es sich nicht enpacken.
Diese tar ist eigentlich ein 7zip archiv.
Nun 7zip installieren
apt install 7zipNun
7zz x meienovafile.tarJetzt haben wir die Dateien im gleichen Verzeichnis wie die ova .tar datei liegen.
ls
haos_ova-12.3.tar home-assistant.mf home-assistant.ovf home-assistant.vmdk
Nun können wir im Abschnitt ovf weitermachen
Kopieren der Appliance und Import des OVF Images
Proxmox - LVM in VM vergrößern
PV Group / VGroup und Logical Volume inklusive Dateisystem Vergrößern
Laufwerk der VM vergrößern
Im Proxmox einloggen, die Virtuelle Machine auswählen und auf Hardware gehen.
Dort die Festplatte auswählen und auf resize disk klicken.
Nun angeben um wie viel Gigabyte das Volume größer werden soll. In unserem Beispiel 99 GB
Somit hat das Laufwerk dann, 300 GB gesamt 201 GB + 99 GB = 300 GB.
Nachdem der gewünschte Wert angegeben ist auf resize disk klicken.

Nun hat die Disk eine Größe von 300 GB
In der VM Gruppen vergrößern
Partition vergößern mit parted
Anmelden per noNC Konsole oder über ssh wenn möglich.
Zur erinnerung noVNC Console:
VM anklicken und im Menü oben auf Console klicken

Nun im Terminal erstmaldie Partionen und die Größen rausbekommen mit dem Befehl
lsblkAusgabe:

Wie in diesem Beispiel zu sehen, liegen die LVs auf dem Laufwerk /dev/sda2.
Die Festplatte sda hat 300 GB erreicht.
Nun müssen wir die Partiton auch auf 300 GB bringen.
Das machen wir mit dem Programm parted.
Sollte parted nicht installiert sein, dieses nachinstallieren.
apt-get install parted [On Debian/Ubuntu systems]
yum install parted [On RHEL/CentOS and Fedora]
dnf install parted [On Fedora 22+ versions]Nun parted starten mit dem Befehl
partedNun dort den Befehl eingeben:
select /dev/sdaAusgabe:
Nun die Einheiten vom MB auf Sektoren umstellen damit wir den startsektor bekommen. Dazu den Befehl
unit sverwenden.
Nun lassen wir uns die Partitionen inklusive freien Bereich durch den Paramter free anzeigen, mit dem Befehl:
print freeAusgabe:
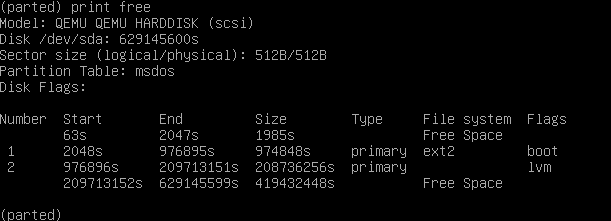
Jetz sehen wir die Infos. Uns interessiert das ende des Laufwerks.
Also Sektor : 629145599s
Diesen müssen wir spater angeben.
Nun die Partiton vergößern mit angabe der Partion, hier Partition 2, da liegt unser lvm drauf.
Befehl:
resizepart 2Nun wird nach dem Ende gefragt. Vorgeschlagen wird uns das aktuelle ende der Partition.
Wir wollen die Partition ja auf das ende des Datenträgers legen.
Somit die Volle Kapazität des Datenträgers.

Also geben wir als Endsektor 629145599s
Nun nochmals ausgeben mit dem
Befehl:
print freenun sieht man die 2 Partition geht bis ans ende. Voilla
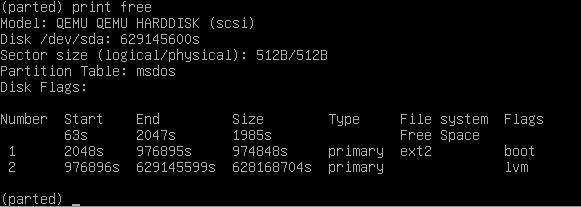
Nun mit dem Befeh:
quitraus.
PV Volume vergrößern
die PV Group rausfinden.
Befehl:
pvs
Ausgabe:
PV VG Fmt Attr PSize Free
/dev/sda2 nvistaVG lvm2 a-- 200,53 0Nun wissen wir das PV = /dev/sda2 ist und das die VG nvistaVG heißt.
Als erstes müssen wir die PV vergrößern.
Befehl:
pvresize <partition>
in userem Beispiel
pvresize /dev/sda2Ausgabe:
Physical volume "/dev/sda2" changed
1 physical volume(s) resized / 0 physical volume(s) not resizedNun überprüfen ob das Volume vergrößert wurde
pvsAusgabe:
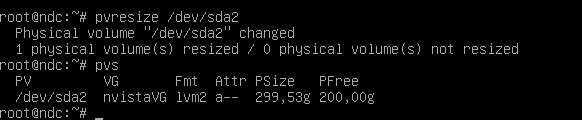
Nun mit Befeh:
vgssehen wir, das auch gleich die volume group mit vergrößert wurde.
Ausgabe:

Logical Volume aufs Maximale Vergrößern
Mite dem Befehlen anzeigen lassen welche LogicalVolumes es gibt
ls /dev/mapperAusgabe:

Nun das Volume nvistaVG-ndcVolume vergrößern.
mit dem Befehl
lvextend --resizefs -l +100%FREE /dev/mapper/<volumegroup>-<logicalvolume>
In unserem Beispiel
lvextend --resizefs -l +100%FREE /dev/mapper/nvistaVG-ndcVolumeAusgabe:

Speicher überpüfen mit dem Befehl:
df -hin der Ausgabe zu sehen, das root laufwerk ist auf 287 GB gewachsen, denn in der Volume Group liegt ja noch das swap Volume und in der ersten Partition die Boot Partition, so das das ndcVolume nicht die Gesamtkapazität von 300 GB haben kann:
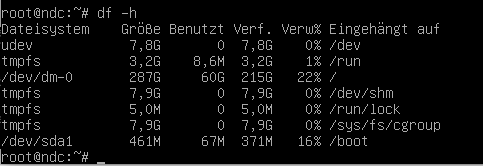
Fertig
Proxmox Host LVM Vergrößern
Laufwerk vergrößern und LVM Volumes vergößern
Partition vergößern mit parted
Nun im Terminal erstmal die Partionen und die Größen rausbekommen mit dem Befehl
lsblkAusgabe:
Wie in diesem Beispiel zu sehen, liegen die LVs auf dem Laufwerk /dev/sda2.
Die Festplatte sda hat 300 GB erreicht.
Nun müssen wir die Partiton auch auf 300 GB bringen.
Das machen wir mit dem Programm parted.
Sollte parted nicht installiert sein, dieses nachinstallieren.
apt-get install parted [On Debian/Ubuntu systems]
yum install parted [On RHEL/CentOS and Fedora]
dnf install parted [On Fedora 22+ versions]Nun parted starten mit dem Befehl
partedNun dort den Befehl eingeben:
select /dev/sdaAusgabe:
Nun die Einheiten vom MB auf Sektoren umstellen damit wir den startsektor bekommen. Dazu den Befehl
unit sverwenden.
Nun lassen wir uns die Partitionen inklusive freien Bereich durch den Paramter free anzeigen, mit dem Befehl:
print freeAusgabe:
Jetz sehen wir die Infos. Uns interessiert das ende des Laufwerks.
Also Sektor : 629145599s
Diesen müssen wir später angeben.
Nun die Partiton vergößern mit angabe der Partion, hier Partition 2, da liegt unser lvm drauf.
Befehl:
resizepart 2Nun wird nach dem Ende gefragt. Vorgeschlagen wird uns das aktuelle ende der Partition.
Wir wollen die Partition ja auf das ende des Datenträgers legen.
Somit die Volle Kapazität des Datenträgers.
Also geben wir als Endsektor 629145599s
Nun nochmals ausgeben mit dem
Befehl:
print freenun sieht man die 2 Partition geht bis ans ende. Voilla
Nun mit dem Befeh:
quitraus.
PV Volume vergrößern
die PV Group rausfinden.
Befehl:
pvs
Ausgabe:
PV VG Fmt Attr PSize Free
/dev/sda2 nvistaVG lvm2 a-- 200,53 0Nun wissen wir das PV = /dev/sda2 ist und das die VG nvistaVG heißt.
Als erstes müssen wir die PV vergrößern.
Befehl:
pvresize <partition>
in userem Beispiel
pvresize /dev/sda2Ausgabe:
Physical volume "/dev/sda2" changed
1 physical volume(s) resized / 0 physical volume(s) not resizedNun überprüfen ob das Volume vergrößert wurde
pvsAusgabe:
Nun mit Befeh:
vgssehen wir, das auch gleich die volume group mit vergrößert wurde.
Ausgabe:
Logical Volume aufs Maximale Vergrößern
Nun das Meta Volume um 32GB erweitern und dann das Daten Volume den rest
mit dem Befehl
lvextend -L +32G /dev/pve/data_tmeta
lvextend -l +100%FREE /dev/pve/dataAusgabe:
lvextend -L +32G /dev/pve/data_tmeta
lvextend -l +100%FREE /dev/pve/data
Reached maximum pool metadata size <15.88 GiB (4065 extents).
Thin pool will use metadata without cropping.
Size of logical volume pve/data_tmeta changed from 1.44 GiB (369 extents) to <15.88 GiB (4065 extents).
Logical volume pve/data_tmeta successfully resized.
Size of logical volume pve/data_tdata changed from <157.54 GiB (40329 extents) to <1.76 TiB (460266 extents).
Logical volume pve/data successfully resized.
Speicher überpüfen in der Oberfläche

Fertig
Proxmox - Qemu Agent installation
Qemu Agent in der VM Aktivieren
Beschreibung
Der QEMU AGnet ist eine Geräte/Treiberschnittstelle mit der der Proxmox host mit der VM kommunizieren kann.
Aktivierung
DIeser muss in den VM Eigenschaften aktiviert werden.
Dazu rufen wir die Proxmox Web GUI auf.
Wählen die VM aus die den Agent bekommen soll.
Dort nun auf Options -> Doppelklick auf qemu Agent

Nun den Haken bei Enable Qemu Agent rein.
Dies ist für alle VMs gleich Egal ob Windows oder Linux
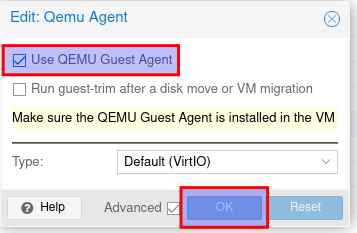
Nun wenn die Machine noch läuft einmal stoppen und wieder starten.
Nun sollte das so aussehen.
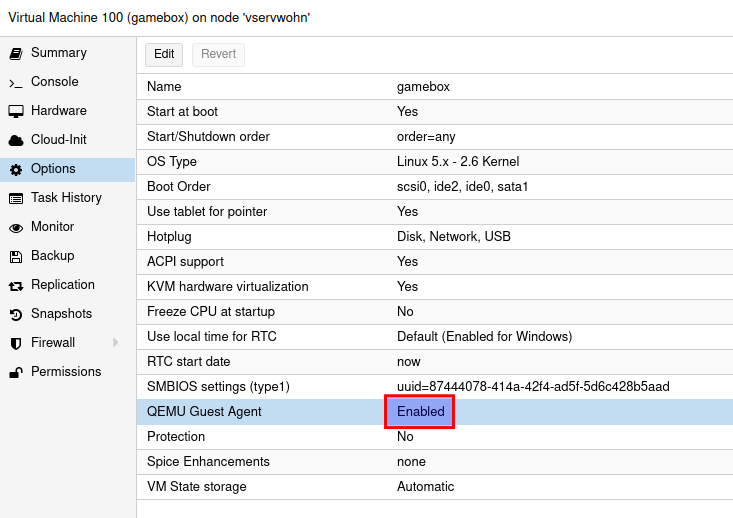
Fertig
Qemu Agent unter Windows
Beschreibung
Damit der Qemuagent genutz werden kann, muss der Treiber unter Windows installiert werden.
Installation
ISO Einlegen
Wir loggen uns auf der Proxmoxoberfläche ein gehen auf die Machine und legen die VirtIO Treiber ISO ein. DIese haben wir auch schon mal gebraucht um die Netzwerkkarte und/oder Festplattencontroller zu aktivieren ein.
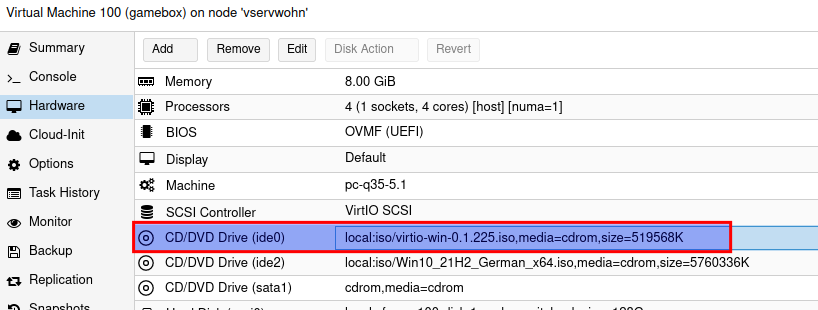
Treiber installieren
Nun in der Windows VM den Gerätemanger öffnen. Dort sehen wir unter andere Geräte ein PCI-Komminkationscontroller. Ist dies nicht der Fall.
Ist dies nicht der Fall unter Systemgeräte schauen ob es da schon ein VirtIO Serial Driver gibt.
wenn ja ist alles schon installiert. Wenn nein, schauen ob in der VM Guest Agent aktiviert ist.
Ist der Eintragunter andere Geräte vorhandenn un doppelklick auf das Gerät und auf Treiber aktualisieren klicken
Nun auf AUs einer Liste auswählen

Nun auf Weiter

Nun auf Datenträger
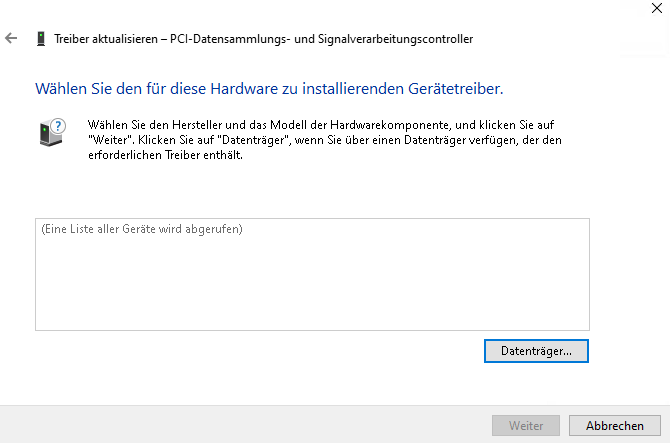
Auf Durchsuchen
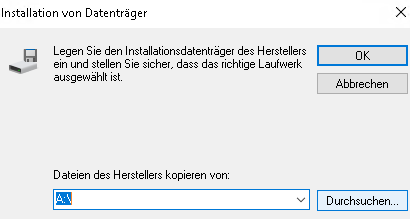
Nun auf die VirtCD -> vioserial euer Bestriebsystem, bei mir Win10 dann die Architektur bei amd64
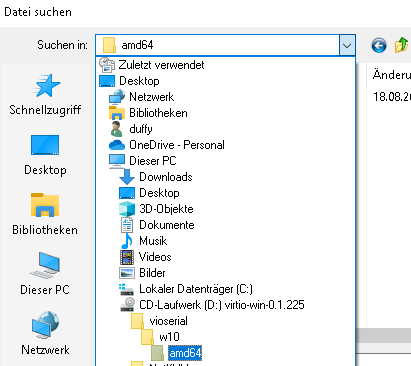
Dort die vioser.inf öffnen
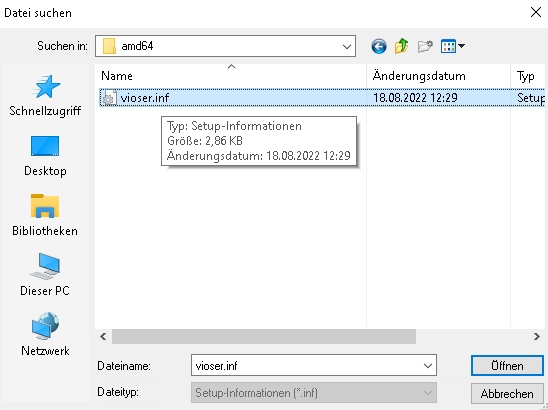
Nun VirtIO Serial Driver ausählen und auf weiter
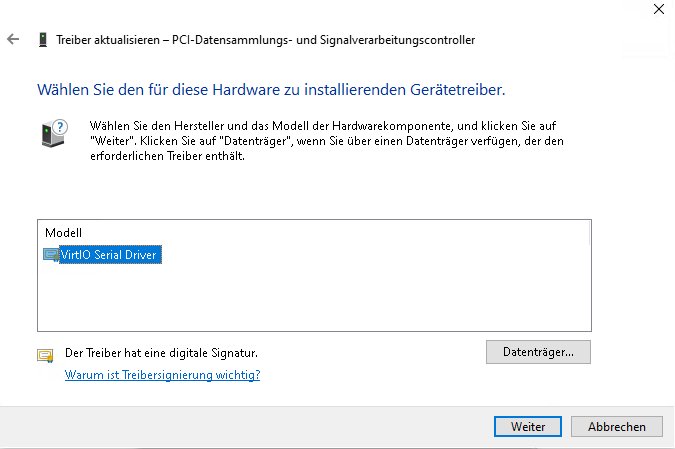
Jetzt ist der Treiber isntalliert. Nun auf schließen klicken
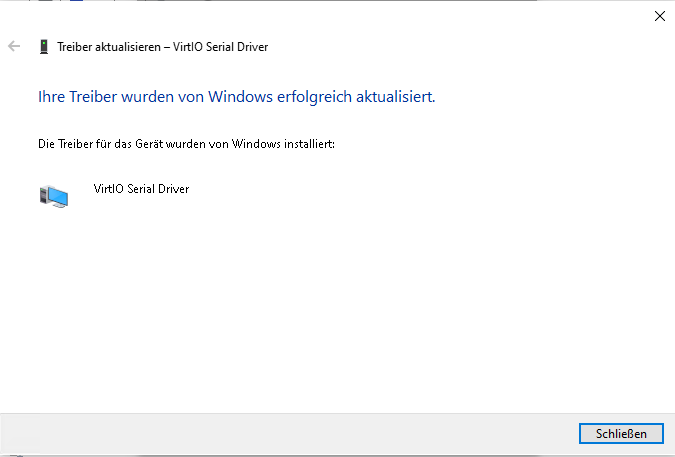
Jetzt ist der Treiber in der Liste zu sehen
Agent Programm installieren
Zum Schlussn och den Agent Dienst installieren
Dazu auf die Virtio CD züruck in das Verzeichnis guest-agent. Und Dort für eure Architektur den Agent installieren
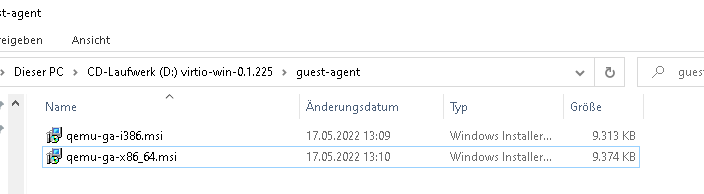
Testen ob die Kommunikation
Dazu per SSH oder Webshell auf den Host anmelden und folgenden Befhl ausführen
qm agent <vmid> ping
Beispiel
qm agent 100 pingWenn nichts zurückgeben wird hats funktioniert.
Proxmox - Ceph
Ceph (Aussprache /ˈsɛf/) ist eine quelloffene verteilte Speicherlösung (Storage-Lösung) in der Informationstechnik. Kernkomponente ist mit RADOS (englisch reliable autonomic distributed object store) ein über beliebig viele Server redundant verteilbarer Objektspeicher (englisch object store). Ceph bietet dem Nutzer drei Arten von Storage an: Einen mit der Swift- und S3-API kompatiblen Objektspeicher (RADOS Gateway), virtuelle Blockgeräte (RADOS Block Devices) und CephFS, ein verteiltes Dateisystem.[4]
Ceph kann als RADOS Block Device (RBD) über das Ceph iSCSI Gateway auch als hochverfügbares iSCSI-Target bereitgestellt werden. Dadurch kann es auf Client-Seite durch viele Betriebssysteme (auch Windows) genutzt werden.
Crushmap dekompilieren / kompilieren
Beschreibung:
Die Ceph Crushmap ist eine Konfigurationsdatei in Ceph, die beschreibt, wie Daten auf physische Speicherressourcen verteilt werden sollen. Sie definiert die Hierarchie der Speichergeräte und ihre Beziehungen zueinander, um die Ausfallsicherheit und Leistung von Ceph-Clustern zu optimieren. Die Crushmap wird von der Crush-Algorithmus-Engine verwendet, um intelligente Verteilungsentscheidungen zu treffen und sicherzustellen, dass Daten auch bei Ausfällen von Speichergeräten zugänglich bleiben.
Dekompilieren
Crushmap im Binärformat speichern.
Syntax
ceph osd getcrushmap -o <zieldatei>
ceph osd getcrushmap -o ~/crush_map_compressed_2023-03-29Nun die Binärdatei dekompilieren. Somit haben wir auch gleichzeitig eine Sicherungskopie, nämlich die Kompilierte Datei
Sytntax
crushtool -d <binärcrushmapdatei> -o <zielcrushmapdateidecompiled>
crushtool -d ~/crush_map_compressed_2023-03-29 -o ~/crush_map_decompiled_2023-03-29Nun kann die crushdatei mit einem ganz normelen Texteditor wie vi,vim,nano,joe etc. bearbeitet werden.
Kompilieren und wieder injekzieren
crushtool -c <crushmapdateidecompiled> -o <neuebinärcrushmapdatei>
crushtool -c ~/crush_map_decompiled_2023-03-29 -o ~/new_crush_map_compressed_2023-03-29Nun kann diese Datei wieder Injekziert werden
Syntax
ceph osd setcrushmap -i <neuebinärcrushmap>
ceph osd setcrushmap -i ~/new_crush_map_compressed_2023-03-29Fertig.
Pools nach Classen anlegen (SSD Pool / HDD Pool)
Beschreibung:
In Ceph können Sie verschiedene Pools anlegen, um unterschiedliche Typen von Speichergeräten zu nutzen. Zum Beispiel können Sie SSD-, NVME- und HDD-Pools erstellen, um eine optimale Nutzung der verfügbaren Speichergeräte zu erreichen. Jeder Pool kann unterschiedliche Konfigurationen für die Leistung und die Ausfallsicherheit aufweisen, um den Anforderungen der Anwendung gerecht zu werden. Durch die Verteilung von Daten auf verschiedene Speichergeräte können Sie auch sicherstellen, dass Daten bei Ausfällen von Speichergeräten zugänglich bleiben.
Festplatten Typen (Classes)
In Ceph können einer OSD verschiedene Klassen hinzugefügt werden.
Diese sind:
-
ssd: Eine OSD-Klasse für SSD-Speichergeräte. Diese OSDs werden normalerweise für Daten verwendet, die eine höhere Leistung erfordern.
-
hdd: Eine OSD-Klasse für HDD-Speichergeräte. Diese OSDs werden normalerweise für Daten verwendet, die keine hohe Leistung erfordern, sondern eher für Archiv- oder Backupzwecke geeignet sind.
-
nvme: Eine OSD-Klasse für NVMe-Speichergeräte. Diese OSDs werden normalerweise für Daten verwendet, die eine sehr hohe Leistung erfordern, z.B. für Anwendungen mit hohem I/O-Durchsatz.
Festplatten Klasse löschen/setzen
Ist schon eine Festplattenklasse gesetzt muss diese erst gelöscht werden, bevor eine neue vergeben werden kann. Im Terminal dienen folgende Befehle zum löschen/setzen.
In unserem Fall die OSD.12 auf NVME setzten.
Löschen
ceph osd crush rm-device-class <osdnr>
ceph osd crush rm-device-class osd.12
Ausgabe:
done removing class of osd(s): 12Setzen
Syntax
classtype = hdd,ssd,nvme
ceph osd crush set-device-class <classtype> <osdnr>
ceph osd crush set-device-class nvme osd.12
Ausgabe:
set osd(s) 12 to class 'nvme'Crushmap um weitere replicated rule erweitern/ändern.
!Wichtige Hinweise!!!
!!! WICHTIG!!! Es muss schon eine OSD mit der Klasse geben, bevor eine Rule dafür gebaut werden kann !!!
Ist dies nicht der Fall müsen wir erst die erste Rule nur anpassen für die Klasse die schon da ist.
Danach legen wir dei OSD mit der neuen Klasse an, aber vor alle dem alles auf Maintenance setzten!!!
!!! WICHTIG!!! Alles auf Maintenance stzten, wie no backfill, noreblance etc setzen.
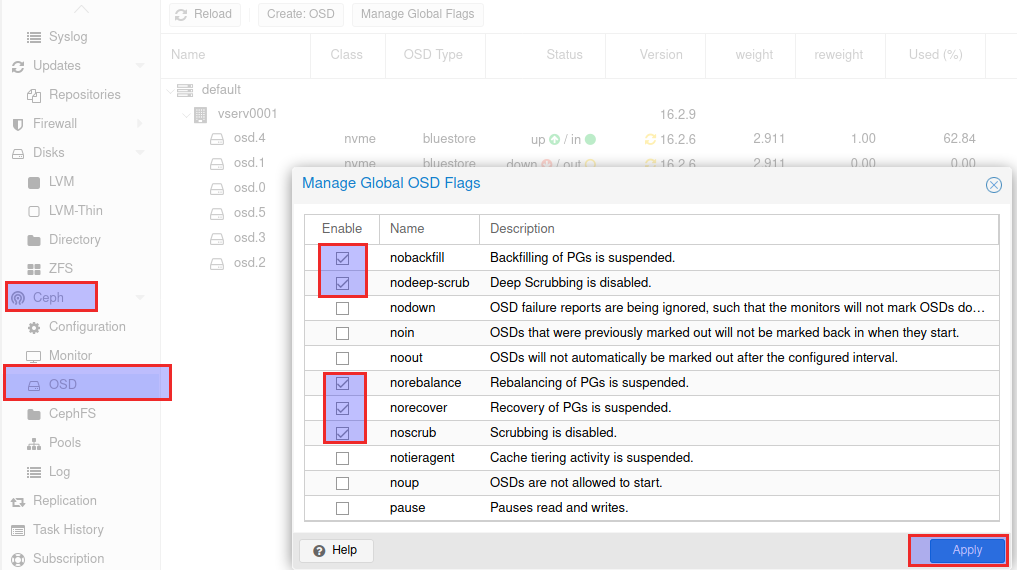
Erst nach erstellung der Rule die haken wieder entfernen.
Über manuelles bearbeiten
Die Crushmap decompilieren so, das man diese auch bearbeiten kann. Siehe Seite : Crushmap dekompilieren / kompilieren
Ist die Map decompiliert. Der ersten Rule den Parameter für die Klassenzueweisung hinzufügen.
Damit wäre dann erste Regel definiert, das diese für HDDs gillt. Sollten nur NVMEs verbaut sein. Dann natürlich die erste Rule mit NVME setzen und die zweite dann auf HDDs. In unserem Scenario sind aber HDDs vorhanden und wir wollen NVME Pool hinzufügen. Sind noch gar keine Pools definiert, so kann man auch die erste Rule noch umbenennen, z.b noch _hdd hinzufügen.
Ist die Rule allerdings schon einem pool zugewiesen, muss dies aktualisiert werden. Was in einer Prod umgebung nicht wirklich Sinnvoll ist, dann einfach als gedanken lassen, die erste Rule ist die Rule von dem Klassentyp die zu erst da war. Wie bei uns die HDDs.
Hier der Parameter der einer Rule hinzugefügt werden muss
step take default class <classtype>
step take default class hddIn unsere Crushmap sehe das so aus.
Auszug.
Original
...
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step chooseleaf firstn 0 type host
step emit
}
...
Nun geändert mit HDD class
...
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default class hdd
step chooseleaf firstn 0 type host
step emit
}
Diese speichern und wieder zurückzuspielen.
Siehe Seite : Crushmap dekompilieren / kompilieren
Nun eine zweite Rule anlegen, dazu die erste kopieren und die ID und Namen ändern.
z.b so
...
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default class hdd
step chooseleaf firstn 0 type host
step emit
}
# rules
rule replicated_rule_nvme {
id 1
type replicated
min_size 1
max_size 10
step take default class nvme
step chooseleaf firstn 0 type host
step emit
}Diese speichern und wieder zurückzuspielen.
Siehe Seite : Crushmap dekompilieren / kompilieren
Fertig, nun Pool anlegen.
Über Kommandozeilen Befehl
Die Erste Rule die Klasse hinzufügen, wenn die noch keine Klasse hat
ceph osd crush rule modify <rulename> set class <classtype>
Beispiel
ceph osd crush rule modify replicated_rule set class hdd
Nun wenn nicht schon vorhanden OSD mit neuer Klasse hinzufügen.
Dann die weitere Rule erstellen
Erklärung der Parameter
|
<rule-name> |
Name der Regel, um sie mit einem Pool zu verbinden (angezeigt in der GUI und CLI) |
|
<root> |
Zu welchem Crush-Root sie gehören sollte (Standard-Ceph-Root "default") |
|
<failure-domain> |
An welchem Fehlerbereich die Objekte verteilt werden sollten (normalerweise Host) |
|
<class> |
Welcher Typ von OSD-Backing-Store verwendet werden soll (e.g., nvme, ssd, hdd) |
Syntax
ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class>
Beispiel
ceph osd crush rule create-replicated rule_nvme default host nvme
!!! WICHTIG!!! Maintenance mode wieder rausnehmen no backfill, noreblance etc aushaken.
Fertig nun Pool anlegen
Pool anlegen
Nun können wir einen weiteren Pool mit der neuen Rule anlegen.
Dazu auf der Weboberfläche proxmox anmelden, einen Host auswählen dann auf Ceph / Pools klicken
Dann auf Create klicken
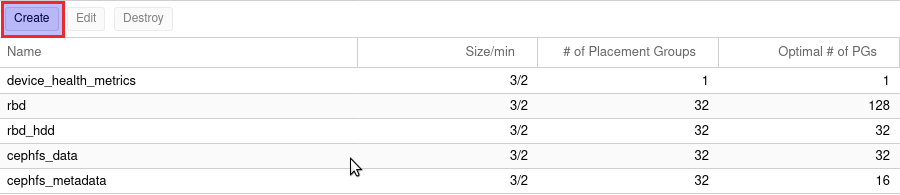
nun einen Namen vergeben und unseer Ruleset auswählen. Auto PG auf on und den Haken bei Add Storage rein.
Dann bekommen wir auch gleich den Speicher zum Datastore um darauf zuzugreifen.
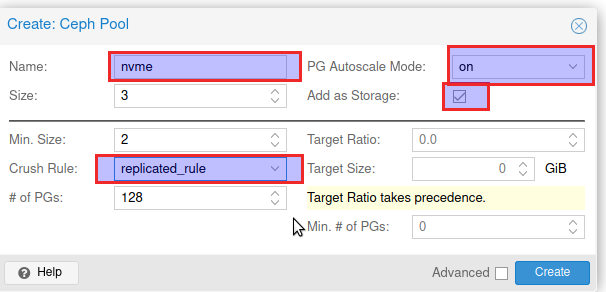
Fertig.
So könnte man zum Beispiel ein RBD Pool für NVMEs bauen und einen CephFS Pool mit HDDs.
Als Beispiel
!!!ACHTUNG! NICHT ZU EMPFEHLEN!!!
Man kann natürlich auch einen Vorhandenen Pool ein Komplett anderes Ruleset geben.
Aber Achtung die Daten ziehen dann nicht mit um. Die Änderungen gelten nur für neu geschriebene Daten.
Deshalb lieber einen neuen Pool Anlegen, Daten dort hin verschieben, alten Pool löschen.
Dann einen neuen Pool mit altem Namen und dann der richtigen Ruleset auswählen.
So bleiben die Daten konsistent
Nach löschen eines Ceph Monitors bleibt immer noch der eintrag über
Beschreibung:
Monitor über die GUI gelöscht, bleibt aber als unbekannt stehen.
Lösung 1:
Mittel ceph mon dump schauen ob der eintrag schon raus ist.
Wenn nicht den Monitor nochmals löschen.
ceph mon dumpAusgabe, bau uns handelt es sich um mon.vserv0003
epoch 13
fsid 0b8471ac-848e-4ceb-8c97-469c327f8390
last_changed 2023-07-31T16:38:00.940392+0200
created 2023-05-14T23:50:35.830167+0200
min_mon_release 17 (quincy)
election_strategy: 1
0: [v2:172.31.128.2:3300/0,v1:172.31.128.2:6789/0] mon.vserv0002
2: [v2:172.31.128.5:3300/0,v1:172.31.128.3:6789/0] mon.vserv0003
3: [v2:172.31.128.5:3300/0,v1:172.31.128.5:6789/0] mon.vserv0005
4: [v2:172.31.128.6:3300/0,v1:172.31.128.6:6789/0] mon.vserv0006
dumped monmap epoch 13
Dann diesen nochmals löschen
ceph mon remove <mon-id>
Beispiel:
ceph mon remove vserv0003Lösung 2:
Wenn in der mon dump unser Monitor nicht mehr drin ist, ist noch das Monitor Verzeichnis übrig geblieben.
epoch 13
fsid 0b8471ac-848e-4ceb-8c97-469c327f8390
last_changed 2023-07-31T16:38:00.940392+0200
created 2023-05-14T23:50:35.830167+0200
min_mon_release 17 (quincy)
election_strategy: 1
0: [v2:172.31.128.2:3300/0,v1:172.31.128.2:6789/0] mon.vserv0002
1: [v2:172.31.128.5:3300/0,v1:172.31.128.5:6789/0] mon.vserv0005
2: [v2:172.31.128.6:3300/0,v1:172.31.128.6:6789/0] mon.vserv0006
dumped monmap epoch 13
Auf dem Host wo der Monitor drauf war einloggen und im Verzeichnis /var/lib/ceph/mon schauen ob das Verzechnis noch da ist.
Wenn ja dieses löschen
cd /var/lib/ceph/mon
rm -r ceph-vserv0003/Ergebnis:
Nun ist die Liste wieder korrekt
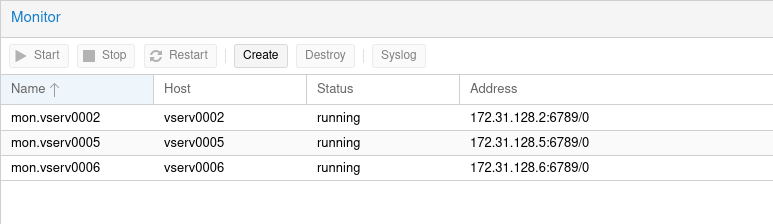
Nach entfernen eines Hosts bleibt in der Chrush Map der leere eintrag übrig
Beschreibung:
Nachdem man die OSD(s) den Monitor den manager , den MDS Manager gelöscht hat.
Bleibt in der Crushmap der Server stehen, halt ohne OSD(s) aber es nervt.
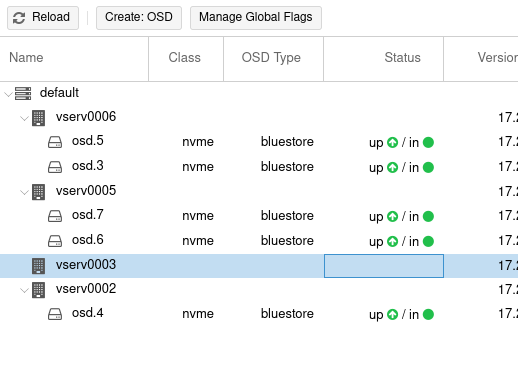
Lösung:
Erstmal schauen ob die Node auch tatsächlich entfernt wurde.
Dieses habem wir vorher mit dem Befehl:
pvecm delnode <nodename>
Beispiel:
pvecm delnode vserv0003
gemacht.
Um zu sehen das die Node auch wirklich raus ist, rufen wir
pvecm nodesAusgabe:
pvecm nodes
Membership information
----------------------
Nodeid Votes Name
1 1 vserv0002
2 1 vserv0006
3 1 vserv0005 (local)
Die Node 3 ist nicht mehr vorhanden, aber steht trotzdem noch in der Crushmap.
sollte die node doch noch drin stehen dann mit dem obigen befehl nochmals löschen.
Nun können wir den Eintrag aus der Crushmap entfernen.
nun schauen wir welche Nodes in der Crushmap sind
ceph osd treeAusgabe:
ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 14.55417 root default
-5 2.91019 host vserv0002
4 nvme 2.91019 osd.4 up 1.00000 1.00000
-3 0 host vserv0003
-9 5.82199 host vserv0005
6 nvme 2.91100 osd.6 up 1.00000 1.00000
7 nvme 2.91100 osd.7 up 1.00000 1.00000
-11 5.82199 host vserv0006
3 nvme 2.91100 osd.3 up 1.00000 1.00000
5 nvme 2.91100 osd.5 up 1.00000 1.00000
Dies ist die Zeile die uns interessiert
...
-3 0 host vserv0003
...nun den Eintrag löschen
ceph osd crush remove {name}
Beispiel:
ceph osd crush remove vserv0003Dann sieht das ganze wieder so aus
Fertig
Proxmox - Migrationen
Proxmox VMDK oder img in VM importieren
Beschreibung:
Eine neue VM erstellen mit einer VMDK Datei oder img datei.
Vorgang:
Eine neue VM erstellen ohne DIsks. Lediglich EFI Disk wenn das System EFI Boot benötigt.
Die ID der gerade erstellten VM merken
Die VMD oder img Datei auf den Server kopieren z.b per scp.
Nun mit dem Befehl
qm disk import <vmid> <source> <storage> [OPTIONS]
Beispiel
qm disk import 100 /mnt/meinimage.vmdk data
VM im LVM/ qcow2 format auf anderen Host in ein RBD migrieren ohne zwischenspeicher via SSH
Beschreibung
Es gibt Situationen, da möchte man eine VM auf eine andere umziehen lassen. Hat aber kein USB Datenträger bzw. dieser ist zu langsam, bzw man muss vorgänge ausführen, draufkopieren wieder runterkoiperen. Auch doppelte Zeit, oder oder oder...
Es gibt die Möglichtkeit mit screen und ssh dieses zu bewältigen.
Vorraussetzungen:
Das die zu kopierende VM natürlich NICHT läuft
Auf dem Zielsystem ist das Ceph soweit vorhanden und auch eingerichtet.
Auf dem Quellsystem ist screen installiert. Befehl dazu
apt install screenQuellsystem kann sich per ssh auf dem Zielsystem einloggen.
Vorgang
Auf dem Quellsystem Infos holen
Auf dem Quellsystem herausfinden wo unsere LVM Image liegen.
Dazu den Befehl lvs verwenden
Das LV ist sind die Diskimage und das VG die Volumegroup.
Somit wäre der Pfad im Dateisystem als Beispiel für vm-100-disk-1. Diese Disk nehmen wir auch für unserer Beispiel
/dev/datenppol/vm-100-disk-1Ausgabe
root@vmserv:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
vm-100-disk-1 datenpool -wi-a----- 200.00g
vm-101-disk-2 datenpool -wi-ao---- 500.00g
vm-101-disk-3 datenpool -wi-ao---- 500.00g
vm-101-disk-4 datenpool -wi-ao---- 500.00g
vm-101-disk-5 datenpool -wi-ao---- 500.00g
vm-101-disk-6 datenpool -wi-ao---- 500.00g
vm-101-disk-7 datenpool -wi-ao---- 500.00g
vm-101-disk-8 datenpool -wi-ao---- 500.00g
vm-102-disk-1 datenpool -wi-a----- 260.00g
vm-102-disk-2 datenpool -wi-a----- 650.00g
vm-103-disk-1 datenpool -wi-a----- 100.00g
vm-104-disk-1 datenpool -wi-a----- 32.00g
vm-105-disk-1 datenpool -wi-a----- 250.00g
vm-105-disk-2 datenpool -wi-a----- 250.00g
vm-106-disk-1 datenpool -wi-a----- 50.00g
vm-107-disk-1 datenpool -wi-a----- 100.00g
vm-108-disk-1 datenpool -wi-a----- 100.00g
vm-111-disk-1 datenpool -wi-a----- 100.00g
vm-112-disk-1 datenpool -wi-ao---- 500.00g
vm-112-disk-2 datenpool -wi-a----- 1000.00g
vm-113-disk-0 datenpool -wi-a----- 50.00g
vm-114-disk-0 datenpool -wi-a----- 50.00g
vm-116-disk-0 datenpool -wi-a----- 32.00g
vm-117-disk-0 datenpool -wi-a----- 16.00g
vm-118-disk-0 datenpool -wi-a----- 32.00g
vm-119-disk-0 datenpool -wi-a----- 250.00g
vm-119-disk-1 datenpool -wi-a----- 250.00g
vm-120-disk-0 datenpool -wi-a----- 128.00g
vm-121-disk-0 datenpool -wi-a----- 20.00g
medavol media -wi-a----- 3.42t
data pve -wi-ao---- 63.99g
root pve -wi-ao---- 31.75g
swap pve -wi-ao---- 15.88g
Auf dem Zielsystem Infos holen
Nun auf dem Zielserver den Pool heruasfinden wo die Images hinsollen.
Dazu auf den Zielserver einloggen und den Befehl eingeben:
ceph osd pool lsAusgabe, in userem Beispiel nehmen wir den rbd pool
device_health_metrics
rbd
rbd_hdd
cephfs_data
cephfs_metadataAuf dem Zielsystem die nächste freie VMID ermitteln, mittels
pvesh get /cluster/nextid
Ausgabe:
111Somit wird die 111 die neue VM ID auf dem Zielsystem.
VM Image kopieren
Nun per ssh auf den Quellserver einloggen oder direkt am Server das ist egal.
nun einen neuen Screenauf machen
Parameter
screen -S <namedersession>
Beispiel
screen -S migrateNun sind wir in einer Screensitzung, damit wir zum Beispiel unseren Laptop auch ausschalten dürfen.
Denn der Kopierbefehl läuft auf dem Quellsystem jetzt in einer eigenen Session.
Jetzt den Kopierbefehl ausführen für LVM
Parameter
ssh root@<zielsystem> "rbd import --image-format 2 - <ceph_rbd_pool>/vm-<NEUE_VMIDAUF_Zielsystem>-disk-<DISKNUMMER>" < /dev/<volumegroup_von_quellsystem>/<locicalvolume_von_quellsystem>
ssh root@192.168.178.240 "rbd import --image-format 2 - rbd/vm-111-disk-0" < /dev/datenpool/vm-100-disk-1
Hinweis:
--image-format 2 ist das RAW FormatJetzt den Kopiervorgang ausführen für qcow2
Parameter
ssh root@<zielsystem> 'rbd import --dest-pool <ceph_rbd_pool> --image-format 2 - vm-<NEUE_VMIDAUF_Zielsystem>-disk-<DISKNUMMER>' < </pfad/zur/image.qcow2>
ssh root@192.168.178.240 'rbd import --dest-pool rbd_hdd --image-format 2 - vm-116-disk-2' < /mnt/backup/images/105/vm-105-disk-0.qcow2
WICHTIG!!!!!! Hierzu auf dem Zielserver einloggen, denn wir holen uns dann vom quellsystem das image.
Einfach aus dem screen heraus!
WICHTIG!!!!!
Parameter
ssh root@<quellsystem> 'cat </pfad/zur/image.qcow2>' | rbd import - <ceph_rbd_pool>/vm-<NEUE_VMIDAUF_Zielsystem>-disk-<DISKNUMMER> --image-feature layering
Beispiel
ssh root@192.168.178.2 'cat /mnt/backup/images/105/vm-105-disk-0.qcow2' | rbd import - rbd_hdd/vm-116-disk-2 --image-feature layering
Nun läuft der kopiervorgang und wir können uns nun mit STRG+A gedrückt halten und dann +D von der Sitzung trennen
Ausgabe:
detached from 7763.migrate]
root@vmserv:~#Um uns wieder mit der Sitzung zu verbinden. Wenn wir noch keine neue Promt sehen für den nächsten Befehl, kopiert er noch.
screen -r migrate
Augabe:
root@192.168.178.240's password:
Nun wieder trennen. (STRG+A gedrückt halten dann +D) zum trennen.
Ab un zu mal schauen wie weit er ist.
Ist der Vorgang abgeschlossen, gibt es diese Fertig Meldung.
Importing image: 100% complete...done.
Sollte die VM mehrere Disks haben. Den vorgang wiederholen für die nächste DISK.
Im unseren Beispiel hat die VM aber nur eine DISK.
Die VM Config Datei übertragen
per scp kann die VM Config übertragen werden.
Die Dateien werden so benannt<VMID>.conf
Egal ob es KVM VMs sind oder LXC Conateiner
Die conf Dateien für KVM VMs in das Verzeichnis
/etc/pve/qemu-server/und für LXC Conateiner in
/etc/pve/lxc/Hat man ein Cluster kopiert man diese Datei auf den jeweiligen node, wo die VM dann hin soll.
Auf dem Quellsystem einloggen.
Nun der Befehl zum kopieren. In unserem Beispiel ist die vm 100 eine KVM VM
Parameter
scp /etc/pve/qemu-server/<altevmid>.conf root@<zielsystem:/etc/pve/qemu-server/<neue_vmid>.conf
Beispiel:
scp /etc/pve/qemu-server/100.conf root@<zielsystem:/etc/pve/qemu-server/111.confVM Conf bearbeiten
Nun ausloggen und auf dem Zielsystem einloggen und die Conf Datei bearbeiten. In unserem Beispiel die VM 111
nano /etc/pve/qemu-server/111.confAusgabe:
111.conf
#IP%3A192.168.2.112
boot: cdn
bootdisk: virtio0
cores: 16
memory: 32768
name: Terminal
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr0
numa: 0
onboot: 0
ostype: win7
sata2: local:iso/Windows10_x64_1909.iso,media=cdrom,size=4091M
sata3: local:iso/virtio-win-0.1.149.iso,media=cdrom,size=316634K
scsihw: virtio-scsi-pci
sockets: 1
virtio0: vms:vm-112-disk-1,cache=writeback,size=500G
virtio1: vms:vm-112-disk-2,cache=writeback,size=1000G
Nun den Abschnitt mit den Festplatten
...
virtio0: vms:vm-112-disk-1,cache=writeback,size=500G
...auf unseren neuen Datastore abändern. Wir ändern hier den alten Datastore vms zu unserem neuen Datastore rbd ab
Parameter
virtio0: <neuer_datastore>:vm-<neuevmid>-disk-<disknummer>,cache=writeback,size=500G
...
virtio0: rbd:vm-111-disk-0,cache=writeback,size=500G
...Sollten mehrere Disks vorhanden sein, dann dieses natürlich für alle Disk wiederholen. Nicht vergessen auch die Disk Nummer am ende ggf anzupassen
Den Abschnitt mit den ISOs äbaändern so das keine mher drin sind.
Vorher
...
sata2: local:iso/Windows10_x64_1909.iso,media=cdrom,size=4091M
...Nachher
...
sata2: none,media=cdrom
...Falls die Netzwerkbrücke noch geändert werden muss einfach die vmbr Nummer eingeben. Muss noch ein VLAN hinzugefügt werden. dann sieht das so aus, ansonsten nur die vmbr-ID ändern
Von
...
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr0
...Nach
Parameter
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr<ID>,tag=<VLAN_TAG>
...
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr0,tag=102
...Fertig
VM Starten glücklich sein.
qm start 111VM vom RBD auf anderen Host in ein RBD migrieren ohne zwischenspeicher via SSH
Beschreibung
Es gibt Situationen, da möchte man eine VM auf eine andere umziehen lassen. Hat aber kein USB Datenträger bzw. dieser ist zu langsam, bzw man muss vorgänge ausführen, draufkopieren wieder runterkoiperen. Auch doppelte Zeit, oder oder oder...
Es gibt die Möglichtkeit mit screen und ssh dieses zu bewältigen.
Vorraussetzungen:
Das die zu kopierende VM natürlich NICHT läuft
Auf dem Zielsystem ist das Ceph soweit vorhanden und auch eingerichtet.
Auf dem Quellsystem ist screen installiert. Befehl dazu
apt install screenQuellsystem kann sich per ssh auf dem Zielsystem einloggen.
Vorgang
Auf dem Quellsystem Infos holen
Auf den Quellsystem die pool(s) auflisten lassen
ceph osd pool lsAusgabe, in userem Beispiel nehmen wir den rbd pool
.mgr
rbd
rbd_hdd
cephfs_data
cephfs_metadata
Auf dem Quellsystem herausfinden wo VM Image liegen im rbd.
Dazu den Befehl.
rbd ls -p <pool-name>
rbd ls -p rbdverwenden
Ausgabe:
rbd ls -p rbd
vm-100-disk-0
vm-107-disk-0
vm-109-disk-0
vm-110-disk-0
vm-115-disk-0
vm-117-disk-0
vm-118-disk-0
vm-147-disk-0
Uns interessiert die vm-100-disk-0 .
Diese Disk nehmen wir auch für unserer Beispiel.
Wenn man möchte kann man sich noch weitere informationen vom image holen.
ist hier aber optional
rbd info -p <pool-name> <image-name>
Beispiel:
rbd info -p rbd vm-100-disk-0Ausgabe:
rbd image 'vm-100-disk-0':
size 8 GiB in 2048 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 2e3255c546ee1
block_name_prefix: rbd_data.2e3255c546ee1
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Thu Sep 2 14:46:13 2021
access_timestamp: Thu Sep 2 14:46:13 2021
modify_timestamp: Thu Sep 2 14:46:13 2021
Nun wissen wir das das Ding 8 GB groß ist und können so ne Zeitschätzung fürs kopieren machen.
Auf dem Zielsystem Infos holen
Nun auf dem Zielserver den Pool heruasfinden wo die Images hinsollen.
Dazu auf den Zielserver einloggen und den Befehl eingeben:
ceph osd pool lsAusgabe, in userem Beispiel nehmen wir den rbd pool
.mgr
rbd
rbd_hdd
cephfs_data
cephfs_metadata
Auf dem Zielsystem die nächste freie VMID ermitteln, mittels
pvesh get /cluster/nextid
Ausgabe:
111Somit wird die 111 die neue VM ID auf dem Zielsystem.
VM Image kopieren
Nun per ssh auf den Quellserver einloggen oder direkt am Server das ist egal.
nun einen neuen Screenauf machen
Parameter
screen -S <namedersession>
Beispiel
screen -S migrateNun sind wir in einer Screensitzung, damit wir zum Beispiel unseren Laptop auch ausschalten dürfen.
Denn der Kopierbefehl läuft auf dem Quellsystem jetzt in einer eigenen Session.
Jetzt den Kopierbefehl ausführen
Parameter
rbd export rbd_hdd/vm-<QUELL_VMID>-disk-<DISKNUMMER> - | pv | ssh -C root@<zielsystem> "rbd import --image-format 2 - <ceph_rbd_pool>/vm-NEUE_VMIDAUF_Zielsystem-disk-<DISKNUMMER>"
Beispiel:
rbd export rbd_hdd/vm-100-disk-0 - | pv | ssh -C root@192.168.178.5 "rbd import --image-format 2 - rbd/vm-111-disk-0"
Hinweis:
--image-format 2 ist das RAW Format
pv -zeigt den fortschritt an
-C steht für Compression an.Nun läuft der kopiervorgang und wir können uns nun mit STRG+A gedrückt halten und dann +D von der Sitzung trennen
Ausgabe:
detached from 7763.migrate]
root@vmserv:~#Um uns wieder mit der Sitzung zu verbinden. Wenn wir noch keine neue Promt sehen für den nächsten Befehl, kopiert er noch.
screen -r migrate
Augabe:
root@192.168.178.240's password:
Nun wieder trennen. (STRG+A gedrückt halten dann +D) zum trennen.
Ab un zu mal schauen wie weit er ist.
Ist der Vorgang abgeschlossen, gibt es diese Fertig Meldung.
Importing image: 100% complete...done.
Sollte die VM mehrere Disks haben. Den vorgang wiederholen für die nächste DISK.
Im unseren Beispiel hat die VM aber nur eine DISK.
Die VM Config Datei übertragen
per scp kann die VM Config übertragen werden.
Die Dateien werden so benannt<VMID>.conf
Egal ob es KVM VMs sind oder LXC Conateiner
Die conf Dateien für KVM VMs in das Verzeichnis
/etc/pve/qemu-server/und für LXC Conateiner in
/etc/pve/lxc/Hat man ein Cluster kopiert man diese Datei auf den jeweiligen node, wo die VM dann hin soll.
Auf dem Quellsystem einloggen.
Nun der Befehl zum kopieren. In unserem Beispiel ist die vm 100 eine KVM VM
Parameter
scp /etc/pve/qemu-server/<altevmid>.conf root@<zielsystem:/etc/pve/qemu-server/<neue_vmid>.conf
Beispiel:
scp /etc/pve/qemu-server/100.conf root@<zielsystem:/etc/pve/qemu-server/111.confVM Conf bearbeiten
Nun ausloggen und auf dem Zielsystem einloggen und die Conf Datei bearbeiten. In unserem Beispiel die VM 111
nano /etc/pve/qemu-server/111.confAusgabe:
111.conf
#IP%3A192.168.2.112
boot: cdn
bootdisk: virtio0
cores: 16
memory: 32768
name: Terminal
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr0
numa: 0
onboot: 0
ostype: win7
sata2: local:iso/Windows10_x64_1909.iso,media=cdrom,size=4091M
sata3: local:iso/virtio-win-0.1.149.iso,media=cdrom,size=316634K
scsihw: virtio-scsi-pci
sockets: 1
virtio0: vms:vm-100-disk-0,cache=writeback,size=500G
Nun den Abschnitt mit den Festplatten
...
virtio0: rbd:vm-100-disk-0,cache=writeback,size=500G
...auf unseren neuen Datastore abändern. Wir ändern hier den alten Datastore vms zu unserem neuen Datastore rbd ab
Parameter
virtio0: <neuer_datastore>:vm-<neuevmid>-disk-<disknummer>,cache=writeback,size=500G
...
virtio0: rbd:vm-111-disk-0,cache=writeback,size=500G
...Sollten mehrere Disks vorhanden sein, dann dieses natürlich für alle Disk wiederholen. Nicht vergessen auch die Disk Nummer am ende ggf anzupassen
Den Abschnitt mit den ISOs äbaändern so das keine mher drin sind.
Vorher
...
sata2: local:iso/Windows10_x64_1909.iso,media=cdrom,size=4091M
...Nachher
...
sata2: none,media=cdrom
...Falls die Netzwerkbrücke noch geändert werden muss einfach die vmbr Nummer eingeben. Muss noch ein VLAN hinzugefügt werden. dann sieht das so aus, ansonsten nur die vmbr-ID ändern
Von
...
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr0
...Nach
Parameter
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr<ID>,tag=<VLAN_TAG>
...
net0: e1000=12:4E:C7:A9:77:DD,bridge=vmbr0,tag=102
...Fertig
VM Starten glücklich sein.
qm start 111P2V - Laufenden Windows per SSH in Proxmox rbd import
Beschreibung:
Migration, einen P2V Windows Machine.
Das Windows muss laufen und eine Verbindung zum Proxmox Server muss bestehen / bzw erreichbar sein per ssh.
Vorrausetzung:
Installiere Cygwin. DD ist schon drin enthalten: https://www.cygwin.com/ für Alle Benutzer installieren.
Einfach einen Mirror auswählen und weiter weiter. Alle Basis Pakete so lassen und weiter klicken.
Dort in den Paketen zusätzlich das programm pv für den Fortschritt anzeigen lassen, nachinstallieren bzw mit auswählen.
Transferrieren
Cygwin als Administrator starten
Unter /dev/disk/by-id werden die Fetsplatten aufgelistet mit den Partitionen
Mittels DD kann die Festplatte per SSH kopiert werden
dd if=/dev/disk/by-id/nvme-Samsung_SSD_980_PRO_with_Heatsink_1TB_0025_38B2_3140_4F13. bs=4M | pv | ssh -C root@192.168.178.9 "rbd import --image-format 2 --image-feature layering - data/vm-804-disk-0"
Nun wenn das Image kopiert ist eine Neue VM mit der gleichen ID erstellen und eine Festplatte als dummy.
Diese bekommt dann automatisch die disk-1 am ende.
Nun kann man in die Conf datei gehen
nano /etc/pve/qemuserver/<vmid>.confDen Festplatten eintrag verdoppeln.
Aus der zeiten Festplatte scsi0 dann eine 1
Und bei Festplatte scsi0 (also die erste dann aus disk-1 eine disk-0
Schon hat man zwei Laufwerke drin.
Dann in der gui die disk-1 wieder löschen so das disk-0 übrig bleibt.
nun eventuell mit einer Live CD die virtio Treiber impfen zum Beispiel mit Paragon.
P2V - Festplatte direkt am Host angeschlossen in Proxmox rbd import
Beschreibung:
Migration, einer P2V Windows Machine.
Installiert vorher noch die virtio Treiber und die Spcie Geust Tools.
Die Festplatte wird aus dem Computer / Server ausgebaut und direkt an den Server gehängt.
Dann wird die Festplatte als RBD Image ins Ceph kopiert .
Vorrausetzung:
Installiere Paket pv falls nicht vorhanden
apt install pvTransferrieren
eine Neue VM mit der gleichen ID oder neuen ID erstellen und eine Festplatte als dummy.
Diese bekommt dann automatisch die disk-0 am ende.
Diese Festplatte wieder löschen.
Festplatte ermitteln die per USB oder direktreingehängt wurde ermitteln.
mit
lsblkFestplatten auflisten lassen
Unter /dev/disk/by-id werden die Fetsplatten aufgelistet mit den Partitionen
Mittels DD kann die Festplatte per SSH kopiert werden
Die VM id anpassen und die disk nummer.
Tipp: in einer Screen Sitzung arbeiten.
dd if=/dev/disk/by-id/nvme-Samsung_SSD_980_PRO_with_Heatsink_1TB_0025_38B2_3140_4F13. bs=4M | pv | rbd import --image-format 2 --image-feature layering - data/vm-804-disk-0
Nun wenn das Image kopiert ist eine Neue VM mit der gleichen ID erstellen und eine Festplatte als dummy.
Sollten es mehrer disks sein, Eintrag kopieren die disk-1 am ende abändern.
So kommt man in die kann man in die Conf datei
nano /etc/pve/qemuserver/<vmid>.confnun eventuell mit einer Live CD die virtio Treiber impfen zum Beispiel mit Paragon.
Cluster Netzwerk wechseln
Beschreibung:
Man möchte in einem Proxmox Cluster das corosync Cluster wechseln, weil man zusätzliche Netzwerkkarten verwenden möchte oder ein VXNetLan gebaut hat oder oder oder...
Auf jeden Fall möchte man neue IP-Adressen setzten.
Durchführung:
nano /etc/pve/corosync.confDort die IP-Adressen bei allen Nodes austauschen
...
node {
name: pvetest01
nodeid: 1
quorum_votes: 1
ring0_addr: 10.30.0.10
}
node {
name: pvetest02
nodeid: 2
quorum_votes: 1
ring0_addr: 10.30.0.11
...Wenn zwei Netzwerkkarten konfiguriert waren ist das zweite Ring Adress 1.
Also Ring Adress 0 wenn gewünscht und 1 austauschen
nodelist {
node {
name: vserv0005
nodeid: 4
quorum_votes: 1
ring0_addr: 172.30.128.5
ring1_addr: 172.31.128.5
}
node {
name: vserv0006
nodeid: 3
quorum_votes: 1
ring0_addr: 172.30.128.6
ring1_addr: 172.31.128.6
}
node {
name: vserv0007
nodeid: 1
quorum_votes: 1
ring0_addr: 172.30.128.7
ring1_addr: 172.31.128.7und die Versionsnummer weiter unten um eine erhöhen
Versionsnummer erhöhen, alt war 4 neu ist dann eine weiter 5
totem {
cluster_name: hackertest
config_version: 5
interface {
linknumber: 0Nun in der Hosts Datei den proxmox DNS Namen auf die neue Clusteradresse anpassen.
Alt 192.168.178.2 wurde zu 10.30.10.10. Danach die Hosts neustarten wichtig!
127.0.0.1 localhost.localdomain localhost
10.30.10.10 pvetest01.hacker.local pvetest01Hier die Neue Ansicht, alle Quorate mit den neuen Adressen. In diese Beispiel gab es nur link 0 und kein Link 1 dazu
Proxmox - erweiterte Netzwerkeinstellungen
Infiniband
Beschreibung
Infiband Karten sind eine günstige Lösung um schnelles Ethernet zu bauen. Eigentlich sind die Karten urspürnglich dazu angedacht SANs bereitzustellen, aber wir können uns dieses auch als 40 GBit Netzwerk zu nutze machen.
Vorraussetzungen:
Infiniband Karten
Infiniband switch
Infiband Kabel
Installation
Insalltallation Infiniband Karte
Installieren der Tools
apt-get install infiniband-diags ibutils iperf ethtoolNun laden wir die Module
modprobe ib_ipoib
modprobe ib_umadJe nach System heißen die Adapter anders.
Um zu sehen ob die Treiber geladen wurden dann je nach System
ip a | grep ib0
ip a | grep ib1
oder
ip a | grep ibpSieht die Ausgabe dann so aus (entweder mit ib0 oder ib1 oder halt diese...
ip a | grep ibp
13: ibp6s16: <BROADCAST,MULTICAST> mtu 4092 qdisc noop state DOWN group default qlen 256
14: ibp6s16d1: <BROADCAST,MULTICAST> mtu 4092 qdisc noop state DOWN group default qlen 256
!!!!Hinweis, sollte kine ib0 oder ipb aufgelistet sein laufen die Karten eventuell im Ethernet modus!!!
$ ip a
# InfiniBand Mode
4: ibp129s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 2044 qdisc mq state UP group default qlen 256
link/infiniband ...
inet 192.168.7.100/24 brd 192.168.7.255 scope global ibp129s0
valid_lft forever preferred_lft forever
# Ethernet Mode
7: ens1f1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether ...
inet 10.200.0.1/24 brd 10.200.0.255 scope global ens1f1
valid_lft forever preferred_lft forever
Diese dann eben der modules Datei hinzufügen, so das diese dann auch beim Systemstart geladen werden.
echo ib_umad >> /etc/modules
echo ib_ipoib >> /etc/modulesNetzwerk Setup
Die Infinibandkarten werden genauso konfiguriert wie Netzwerkkarten
nur mit dem unterschied das wir noch den Mode angeben.
In meinem Beispiel heißen die Karten (Ports) so:
ibp6s16
ibp6s16d1
#/etc/network/interfaces
auto ibp6s16
iface ibp6s16 inet static
address 172.30.128.75
netmask 255.255.240.0
broadcast 172.30.143.255
pre-up echo connected > /sys/class/net/ibp6s16/mode
mtu 65520
auto ibp6s16d1
iface ibp6s16d1 inet static
address 172.31.128.75
netmask 255.255.240.0
broadcast 172.31.143.255
pre-up echo connected > /sys/class/net/ibp6s16d1/mode
mtu 65520Nun die Adapter starten
ifup ibp6s16
ifup ibp6s16d1
Nun pingen wir unsere eigene Karte an.
ping 172.30.128.75Ausgabe, wenn das klappt ist die Konfiguration abgeschlossen.
ING 172.30.128.75 (172.30.128.75) 56(84) bytes of data.
64 bytes from 172.30.128.75: icmp_seq=1 ttl=64 time=0.017 ms
64 bytes from 172.30.128.75: icmp_seq=2 ttl=64 time=0.021 ms
^C
--- 172.30.128.75 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 0.017/0.019/0.021/0.002 ms
mit dem Befehl ibstat sehen wir den Status der und Eigenschaften der Karte (Ports)
ibstatAusgabe:
ibstat
CA 'mlx4_0'
CA type: MT4099
Number of ports: 2
Firmware version: 2.42.5000
Hardware version: 1
Node GUID: 0xf4521403009871a0
System image GUID: 0xf4521403009871a3
Port 1:
State: Initializing
Physical state: LinkUp
Rate: 40
Base lid: 0
LMC: 0
SM lid: 0
Capability mask: 0x02514868
Port GUID: 0xf4521403009871a1
Link layer: InfiniBand
Port 2:
State: Initializing
Physical state: LinkUp
Rate: 40
Base lid: 0
LMC: 0
SM lid: 0
Capability mask: 0x02514868
Port GUID: 0xf4521403009871a2
Link layer: InfiniBand
root@vserv0003:~#
Wie man sieht bleibt der Status auf initilazing stehen, das liegt daran weil wir noch keinen Subnetmanager haben.
Einige Switche bringen auch einen SM Manager mit.
Ich empfehle aber, diesen zu deaktivieren und auf den Hosts einen SM Manager zu installieren, mit Prioritäten
Installation OPENSM Manager (Ein Manager für Subnetze)
Pakete installieren
apt-get install opensmNachdem der Manager installiert ist, ist der Status der Karten aktiv.
Ausgabe ibstat
ibstat
CA 'mlx4_0'
CA type: MT4099
Number of ports: 2
Firmware version: 2.42.5000
Hardware version: 1
Node GUID: 0xf4521403009871a0
System image GUID: 0xf4521403009871a3
Port 1:
State: Active
Physical state: LinkUp
Rate: 40
Base lid: 1
LMC: 0
SM lid: 1
Capability mask: 0x0251486a
Port GUID: 0xf4521403009871a1
Link layer: InfiniBand
Port 2:
State: Active
Physical state: LinkUp
Rate: 40
Base lid: 3
LMC: 0
SM lid: 1
Capability mask: 0x0251486a
Port GUID: 0xf4521403009871a2
Link layer: InfiniBand
Mit dem tool ethtool sehen wir dann auch die Ethernetgeschwindigkeit.
erhtool ibp6s16
Ausgabe:
Settings for ibp6s16:
Supported ports: [ ]
Supported link modes: Not reported
Supported pause frame use: No
Supports auto-negotiation: No
Supported FEC modes: Not reported
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Advertised FEC modes: Not reported
Speed: 40000Mb/s
Duplex: Full
Auto-negotiation: on
Port: Other
PHYAD: 255
Transceiver: internal
Link detected: yes
Wenn man als Manager redunanz haben möchte, sollte auf jedem Node der Infiniband nutzt, opensm installiert sein.
Denn startet ein Host neu, ist das Netzwerk ohne Subnetmanager.
Selbst wenn man nur einen Host hat, kann man diesen schon konfigurieren.
Bei jedem Server muss die Priorität geandert werden.
Die Prioritäten gehen von 0-15
Die höchste übernimmt.
Das heißt den ersten Server konfigurieren wir mit 15 dann 14 usw. Das heit es können maximal 16 Manager in einem Netz sein.
Eine Redunandanz von MAx 16 sollte eigentlich reichen.
Nun die Konfig erstellen auf der ersten Node
opensm --create-config /etc/opensm/opensm.confAusgabe:
-------------------------------------------------
OpenSM 3.3.23
Command Line Arguments:
Creating config file template '/etc/opensm/opensm.conf'.
Log File: /var/log/opensm.log
-------------------------------------------------
Priorität in der config ändern. Bei Server 1 der Wert 15. Bei Server 2 = 14 und bei Server 3 = 13
nano /etc/opensm/opensm.confDort in der nähne von Zeile 258 die Prio ändern.
# SM priority used for deciding who is the master
# Range goes from 0 (lowest priority) to 15 (highest).
sm_priority 15Nun den Manager neustarten
service opensm restart
Möchte man unbedingt die ausgabe sehen dann folgenden Befehl verwenden
opensm -B
Ausgabe:
-------------------------------------------------
OpenSM 3.3.23
Reading Cached Option File: /etc/opensm/opensm.conf
Loading Cached Option:sm_priority = 15
Command Line Arguments:
Daemon mode
Log File: /var/log/opensm.log
-------------------------------------------------Mit dem Befehl sehen wir folgende.
ibdiagnetAusgabe:
oading IBDIAGNET from: /usr/lib/x86_64-linux-gnu/ibdiagnet1.5.7
-W- Topology file is not specified.
Reports regarding cluster links will use direct routes.
Loading IBDM from: /usr/lib/x86_64-linux-gnu/ibdm1.5.7
-W- A few ports of local device are up.
Since port-num was not specified (-p option), port 1 of device 1 will be
used as the local port.
-I- Discovering ... 3 nodes (1 Switches & 2 CA-s) discovered.
-I---------------------------------------------------
-I- Bad Guids/LIDs Info
-I---------------------------------------------------
-I- No bad Guids were found
-I---------------------------------------------------
-I- Links With Logical State = INIT
-I---------------------------------------------------
-I- No bad Links (with logical state = INIT) were found
-I---------------------------------------------------
-I- General Device Info
-I---------------------------------------------------
-I---------------------------------------------------
-I- PM Counters Info
-I---------------------------------------------------
-I- No illegal PM counters values were found
-I---------------------------------------------------
-I- Fabric Partitions Report (see ibdiagnet.pkey for a full hosts list)
-I---------------------------------------------------
-I- PKey:0x7fff Hosts:4 full:4 limited:0
-I---------------------------------------------------
-I- IPoIB Subnets Check
-I---------------------------------------------------
-I- Subnet: IPv4 PKey:0x7fff QKey:0x00000b1b MTU:2048Byte rate:10Gbps SL:0x00
-W- Suboptimal rate for group. Lowest member rate:40Gbps > group-rate:10Gbps
-I---------------------------------------------------
-I- Bad Links Info
-I- No bad link were found
-I---------------------------------------------------
----------------------------------------------------------------
-I- Stages Status Report:
STAGE Errors Warnings
Bad GUIDs/LIDs Check 0 0
Link State Active Check 0 0
General Devices Info Report 0 0
Performance Counters Report 0 0
Partitions Check 0 0
IPoIB Subnets Check 0 1
Please see /var/cache/ibutils/ibdiagnet.log for complete log
----------------------------------------------------------------
-I- Done. Run time was 0 seconds.
Um den IPoB Subnets Check zu beheben erstellen / editieren wir folgende Datei
nano /etc/opensm/partitions.confUnd fügen folgende Zeile ein :
Default=0x7fff, ipoib, mtu=5, rate=7, defmember=full : ALL=full, ALL_SWITCHES=full,SELF=full;Nun sieht die Ausgabe von ibdiagnet so aus
Loading IBDIAGNET from: /usr/lib/x86_64-linux-gnu/ibdiagnet1.5.7
-W- Topology file is not specified.
Reports regarding cluster links will use direct routes.
Loading IBDM from: /usr/lib/x86_64-linux-gnu/ibdm1.5.7
-W- A few ports of local device are up.
Since port-num was not specified (-p option), port 1 of device 1 will be
used as the local port.
-I- Discovering ... 3 nodes (1 Switches & 2 CA-s) discovered.
-I---------------------------------------------------
-I- Bad Guids/LIDs Info
-I---------------------------------------------------
-I- No bad Guids were found
-I---------------------------------------------------
-I- Links With Logical State = INIT
-I---------------------------------------------------
-I- No bad Links (with logical state = INIT) were found
-I---------------------------------------------------
-I- General Device Info
-I---------------------------------------------------
-I---------------------------------------------------
-I- PM Counters Info
-I---------------------------------------------------
-I- No illegal PM counters values were found
-I---------------------------------------------------
-I- Fabric Partitions Report (see ibdiagnet.pkey for a full hosts list)
-I---------------------------------------------------
-I- PKey:0x7fff Hosts:4 full:4 limited:0
-I---------------------------------------------------
-I- IPoIB Subnets Check
-I---------------------------------------------------
-I- Subnet: IPv4 PKey:0x7fff QKey:0x00000b1b MTU:4096Byte rate:40Gbps SL:0x00
-I---------------------------------------------------
-I- Bad Links Info
-I- No bad link were found
-I---------------------------------------------------
----------------------------------------------------------------
-I- Stages Status Report:
STAGE Errors Warnings
Bad GUIDs/LIDs Check 0 0
Link State Active Check 0 0
General Devices Info Report 0 0
Performance Counters Report 0 0
Partitions Check 0 0
IPoIB Subnets Check 0 0
Please see /var/cache/ibutils/ibdiagnet.log for complete log
----------------------------------------------------------------
-I- Done. Run time was 0 seconds.
Fertig.
Test der Geschwindigkeit
Mittels iperf testen wir die Kopiergeschwindigkeit im Netzwerk
Wir haben hier in unserem beispiel zwei IP-Adressen
172.30.128.75
172.30.128.76
wir brauchen dazu zwei SSH Terminalsitzungen.
Einmal auf Server A und auf Server B
in der einen starten wir den iperf Server (der mit der 75)
iperf -sund in dem anderen (der mit 76) den client zum verbinden
Der Parameter -t geben an wie lange der Test laufen soll. Hier 20 Sekunden
Der Parameter -c gibt die IP Adressen des iperf Servers an
iperf -t 20 -c 172.30.128.75
------------------------------------------------------------
Client connecting to 172.30.128.75, TCP port 5001
TCP window size: 2.50 MByte (default)
------------------------------------------------------------
[ 3] local 172.30.128.75 port 54800 connected with 172.30.128.75 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0000-20.0000 sec 125 GBytes 53.5 Gbits/secInfiniband Mode IB/EN ändern
Beschreibung:
Infiniband Karten haben zwei Modi IB und EN.
Diese können mit den Originaltreibern, also nicht out of the box Treibern geändert werden.
Wir installieren hier eine KVM VM mit Debian, schleifen die Karte durch und ändern dann den mode.
Vorraussetzung:
Eeine Umgebung die Hardware in eine VM durchschleifen kann und eine Debian VM.
Sollte das nicht möglich sein, dann Bare Metal auf einer einzelnen kleinen Festplatte Debian installieren.
Für Mellanox Karten 4 Debian Bullseye
Für Mellanox Karten 3 Debian Buster
Installation der Treiber
Per SSH Einloggen mit root.
Treiber gibts hier: https://network.nvidia.com/products/infiniband-drivers/linux/mlnx_ofed/
Installation Mellanox 3 Karten Debian Buster
Dann die EULA Akzeptieren , downloaden.
Dann im Firefox Downloadfentser die URL kopieren und dann per wget einfügen.
Ich habe den link schon mal gepostet. Ist dann alerrdings die Version zur Erstellung des Artikels.
Dann per wget die Treiber downloaden und entpacken im Home Verzeichnis
wget https://content.mellanox.com/ofed/MLNX_OFED-4.9-6.0.6.0/MLNX_OFED_LINUX-4.9-6.0.6.0-debian10.0-x86_64.tgz
tar -xf MLNX_OFED_LINUX-4.9-6.0.6.0-debian10.0-x86_64.tgzDa die Treiber für Bullsee 10.0 sind, müssen wir in der Textdatei die Debian Datei anpassen
nano /etc/debian_versionDort dann auf Debian 10.0 abändern
cd MLNX_OFED_LINUX-4.9-6.0.6.0-debian10.0-x86_64/
./mlnxofedinstallAusgabe, mi Y bestätigen und Dann wird eine Batterie an Paketen installiert
Do you want to continue?[y/N]:y
Checking SW Requirements...
One or more required packages for installing MLNX_OFED_LINUX are missing.
/lib/modules/5.10.0-23-amd64/build/scripts is required for the Installation.
Attempting to install the following missing packages:
libgfortran5 graphviz autoconf pkg-config linux-headers-5.10.0-23-amd64 flex automake ethtool make swig libnuma1 autotools-dev libnl-route-3-200 libltdl-dev libnl-3-200 quilt python3-distutils tcl m4 chrpath libc6-dev libnl-3-dev libnl-route-3-dev debhelper dkms dpatch gfortran bison gcc tk
Removing old packages...
Installing new packages
Installing ofed-scripts-5.8...
Installing mlnx-tools-5.2.0...
Installing mlnx-ofed-kernel-utils-5.8...
Installing mlnx-ofed-kernel-dkms-5.8...
Installing iser-dkms-5.8...
Installing isert-dkms-5.8...
Installing srp-dkms-5.8...
Installing rdma-core-58mlnx43...
Installing libibverbs1-58mlnx43...
Installing ibverbs-utils-58mlnx43...
Installing ibverbs-providers-58mlnx43...
Installing libibverbs-dev-58mlnx43...
Installing libibverbs1-dbg-58mlnx43...
Installing libibumad3-58mlnx43...
Installing libibumad-dev-58mlnx43...
Installing ibacm-58mlnx43...
Installing librdmacm1-58mlnx43...
Installing rdmacm-utils-58mlnx43...
Installing librdmacm-dev-58mlnx43...
Installing mstflint-4.16.1...
Installing ibdump-6.0.0...
Installing libibmad5-58mlnx43...
Installing libibmad-dev-58mlnx43...
Installing libopensm-5.13.0.MLNX20221016.10d3954...
Installing opensm-5.13.0.MLNX20221016.10d3954...
Installing opensm-doc-5.13.0.MLNX20221016.10d3954...
Installing libopensm-devel-5.13.0.MLNX20221016.10d3954...
Installing libibnetdisc5-58mlnx43...
...Ausgabe Installation beendet.
Falls wir eine Firmware flashen müssen, sollten wir uns die PSID notieren
Initializing...
Attempting to perform Firmware update...
Querying Mellanox devices firmware ...
Device #1:
----------
Device Type: ConnectX3
Part Number: MCX354A-FCB_A2-A5
Description: ConnectX-3 VPI adapter card; dual-port QSFP; FDR IB (56Gb/s) and 40GigE; PCIe3.0 x8 8GT/s; RoHS R6
PSID: MT_1090120019
PCI Device Name: 00:10.0
Port1 MAC: f45214990bb1
Port2 MAC: f45214990bb2
Versions: Current Available
FW 2.11.1308 2.42.5000
PXE N/A 3.4.0752
Status: Update required
---------
Found 1 device(s) requiring firmware update...
Device #1: Updating FW ...
Done
Restart needed for updates to take effect.
Log File: /tmp/cL0XrUvJzc
Real log file: /tmp/MLNX_OFED_LINUX.515.logs/fw_update.log
Device (00:10.0):
00:10.0 Network controller: Mellanox Technologies MT27500 Family [ConnectX-3]
Link Width: x8
PCI Link Speed: 8GT/s
Installation passed successfully
To load the new driver, run:
/etc/init.d/openibd restart
Installation Mellanox 4 Karten Debian Bullseye
Dann die EULA Akzeptieren , downloaden.
Dann im Firefox Downloadfentser die URL kopieren und dann per wget einfügen.
Ich habe den link schon mal gepostet. Ist dann alerrdings die Version zur Erstellung des Artikels.
Dann per wget die Treiber downloaden und entpacken im Home Verzeichnis
wget https://content.mellanox.com/ofed/MLNX_OFED-5.8-2.0.3.0/MLNX_OFED_LINUX-5.8-2.0.3.0-debian11.3-x86_64.tgz
tar -xf MLNX_OFED_LINUX-5.8-2.0.3.0-debian11.3-x86_64.tgzDa die Treiber für Bullsee 11.3 sind, müssen wir in der Textdatei die Debian Datei anpassen
nano /etc/debian_versionDort dann auf Debian 11.3 abändern
Nun in das Verzeichnis gehen und Treiber installieren
cd MLNX_OFED_LINUX-5.8-2.0.3.0-debian11.3-x86_64/
./mlnxofedinstall --skip-unsupported-devices-checkAusgabe, mi Y bestätigen und Dann wird eine Batterie an Paketen installiert
Do you want to continue?[y/N]:y
Checking SW Requirements...
One or more required packages for installing MLNX_OFED_LINUX are missing.
/lib/modules/5.10.0-23-amd64/build/scripts is required for the Installation.
Attempting to install the following missing packages:
libgfortran5 graphviz autoconf pkg-config linux-headers-5.10.0-23-amd64 flex automake ethtool make swig libnuma1 autotools-dev libnl-route-3-200 libltdl-dev libnl-3-200 quilt python3-distutils tcl m4 chrpath libc6-dev libnl-3-dev libnl-route-3-dev debhelper dkms dpatch gfortran bison gcc tk
Removing old packages...
Installing new packages
Installing ofed-scripts-5.8...
Installing mlnx-tools-5.2.0...
Installing mlnx-ofed-kernel-utils-5.8...
Installing mlnx-ofed-kernel-dkms-5.8...
Installing iser-dkms-5.8...
Installing isert-dkms-5.8...
Installing srp-dkms-5.8...
Installing rdma-core-58mlnx43...
Installing libibverbs1-58mlnx43...
Installing ibverbs-utils-58mlnx43...
Installing ibverbs-providers-58mlnx43...
Installing libibverbs-dev-58mlnx43...
Installing libibverbs1-dbg-58mlnx43...
Installing libibumad3-58mlnx43...
Installing libibumad-dev-58mlnx43...
Installing ibacm-58mlnx43...
Installing librdmacm1-58mlnx43...
Installing rdmacm-utils-58mlnx43...
Installing librdmacm-dev-58mlnx43...
Installing mstflint-4.16.1...
Installing ibdump-6.0.0...
Installing libibmad5-58mlnx43...
Installing libibmad-dev-58mlnx43...
Installing libopensm-5.13.0.MLNX20221016.10d3954...
Installing opensm-5.13.0.MLNX20221016.10d3954...
Installing opensm-doc-5.13.0.MLNX20221016.10d3954...
Installing libopensm-devel-5.13.0.MLNX20221016.10d3954...
Installing libibnetdisc5-58mlnx43...
...Ändern des Modes IB/EN
Karte anzeigen lassen
mst start
mst statusAusgabe:
ST modules:
------------
MST PCI module loaded
MST PCI configuration module loaded
MST devices:
------------
/dev/mst/mt4099_pciconf0 - PCI configuration cycles access.
domain:bus:dev.fn=0000:00:10.0 addr.reg=88 data.reg=92 cr_bar.gw_offset=-1
Chip revision is: 01
/dev/mst/mt4099_pci_cr0 - PCI direct access.
domain:bus:dev.fn=0000:00:10.0 bar=0xfea00000 size=0x100000
Chip revision is: 01
Unsere karte ist die /dev/mst/mt4099_pciconf0
Nun den aktuellen Modi ausgeben
mlxburn -d /dev/mst/mt4099_pciconf0 -queryAusgabe:
Modi Ändern:
Ersetzen Sie mt4099_pciconf0 mit dem Namen Ihres Geräts. Der Wert 2 setzt den Modus auf InfiniBand. Der Wert 1 würde den Modus auf Ethernet setzen.
mlxconfig -d /dev/mst/mt4099_pciconf0 set LINK_TYPE_P1=2 LINK_TYPE_P2=2Sollte folgender Fehler kommen, dann muss ide Karte mit einer neuen Firmware versehen werden.
-E- Device doesn't support LINK_TYPE_P1 configuration
Firmware Update
Dazu auf https://network.nvidia.com/support/firmware/firmware-downloads/
Dort seine Karte raussuchen und dort dann drauf klicken, ob Infiband oder Entehrnetfirmware.
In unserem Beispiel nehem Ich Infiniband, da ich ein Infinibandswitch habe.

Dann auf eure Karte mit-FCBT klicken. Ich habe eine MCX354A-Karte
Denn die Karten haben verschiedene Geschwindigkiten, wir wollen volle Pulle.
MCX354A-QCBT = 10 Gbit Ethernet // 40 Gbit Infiniband
MCX354A-FCBT = 40 Gbit Ethernet // 56 Gbit Infiniband
Dann die Datei herunterladen
Und dann wieder die URL in die zwischenablage kopieren für WGET
Vorher aber noch unzip installieren
apt install unzip
wget https://content.mellanox.com/firmware/fw-ConnectX3-rel-2_42_5000-MCX354A-FCB_A2-A5-FlexBoot-3.4.752.bin.zipDie Karte herausbekommen,
mst start
mst statusAusgabe
MST modules:
------------
MST PCI module loaded
MST PCI configuration module loaded
MST devices:
------------
/dev/mst/mt4099_pciconf0 - PCI configuration cycles access.
domain:bus:dev.fn=0000:00:10.0 addr.reg=88 data.reg=92 cr_bar.gw_offset=-1
Chip revision is: 01
/dev/mst/mt4099_pci_cr0 - PCI direct access.
domain:bus:dev.fn=0000:00:10.0 bar=0xfea00000 size=0x100000
Chip revision is: 01
Nun haben wir das Gerät /dev/mst/mt4099_pciconf0 und /dev/mst/mt4099_pci_cr0
nun die Firmware ermitteln
flint -d /dev/mst/mt4099_pciconf0 queryAusgabe:
Image type: FS2
FW Version: 2.42.5000
FW Version(Running): 2.11.1308
FW Release Date: 5.9.2017
Product Version: 02.42.50.00
Rom Info: type=PXE version=3.4.752
Device ID: 4099
Description: Node Port1 Port2 Sys image
GUIDs: f45214030098ff20 f45214030098ff21 f45214030098ff22 f45214030098ff23
MACs: f4521498ff21 f4521498ff22
VSD:
PSID: MT_1090120019
root@mellanoxflash:~/MLNX_OFED_LINUX-4.Nun die eigentliche Firmware flashen dazu das device /dev/mst/mt4099_pci_cr0 angeben.
-allow_psid_change ändert die PSID falls Eure Karte nicht die gleiche wie die Firmware hat.
flint -d /dev/mst/mt4099_pci_cr0 -i fw-ConnectX3-rel-2_42_5000-MCX354A-FCB_A2-A5-FlexBoot-3.4.752.bin -allow_psid_change burnProxmox - Upgrade Fehler
Fehler : pve-firmware : Kollidiert mit: firmware-linux-free aber 20200122-1 soll installiert werden
Beschreibung:
Beim
apt get upgradeerhalten wir folgenden Fehler:
Die folgenden Pakete haben unerfüllte Abhängigkeiten:
pve-firmware : Kollidiert mit: firmware-linux-free aber 20200122-1 soll installiert werden
E: Beschädigte Pakete
Lösung:
Es sieht danach aus als wenn noch ein Stock Kernel image installiert ist.
Mit folgendem Befehl lassen sich alle installierten Kernel auflisten
dpkg --list | grep linux-imageAusgabe:
rc linux-image-4.19.0-10-amd64 4.19.132-1 amd64 Linux 4.19 for 64-bit PCs (signed)
rc linux-image-4.19.0-12-amd64 4.19.152-1 amd64 Linux 4.19 for 64-bit PCs (signed)
rc linux-image-4.19.0-13-amd64 4.19.160-2 amd64 Linux 4.19 for 64-bit PCs (signed)
ii linux-image-4.19.0-14-amd64 4.19.171-2 amd64 Linux 4.19 for 64-bit PCs (signed)
ii linux-image-4.19.0-21-amd64 4.19.249-2 amd64 Linux 4.19 for 64-bit PCs (signed)
ii linux-image-5.10.0-18-amd64 5.10.140-1 amd64 Linux 5.10 for 64-bit PCs (signed)
ii linux-image-5.10.0-20-amd64 5.10.158-2 amd64 Linux 5.10 for 64-bit PCs (signed)
ii linux-image-amd64 5.10.158-2 amd64 Linux for 64-bit PCs (meta-package)Alle die im am Anfang ii stehen haben deinstallieren.
apt remove linux-image-4.19.0-14-amd64 linux-image-4.19.0-21-amd64 linux-image-5.10.0-18-amd64 linux-image-5.10.0-20-amd64 linux-image-amd64 Dann das upgrade noch mal starten und läuft
VDI mit Spice
Vorebereitung in Proxmox
Beschreibung:
Damit VDI in Proxmox funktioniert müssen dem entsprechend die VM und User angelegt werden.
Denn jeder darf ja nur seine VDI benutzen.
Proxmox User; Gruppen Rollen:
Als Erstes legen wir eine Rolle an mit dem Namen VDIClients
Dazu melden wir uns am proxmox an, gehen unter Datacenter -> Permission -> Roles und klciken dort auf Create
Nun vergeben wir den Namen und wählen die Rollen aus:
Name: VDIClients
Rollen: VM.Console, VM.PowerMgmt, VM.Audit
und klicken auf Create
Nun kann man sich überlegen ob man eine Gruppe erstellen will, wo die Benutzer rein kommen, oder Einzelne Benutzer.
Sollen mehrere Benutzer eine oder mehrer VMS Benutzen, macht ne Gruppe Sinn.
Soll jeder nur seine eigene Maschine benutzen, machen tatsächlich nur Benutzer Sinn.
Das verfahren ist bei allen Gleich entweder an die Maschine wird gleich nur ein Benutzer oder eine Gruppe Hin zugewiesen.
Gruppen werden unter Permission Gruppen angelgt und dort die Benutzer hinzugewiesen und Benutzer werden unter Permissions Users hinzugefügt
Wenn Gruppen gewünscht sind, erst die Gruppe erstellen dann die Benutzer.
Einen Benutzer hinzufügen:
Unter Datacenter -> Permission -> Users auf Create klicken.
Wichtig das als Realm Proxmox VE ausgewählt und NICHT PAM.
Dann Benutzername ausfüllen Passwort,
Gruppe nur auswählen, wenn auch eine genutzt werden soll die vorher erstellt wurde, sonst leer lassen.
Ein Kommentar reinschreiben z.b Vorname Nachname.
Dann den Vornamen, Nachname Emailadresse ausfüllen und Auf create klicken.
Nun haben wir den Benutzer in unserer Liste.
Die VM Vorbereiten
Wir haben unsere VM schon fertig installiert, wenn noch nicht dann eine aufsetzten.
Nachdem diese aufgesetzt ist muss ide Grafikkarte auf Spice umgestellt werden.
Dort wählen wir spice aus und wie viele Monitore am Client dranhängen wenn Multimonitor gewünscht ist.
bei einem Monitor einfach Spice auswählen, ansonsten mit der Anzahl der Monitore.
Es können bis zu 4 Monitore angesprochen werden.
Den Speicher stellen wir auf 128MB ein.
Da ich zwei Monitore betreibe hab ich zwei ausgewählt.
Danach muss die Maschine gestoppt und neu gestartet werden(soft neustart reicht nicht, also Kalt start)
Sollet man noch an den Spice Erweiterungen im nächsten schritt was ändern kann man sich das Stoppen sparen, denn da muss die Maschine auch gestoptt gestartet werden.

Unter optionen der VM kann man noch Spice erweiterungen Einstellen z.b Verzeichnis Teilen (wie bei Vritualbox oder RDP) und welcher filter eingestellt werden soll, falls Video Streaming betrieben wird.
Den filter hab ich auf all gestellt.
Auch hier muss die Maschine gestoppt und neu gestartet werden(soft neustart reicht nicht, also Kalt start)
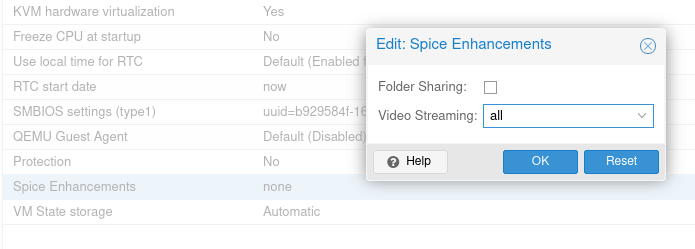
Falls Folder Sharing eingeschaltet ist, stelle sicher, dass der WebDAV-Dienst in deinem Gastsystem aktiviert und in Betrieb ist. Unter Windows wird er als Spice WebDAV-Proxy bezeichnet. Unter Linux heißt er spice-webdavd, kann aber je nach Distribution unterschiedlich sein.
Wenn der Dienst läuft, überprüfe den WebDAV-Server, indem du http://localhost:9843 in einem Browser in deinem Gastsystem öffnest. Die installation dazu findest u in diesem Kapitel.
Nun zum Schluss weisen wir den Benutzer der VM zu

Nun wählen wir unseren User aus und die VDIClients Role klicken auf add, fertig.
Proxmox vorbereitung ist damit abgeschlossen.
VDI Client unter Windows einrichten
Beschreibung:
Spice ist eingerichtet, die Benutzer sind angelegt, Jetzt kann der VDI CLient auf dem Client installiert werden.
Hier für Windows
Installation:
Den Spice wird Manager installieren.
Dazu auf : https://virt-manager.org/download.html gehen Dort unter Virt Viewer sind die Downloads ein bisschen versteckt.
Für x86 Windows und x64 Windows, da wir Windows 10 als Client haben nehmen wir Winx64
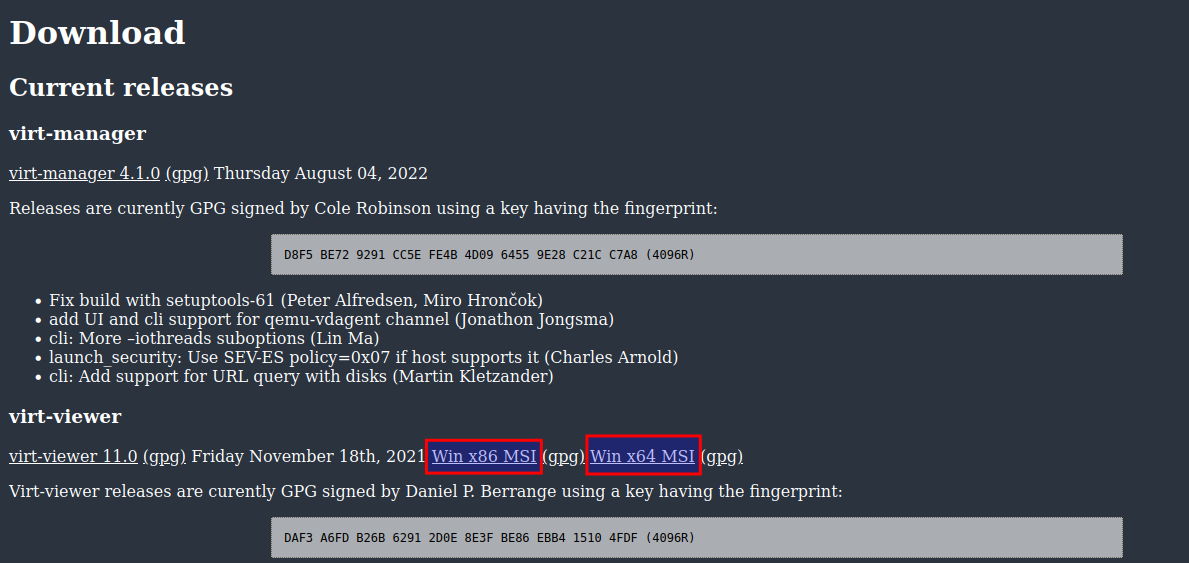
Nach dem wir den virt-viewer installiert haben. brauchen wir den VDI Client, den bekommen wir unter
https://github.com/joshpatten/PVE-VDIClient/releases
Dort die MSI Downloaden und installieren.
Google Chrome blockt die Datei. Mit Edge runterladen

Nun Einfach den Wizzard durchklicken
Akzeptieren und weiter
Alles bei Standard lassen und weiter

Auf installieren und dann ja anklciken
Fertig
Die Client INI anpassen.
Der PVE VDI Client benötigt eine vdiclient.ini. Er sucht automatisch nach der Datei in:
c:\users\<deinbenutzername>\AppData\Roaming\VDIClient\vdiclient.ini
oder mann kann diese in der Verknüpfung auch als Paramter übergeben mit --config
"C:\Program Files\VDIClient\vdiclient.exe" --config .\vdiclient.ini # ini im aktuellen Verzeichnis
Hier gibts ein Beispiel was alles eingestellt werden kann:
https://github.com/joshpatten/PVE-VDIClient/blob/main/vdiclient.ini.example
Hier eine Minimalistische Config:
[General]
#Hier kann man einen Title einstellen
title = VDI Login
#Das Theme wählen
theme = LightBlue
#icons und Logo lass ich besi standard
icon = vdiicon.ico
logo = vdiclient.png
kiosk = False
inidebug = False
[Authentication]
#das backend ist pve nicht pam
auth_backend = pve
#wer zwei wege auth hat muss das aktivieren also auf treu stellen
auth_totp = false
#da ich kein lets encrypt zert habe, auf false, wer ein richtig gültiges Cert hat, also nicht selbsigniert auf treu stellen
tls_verify = false
#der PVE host mit port
[Hosts]
192.168.178.x = 8006
[AdditionalParameters]
#ich möchte USB Geräte drin nhaben, deshalb usb sharing
# Enable USB passthrough
enable-usbredir = true
# Enable auto USB device sharing
enable-usb-autoshare = trueEinloggen:
Die Verknüpfung starten

Benutzername Kennwort eingeben

Bei der Virtellen Machine die man haben möchte (Hier haben wir nur eine) auf connect klicken
Nun Auf Connect klicken, verbunden